AACR-Bench: 包括的なリポジトリレベルのコンテキストを用いた自動コードレビューの評価
従来の自動コードレビュー評価は、不完全な正解データと単一言語への依存という課題を抱えていたが、本研究では10種類の主要プログラミング言語に対応し、リポジトリ全体の文脈を活用できる新しいベンチマーク「AACR-Bench」を開発した。
TL;DR(結論)
従来の自動コードレビュー評価は、不完全な正解データと単一言語への依存という課題を抱えていたが、本研究では10種類の主要プログラミング言語に対応し、リポジトリ全体の文脈を活用できる新しいベンチマーク「AACR-Bench」を開発した。 AIによる生成と80名の熟練エンジニアによる検証を組み合わせたアノテーションパイプラインを導入することで、従来のデータセットと比較して問題の網羅性を285%向上させ、人間のレビューで見落とされがちな潜在的な欠陥をより正確に評価できる環境を整えた。 主要な大規模言語モデルを用いた検証の結果、エージェント形式の採用や文脈取得の手法が性能に与える影響はモデルや言語ごとに大きく異なることが判明し、実用的なコードレビューシステムの構築にはモデル特性に応じた戦略が必要であるという新たな知見を提供している。
なぜこの問題か
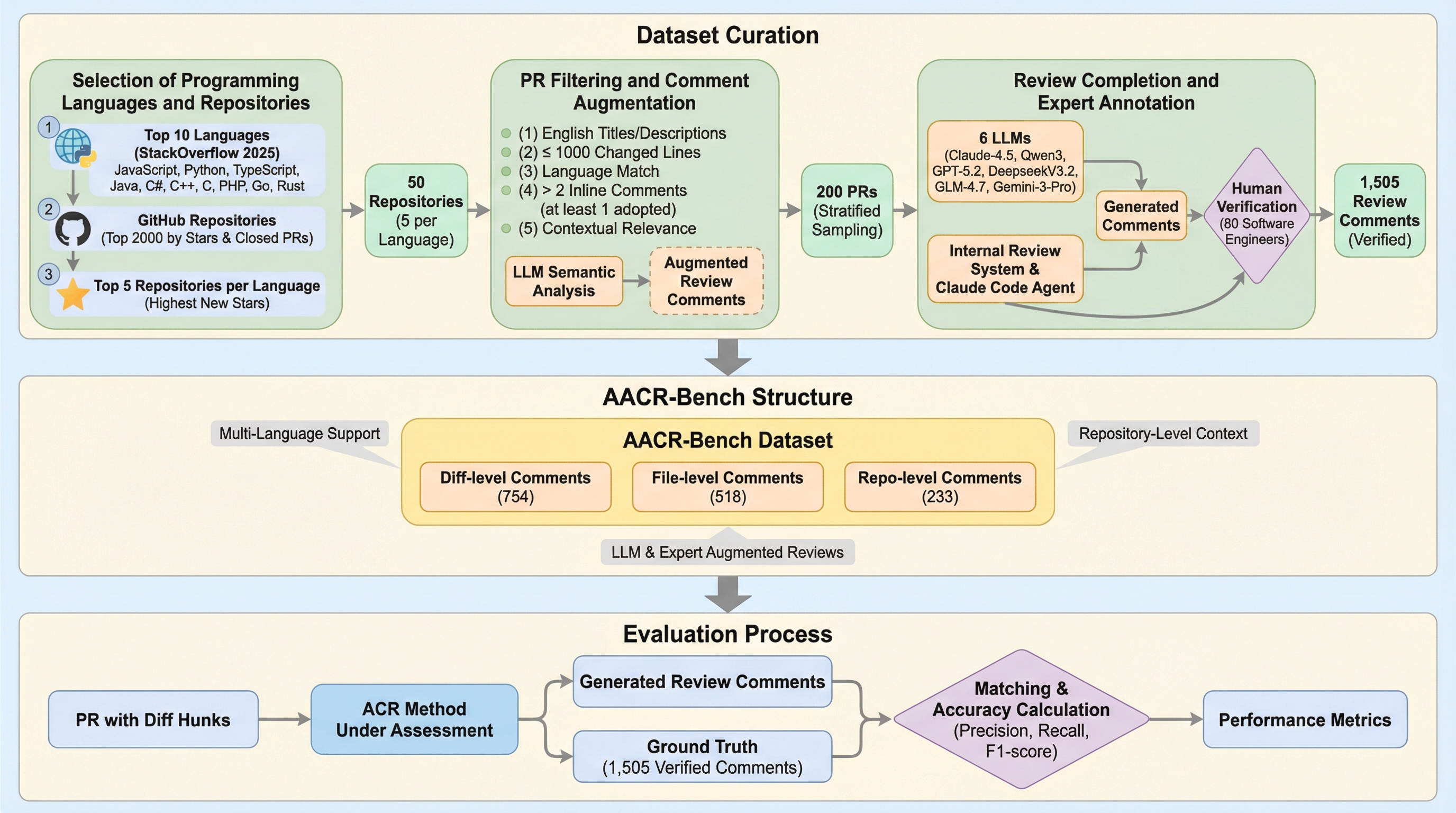
自動コードレビュー(ACR)技術は、大規模言語モデル(LLM)の急速な発展に伴い、ソフトウェア開発の現場で広く研究・採用されるようになっている。しかし、これらのシステムの性能を客観的かつ包括的に評価するための基準には、現在二つの致命的な限界が存在している。第一に、既存のベンチマークの多くは、GitHubなどのプルリクエスト(PR)から抽出された生のコメントをそのまま正解データ(Ground Truth)として利用している点である。実際の開発現場でのレビューは必ずしも完璧ではなく、人間が見逃した潜在的な欠陥が数多く存在する。そのため、生のデータに依存した評価では、モデルが真に優れた指摘を行っても、それが正解データに含まれていないために過小評価されるという問題が生じる。 第二の課題は、評価における文脈の範囲とプログラミング言語の多様性の欠如である。多くのコード欠陥は、単一のファイル内だけでなく、複数のファイルにまたがる依存関係やプロジェクト全体の構造に起因する。…
核心:何を提案したのか
本研究では、上述の課題を克服するために、リポジトリレベルの文脈認識をサポートする多言語ACRベンチマーク「AACR-Bench」を提案した。このベンチマークは、最新のStackOverflow開発者調査に基づき、JavaScript、Python、TypeScript、Java、C#、C++、C、PHP、Go、Rustという、現代のソフトウェア開発で最も広く使われている10種類の主要プログラミング言語を網羅している。各言語につき5つの人気リポジトリを選定し、合計50のリポジトリから抽出された200件のプルリクエストを評価単位として構成している。これにより、特定の言語に依存しない、極めて汎用性の高い評価が可能となった。 AACR-Benchの最も革新的な点は、そのデータ構築手法にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related