検索システムフレームワークの分類学:その落とし穴とパラダイム
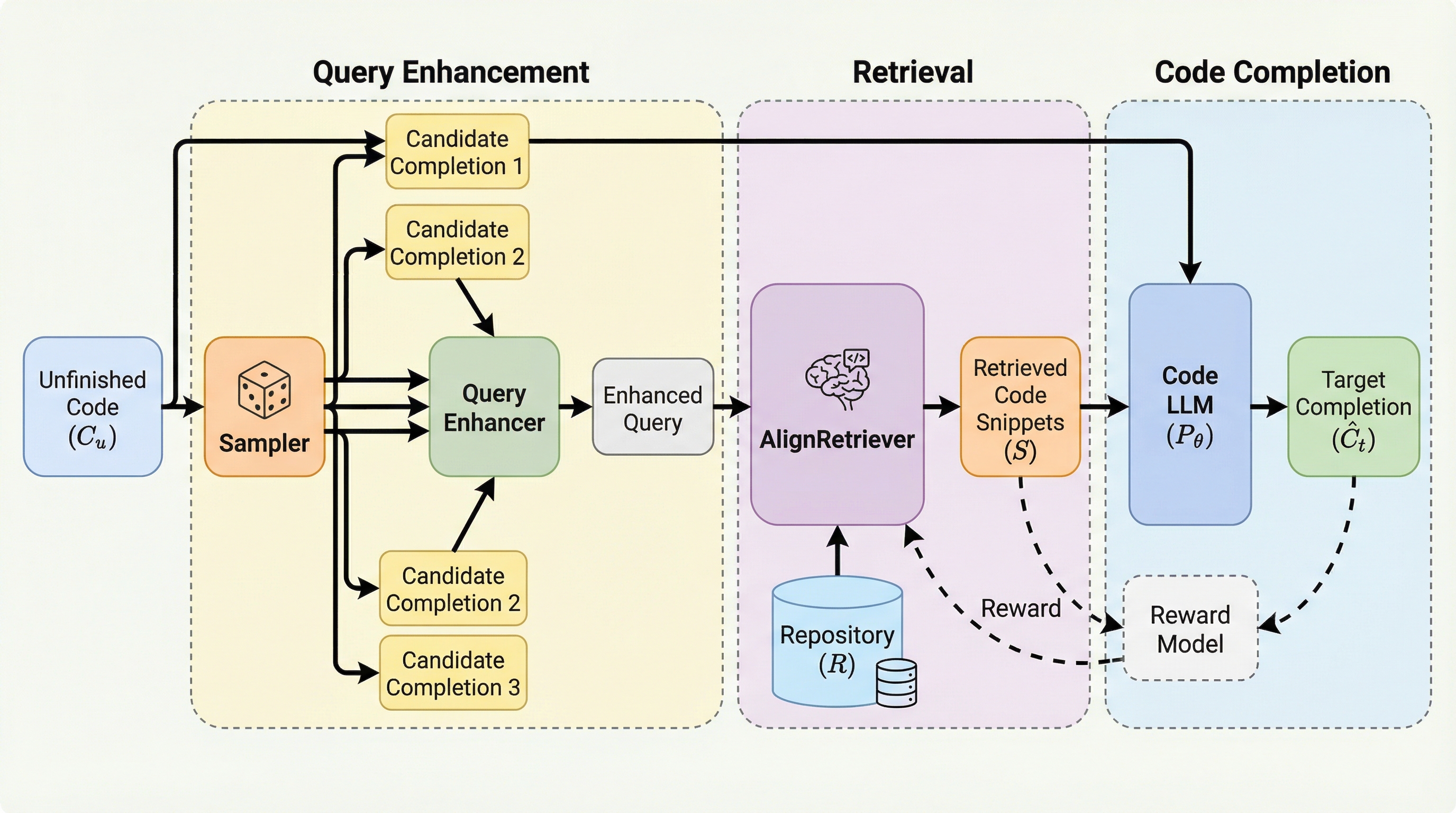
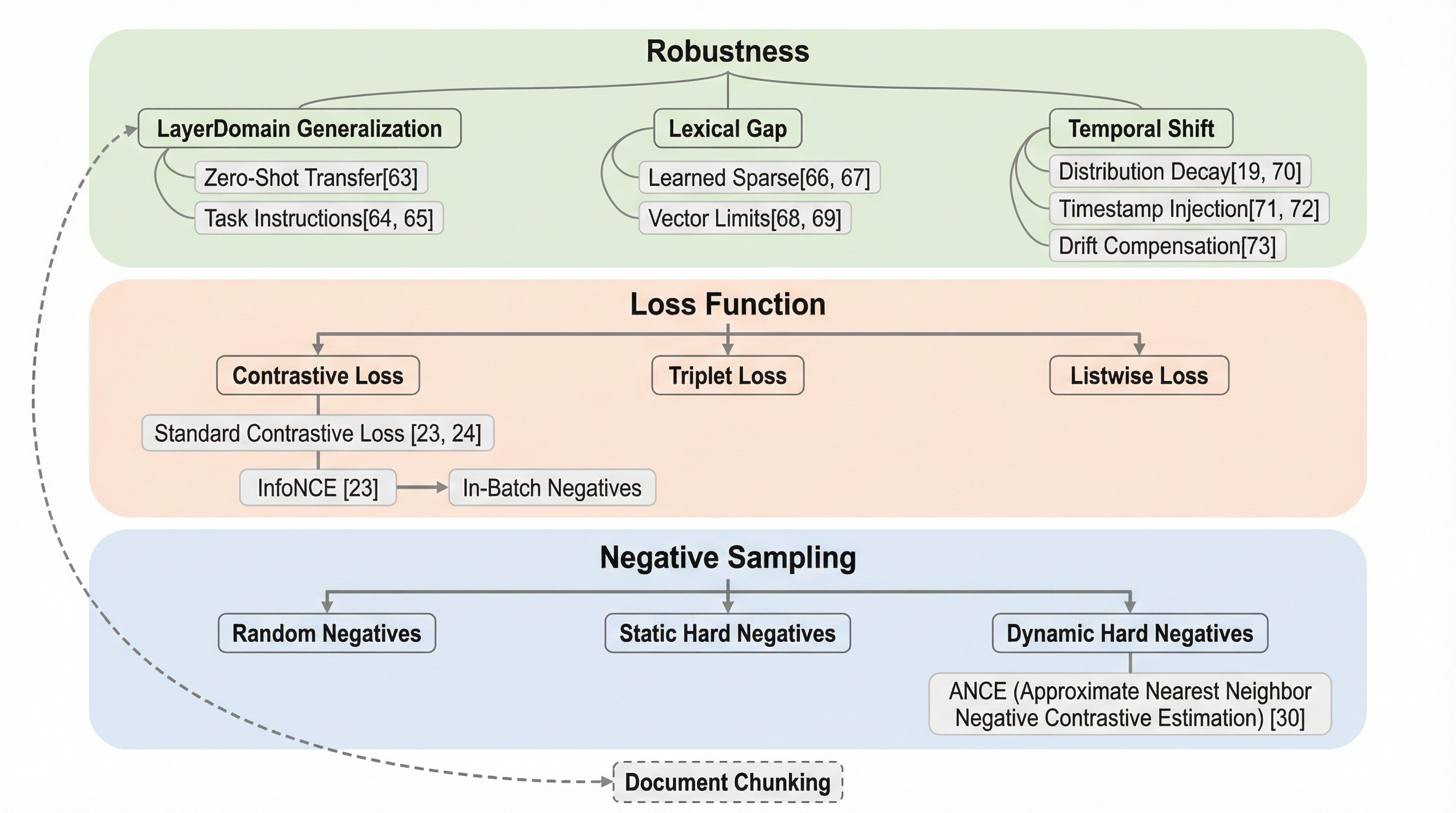
本論文は、埋め込みベースの検索システムにおける効率性と有効性のトレードオフを整理するため、「表現層」「粒度層」「オーケストレーション層」「堅牢性層」の4層からなる新しい分類学を提案している。 Bi-Encoderの高速性とCross-Encoderの高精度を両立させるLate Interactionなどのハイブリッド手法や、ドキュメント分割(チャンキング)が検索精度と生成品質に与える影響を詳細に分析し、システム全体の最適化指針を示している。 さらに、ドメイン一般化の失敗や語彙の死角、時間の経過による情報の陳腐化(時間的ドリフト)といった実運用上の課題を体系化し、タイムスタンプ注入などの具体的なアーキテクチャ上の緩和策を提示している。