ShardMemo:シャード化されたエージェント的LLMメモリのためのマスクされたMoEルーティング
ShardMemoは、エージェント型LLMのために設計された階層型メモリサービスであり、作業状態(Tier A)、シャード化された証拠(Tier B)、スキルライブラリ(Tier C)の3層構造によって、大規模なメモリへの効率的なアクセスを実現します。
TL;DR(結論)
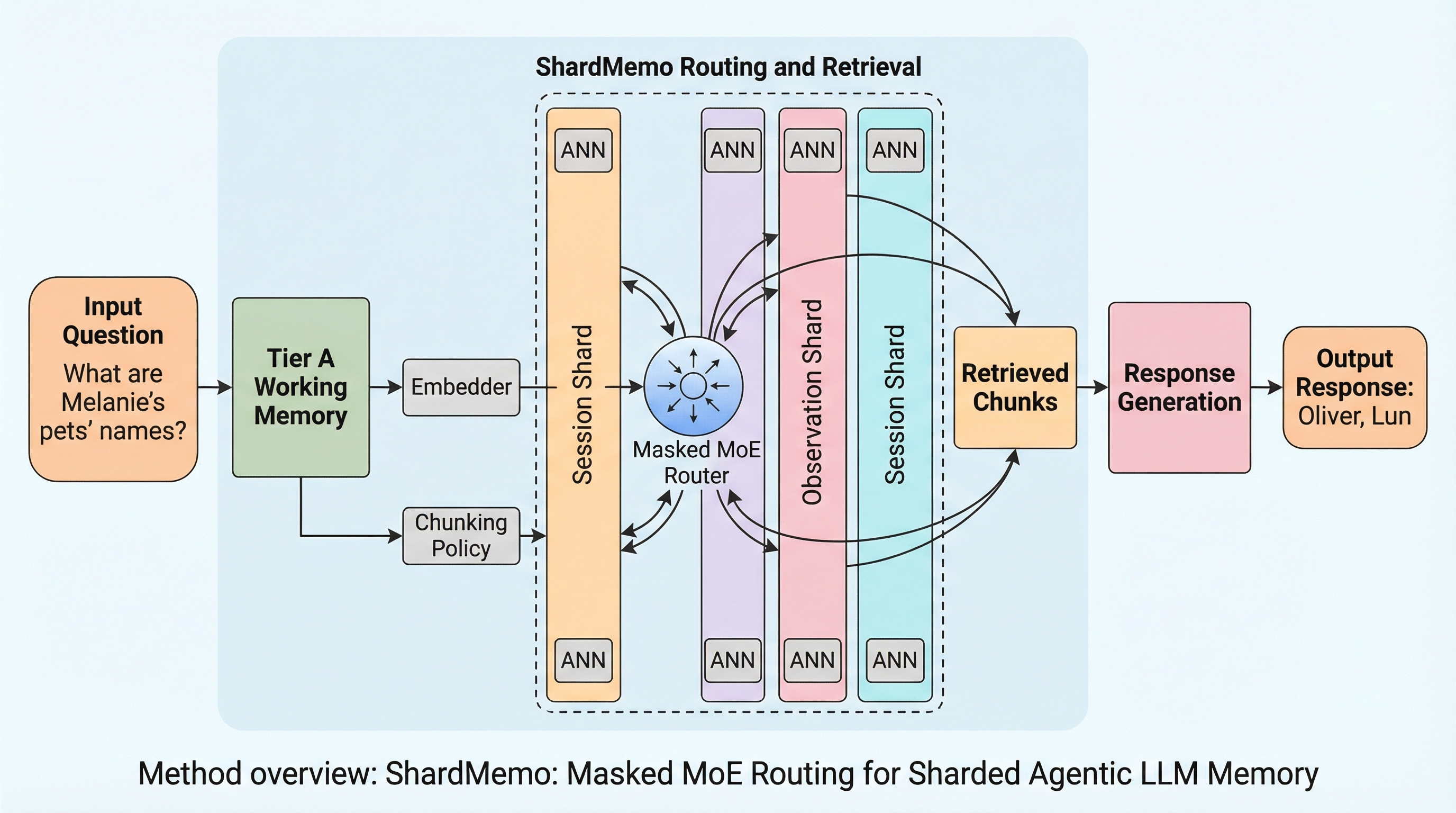
ShardMemoは、エージェント型LLMのために設計された階層型メモリサービスであり、作業状態(Tier A)、シャード化された証拠(Tier B)、スキルライブラリ(Tier C)の3層構造によって、大規模なメモリへの効率的なアクセスを実現します。 Tier Bでは「ルーティング前のスコープ制限」と「マスクされた混合専門家(MoE)ルーティング」を導入することで、構造的な制約を厳密に守りつつ、検索時のベクトルスキャン量を20.5%削減し、テイルレイテンシを95msから76msへと短縮しました。 ベンチマーク評価では、既存の最強のベースラインと比較してF1スコアを最大6.82向上させ、448Kトークンに及ぶ超長文コンテキストや複雑なツール使用タスクにおいても、高い精度と実行効率を両立できることを証明しました。
なぜこの問題か
エージェント型の大規模言語モデル(LLM)システムは、長期的なタスクの実行や複数のエージェントによる並列処理を行うために、外部メモリへの依存度を急速に高めています。これらのシステムは、目標をサブタスクに分解し、ツールの呼び出しと検証を繰り返し、相互作用を通じて経験を蓄積していくため、セッションをまたいで状態を保持する外部メモリが不可欠なコンポーネントとなっています。しかし、デプロイメントの規模が拡大するにつれて、メモリへのアクセスがシステムの大きなボトルネックとなります。具体的には、コーパスのサイズが大きくなるほど検索コストが増大し、共有インデックスに対する同時読み書きが競合を引き起こし、負荷が高まるにつれてテイルレイテンシが悪化するという課題があります。 また、エージェントのワークロードにおけるメモリへのアクセスは、その内容と意図の両面において極めて不均一です。あるリクエストは長期的な対話ログから宣言的な証拠を取得することを目的としていますが、別のリクエストは過去に成功したツールの使用手順を再利用することで恩恵を受けます。…
核心:何を提案したのか
本論文では、エージェント型LLMシステムのために、スコープの正確性と予算内でのアクセスを強制する階層型メモリサービス「ShardMemo」を提案しています。ShardMemoの最大の特徴は、メモリを3つの階層(Tier A、Tier B、Tier C)に分離し、それぞれの層に対してリソース予算を明示的に割り当てるアーキテクチャにあります。Tier Aはエージェントごとの作業状態を保持し、Tier Bはシャード化された証拠メモリを、Tier Cはバージョン管理されたスキルライブラリとして機能します。これにより、リクエストの性質に応じた最適なメモリ層へのアクセスが可能となります。 特にTier Bの証拠メモリにおいては、「ルーティング前のスコープ制限(scope-before-routing)」という新しい概念を導入しています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related