AlignCoder:リポジトリレベルのコード補完に向けた検索とターゲット意図のアライメント
既存のコード生成モデルはリポジトリ固有の知識が不足しており、検索拡張生成(RAG)を用いてもクエリとターゲットコードの間に意味的な不一致が生じるという課題がありました。本研究が提案するAlignCoderは、複数の候補生成によってクエリを強化する仕組みと、強化学習を用いた検索モデルの訓練手法を導入することで、検索精度とコード補完の正確性を大幅に向上させます。実験の結果、CrossCodeEvalベンチマークにおいてベースラインを18.1%上回るEMスコアを達成し、多様なプログラミング言語やモデルに対して高い汎用性と優れた性能を持つことが実証されました。
TL;DR(結論)
既存のコード生成モデルはリポジトリ固有の知識が不足しており、検索拡張生成(RAG)を用いてもクエリとターゲットコードの間に意味的な不一致が生じるという課題がありました。本研究が提案するAlignCoderは、複数の候補生成によってクエリを強化する仕組みと、強化学習を用いた検索モデルの訓練手法を導入することで、検索精度とコード補完の正確性を大幅に向上させます。実験の結果、CrossCodeEvalベンチマークにおいてベースラインを18.1%上回るEMスコアを達成し、多様なプログラミング言語やモデルに対して高い汎用性と優れた性能を持つことが実証されました。
なぜこの問題か
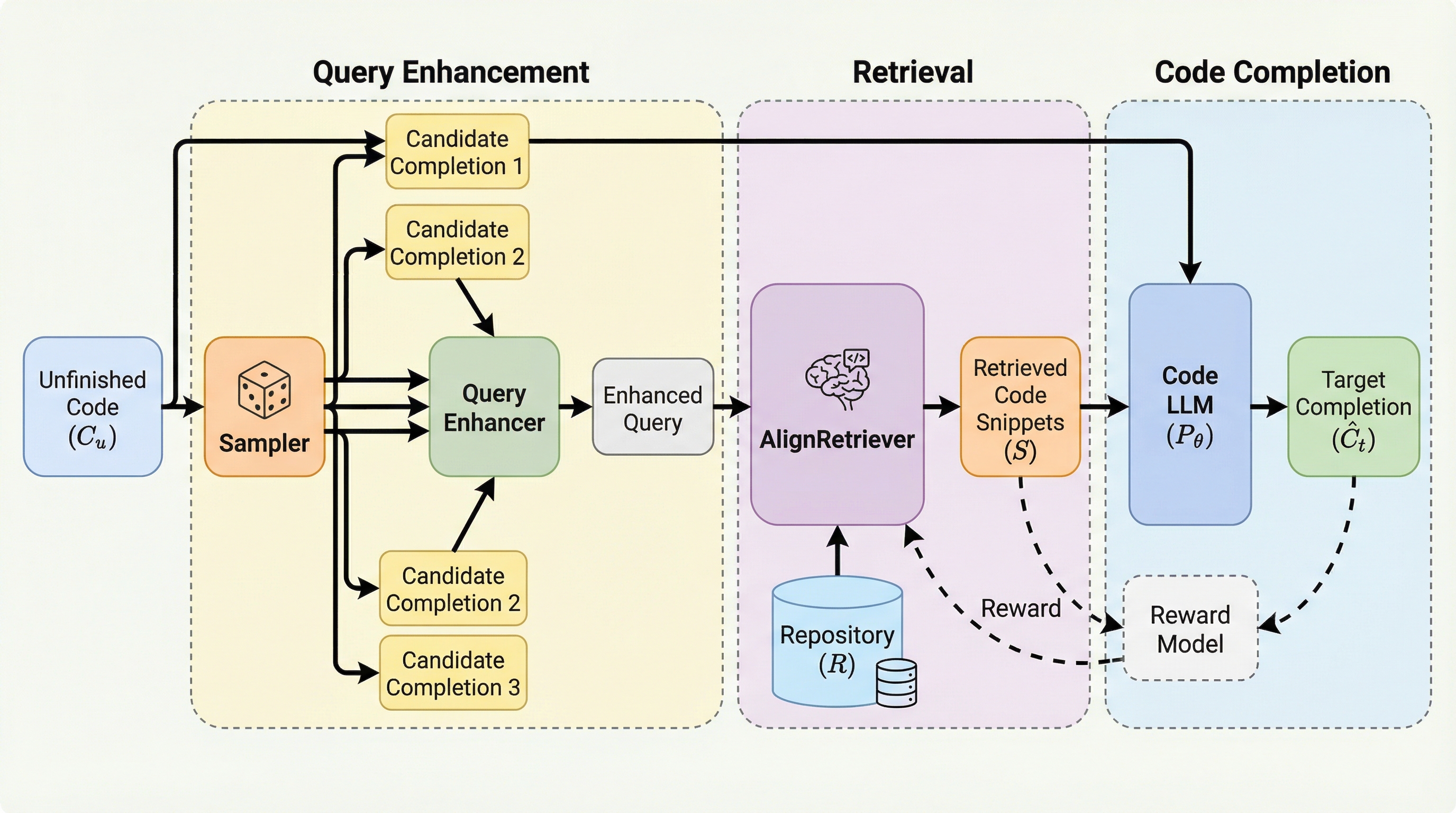
リポジトリレベルのコード補完は、現代のソフトウェア開発において不可欠な要素ですが、既存のコード大規模言語モデル(code LLMs)にとっては依然として非常に困難な課題です。その最大の理由は、モデルがリポジトリ固有の文脈や特定のドメイン知識を十分に理解できていないことにあります。多くの場合、開発対象となるコードリポジトリは新しく作成されたものや、企業独自の非公開プロジェクト、あるいは現在進行中の作業であり、モデルが事前学習や微調整の段階でこれらの情報を習得することは事実上不可能です。この知識の欠如を補うために、リポジトリ内の全ファイルを一つのプロンプトに詰め込む手法も考えられますが、これでは無関係な情報が大量に混入し、モデルの生成能力を著しく阻害するという問題が生じます。 この解決策として、未完成のコードをクエリとして関連するコード断片を検索し、それを文脈として与える検索拡張生成(RAG)が注目されてきました。しかし、従来のRAG手法には二つの根本的な欠陥があります。第一に、検索プロセスにおいてクエリとターゲットコードの間に「意味的な不一致」が生じることです。…
核心:何を提案したのか
本論文では、上述の課題を解決するために、AlignCoderと呼ばれる新しいリポジトリレベルのコード補完フレームワークを提案しています。このフレームワークの核心は、クエリ強化メカニズムと、強化学習に基づいた検索モデル「AlignRetriever」の訓練手法の二点にあります。AlignCoderは、単に未完成のコードを検索に使うのではなく、モデル自身の推論能力を利用してクエリそのものを進化させるというアプローチをとります。 まず、クエリ強化メカニズムにおいては、サンプラーと呼ばれる軽量な言語モデルを用いて、未完成のコードから複数の候補となる補完コードを生成します。これらの候補は必ずしもすべてが正解である必要はありません。複数の異なる可能性を提示することで、その中の少なくとも一つがターゲットコードに関連する重要なトークンや構造を含んでいる確率を高めます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related