ASTRA:エージェント的軌跡と強化学習アリーナの自動合成
ASTRAは、ツールを利用する言語モデルエージェントの訓練を完全に自動化するエンドツーエンドのフレームワークであり、大規模なデータ合成とルール検証可能な強化学習を統合することで、人間の介入を排除した効率的な学習を実現しました。
TL;DR(結論)
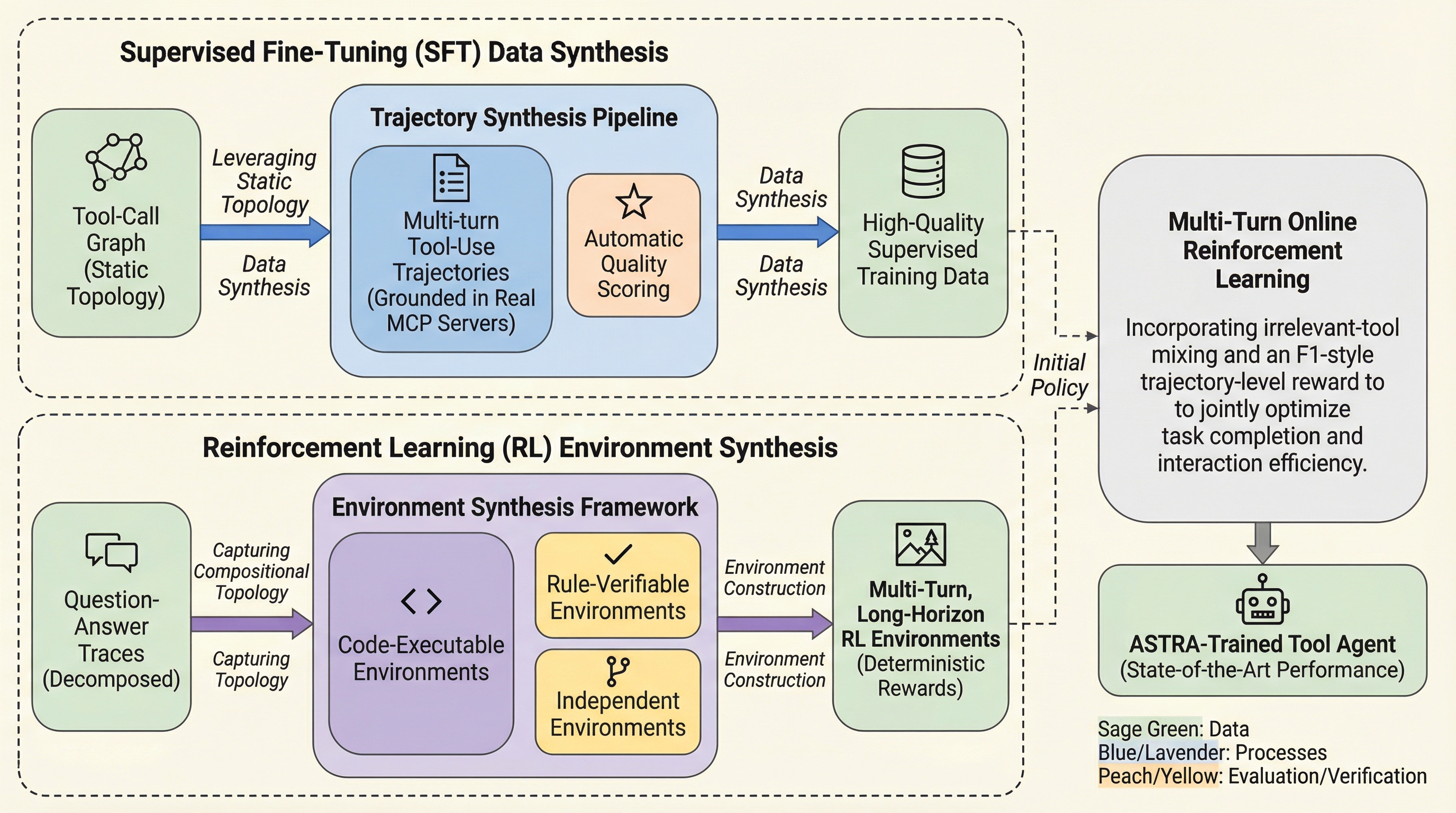
ASTRAは、ツールを利用する言語モデルエージェントの訓練を完全に自動化するエンドツーエンドのフレームワークであり、大規模なデータ合成とルール検証可能な強化学習を統合することで、人間の介入を排除した効率的な学習を実現しました。 このシステムは、ツール呼び出しグラフの静的トポロジから多様な操作軌跡を生成するパイプラインと、人間の意味的推論を分解して実行可能なコード環境へと変換する環境合成フレームワークの二本柱で構成され、広範なツール使用能力と深い推論能力を同時に養います。 教師あり微調整(SFT)とオンライン強化学習(RL)を組み合わせた独自の二段階訓練により、同規模のモデルにおいて世界最高水準の性能を達成し、中核となる推論能力を維持したまま、クローズドソースの商用モデルに匹敵する高度なエージェント能力を獲得しました。
なぜこの問題か
大規模言語モデル(LLM)を外部環境やAPIと相互作用させるツール拡張型エージェントの開発は急速に進んでいますが、堅牢で汎用性の高いエージェントを訓練することには依然として多くの困難が伴います。既存の研究における最大の課題の一つは、訓練データの生成や環境の構築にいまだに多大な人間の介入が必要であり、スケーラビリティが著しく制限されている点にあります。また、モデル駆動型のシミュレーション環境に依存する手法の多くは、ツールの実行結果や状態遷移、フィードバックが明示的なルールや実際の実行バックエンドに基づかず、言語モデルによるシミュレーションによって生成されています。このような「ルール検証不可能性」は、決定論的な遷移と信頼性の高い報酬信号を必要とする、長期的なマルチターンのオンライン強化学習を極めて不安定なものにします。 さらに、既存の手法の多くは、オフラインで生成されたマルチターンの軌跡を単発の学習インスタンスに分解して訓練に利用していますが、これではエージェントが首尾一貫した長期的な意思決定プロセスを学習することができません。…
核心:何を提案したのか
本研究では、大規模なデータ合成と検証可能なマルチターンオンライン強化学習を組み合わせた、ツール拡張型言語モデルエージェントのための完全自動化エンドツーエンドフレームワーク「ASTRA」を提案しました。ASTRAの最大の特徴は、データの構築から検証、そして訓練に至るまでの全工程において人間の介入を一切必要としない点にあります。このフレームワークは、二つの相補的なコンポーネントを中核としています。第一のコンポーネントは、SFTのための「軌跡合成パイプライン」です。これは、ツール呼び出しグラフの静的なトポロジを活用し、実際のMCP(Model Context Protocol)サーバーに基づいた多様で構造的なマルチターンのツール使用軌跡を構築します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related