検索システムフレームワークの分類学:その落とし穴とパラダイム
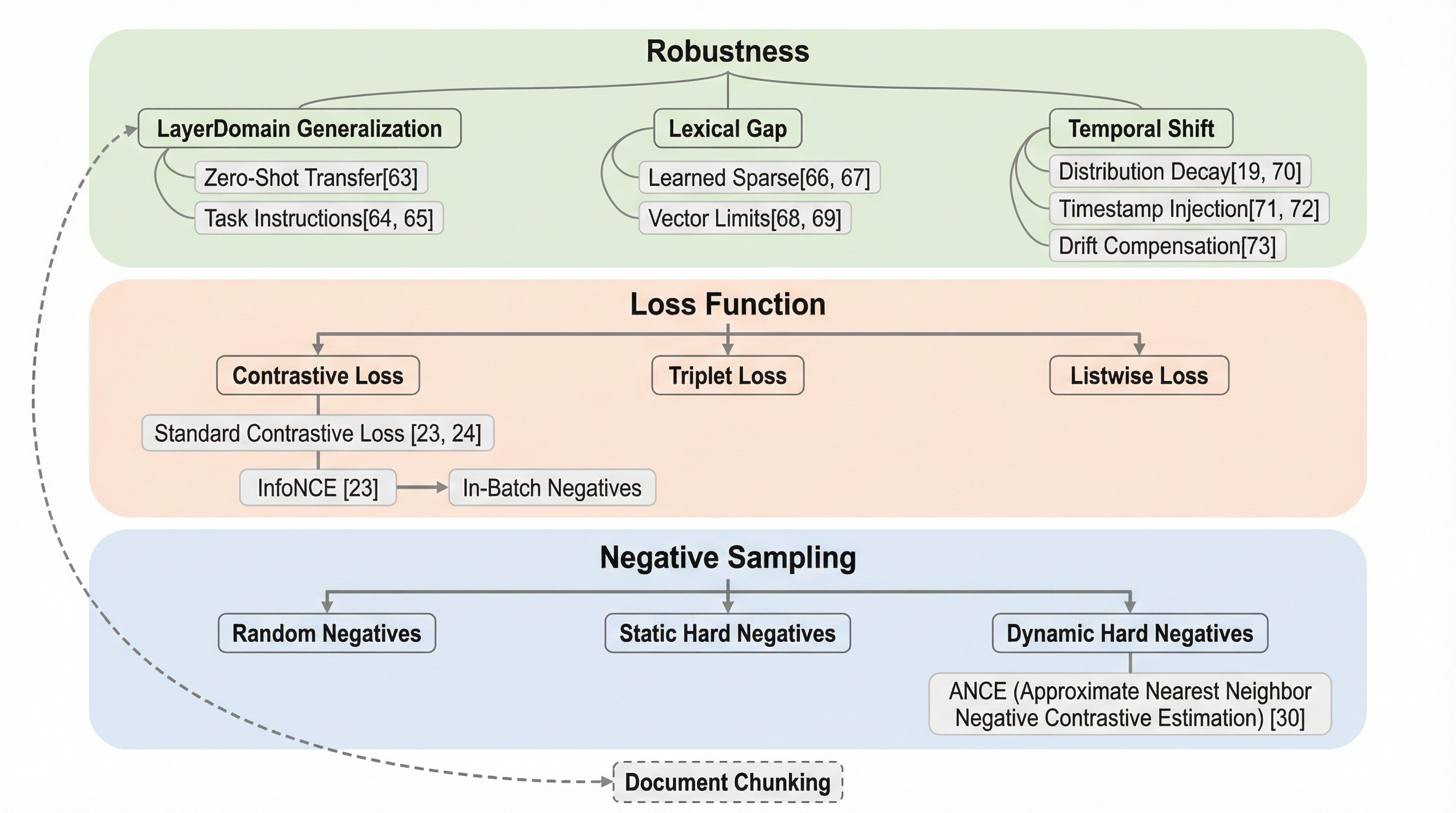
本論文は、埋め込みベースの検索システムにおける効率性と有効性のトレードオフを整理するため、「表現層」「粒度層」「オーケストレーション層」「堅牢性層」の4層からなる新しい分類学を提案している。 Bi-Encoderの高速性とCross-Encoderの高精度を両立させるLate Interactionなどのハイブリッド手法や、ドキュメント分割(チャンキング)が検索精度と生成品質に与える影響を詳細に分析し、システム全体の最適化指針を示している。 さらに、ドメイン一般化の失敗や語彙の死角、時間の経過による情報の陳腐化(時間的ドリフト)といった実運用上の課題を体系化し、タイムスタンプ注入などの具体的なアーキテクチャ上の緩和策を提示している。
TL;DR(結論)
本論文は、埋め込みベースの検索システムにおける効率性と有効性のトレードオフを整理するため、「表現層」「粒度層」「オーケストレーション層」「堅牢性層」の4層からなる新しい分類学を提案している。 Bi-Encoderの高速性とCross-Encoderの高精度を両立させるLate Interactionなどのハイブリッド手法や、ドキュメント分割(チャンキング)が検索精度と生成品質に与える影響を詳細に分析し、システム全体の最適化指針を示している。 さらに、ドメイン一般化の失敗や語彙の死角、時間の経過による情報の陳腐化(時間的ドリフト)といった実運用上の課題を体系化し、タイムスタンプ注入などの具体的なアーキテクチャ上の緩和策を提示している。
なぜこの問題か
情報検索(IR)の分野は、従来の転置インデックスを用いた厳密なキーワード一致から、高次元のベクトル空間を活用した意味的マッチングへと劇的な転換を遂げた。この進化は、事前学習済み言語モデル(PLM)や大規模言語モデル(LLM)の台頭によって加速し、検索の目的は単なる単語の照合ではなく、ユーザーの複雑で暗黙的な意図を汲み取ったコンテンツの特定へと再定義されている。しかし、生成モデル単体ではハルシネーション(事実誤認)や情報の鮮度の問題、学習データのカットオフによる知識の限界といった課題が残っている。これらを解決する手段として検索拡張生成(RAG)が不可欠となっているが、その基盤となる検索システムの設計には高度な専門性が求められる。 現在、高密度検索(Dense Retrieval)は金融、医療、ソフトウェア、法務といった、情報の正確性が極めて重要な専門分野において基盤技術となっている。しかし、実務者は常に「効率性」と「有効性」の間にあるパレート境界をナビゲートしなければならない。…
核心:何を提案したのか
本研究は、埋め込みベースの検索システムにおける設計上の意思決定を、4つの独立しつつも相互に関連する階層に分類する包括的なフレームワークを提案している。第一の「表現層(Representation Layer)」では、損失関数やアーキテクチャのトポロジーにおける基本的なトレードオフを分析する。ここでは、Bi-Encoderの効率性とCross-Encoderの表現力の二項対立を軸に、そのギャップを埋めるための「Late Interaction」などのハイブリッドパラダイムを検討している。これにより、大規模なコーパスに対するスケーラビリティと、詳細な意味理解を両立させるための道筋を明らかにしている。 第二の「粒度層(Granularity Layer)」では、ドキュメントのセグメンテーション(チャンキング)が情報のボトルネックに与える影響を評価する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related