変調エキスパート混合によるマルチモーダル時系列予測
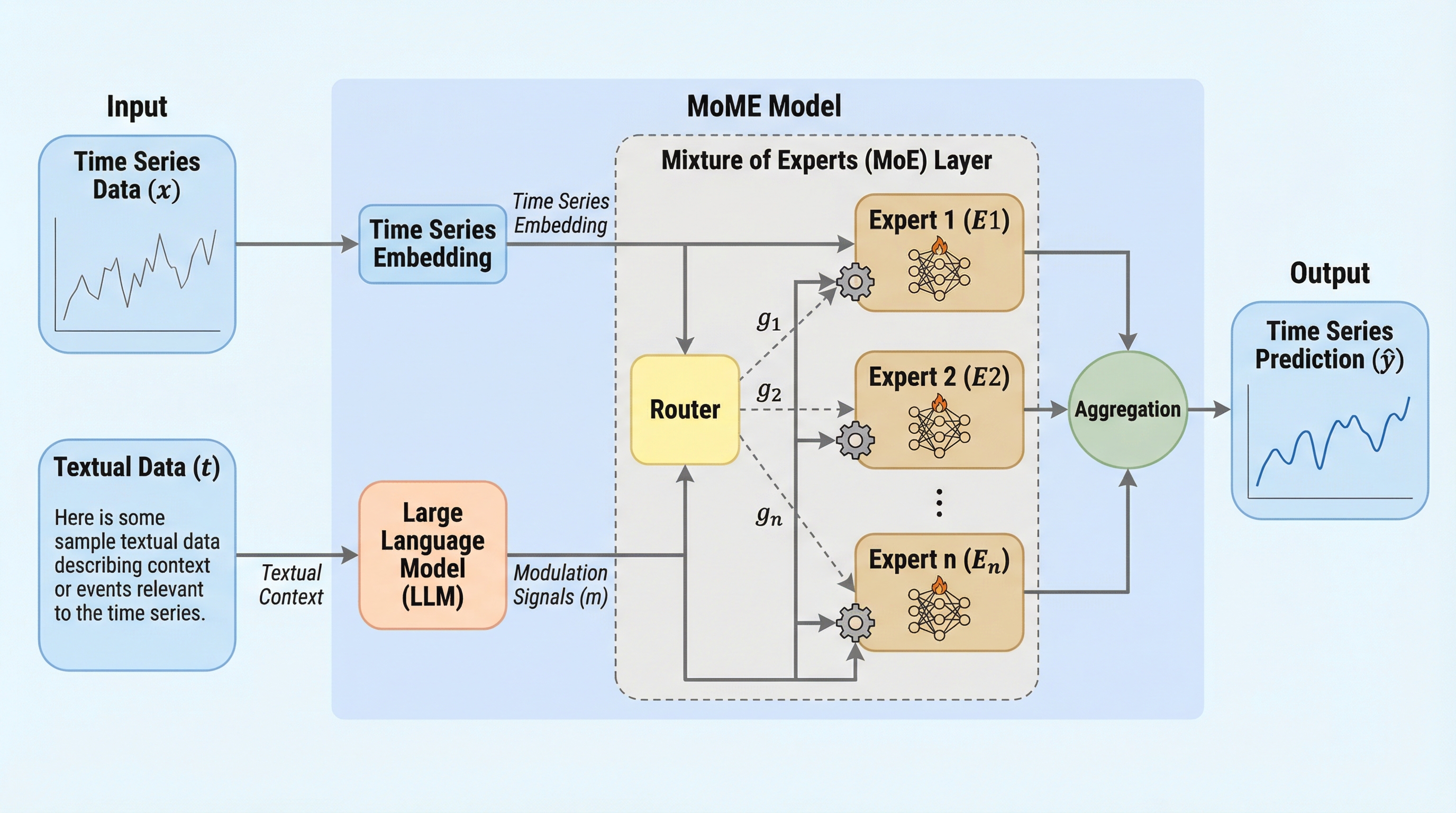
従来のマルチモーダル時系列予測で主流だった、数値データとテキストデータを共通の潜在空間で直接混ぜ合わせる「トークンレベルの融合」に代わり、テキスト情報を用いて時系列エキスパートの計算とルーティングを直接制御する「エキスパート変調(Expert Modulation)」という新しいパラダイムを提案した。
TL;DR(結論)
従来のマルチモーダル時系列予測で主流だった、数値データとテキストデータを共通の潜在空間で直接混ぜ合わせる「トークンレベルの融合」に代わり、テキスト情報を用いて時系列エキスパートの計算とルーティングを直接制御する「エキスパート変調(Expert Modulation)」という新しいパラダイムを提案した。 この手法は、事前学習済みの大規模言語モデル(LLM)から抽出した意味情報を活用し、エキスパートごとのアフィン変換と文脈依存のルーティング調整を行うことで、時系列データとテキストデータの複雑な相互作用を、トークン同士を直接干渉させることなく効率的にモデル化する。 金融や気象などの多様なデータセットを用いた検証において、既存の単一モーダル手法やトークン融合型のマルチモーダル手法を安定して上回る予測精度を達成し、計算複雑性を維持したまま高い柔軟性と性能向上を実現した。
なぜこの問題か
現実世界の時系列データは、複雑かつ進化し続ける動態を持っており、正確な予測を行うことは極めて困難な課題である。エネルギー消費、交通量、気象、金融など、多岐にわたるドメインにおいて時系列予測は重要な役割を果たしているが、従来の統計的手法や深層学習モデルの多くは、過去の数値履歴のみに依存していた。しかし、株価や大気質のように、数値データだけでは将来の変化を十分に捉えきれないシナリオが数多く存在する。このような場合、ニュースレポートなどの外部テキスト情報は、数値履歴には含まれない重要な予測の手がかりを提供するため、マルチモーダル時系列予測(MMTSP)への関心が高まっている。 既存のマルチモーダル手法の多くは、テキストトークンと時系列トークンを共通の潜在空間で混合する「トークンレベルの融合」を採用している。具体的には、時系列のパッチとテキストの埋め込みを結合し、事前学習済みの言語モデルに入力して回帰や分類を行う形式が一般的である。しかし、最近の研究では、このような融合戦略を用いたモデルが、必ずしも単一モーダルのベースラインを安定して上回るわけではないことが指摘されている。…
核心:何を提案したのか
本研究では、外部信号が時系列エキスパートの計算を直接変調する「エキスパート変調(Expert Modulation)」という新しいパラダイムを核とした、Mixture-of-Modulated-Experts(MoME)フレームワークを提案した。これは、表現レベルでモーダルを統合する従来のトークンレベル融合とは異なり、補助的なテキスト情報をエキスパートの機能そのものに注入するアプローチである。このフレームワークは、テキスト信号を用いてルーティング(どのエキスパートを使うか)とエキスパート計算(選ばれたエキスパートがどう動くか)の両方を条件付けることで、クロスモーダルな制御を実現する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related