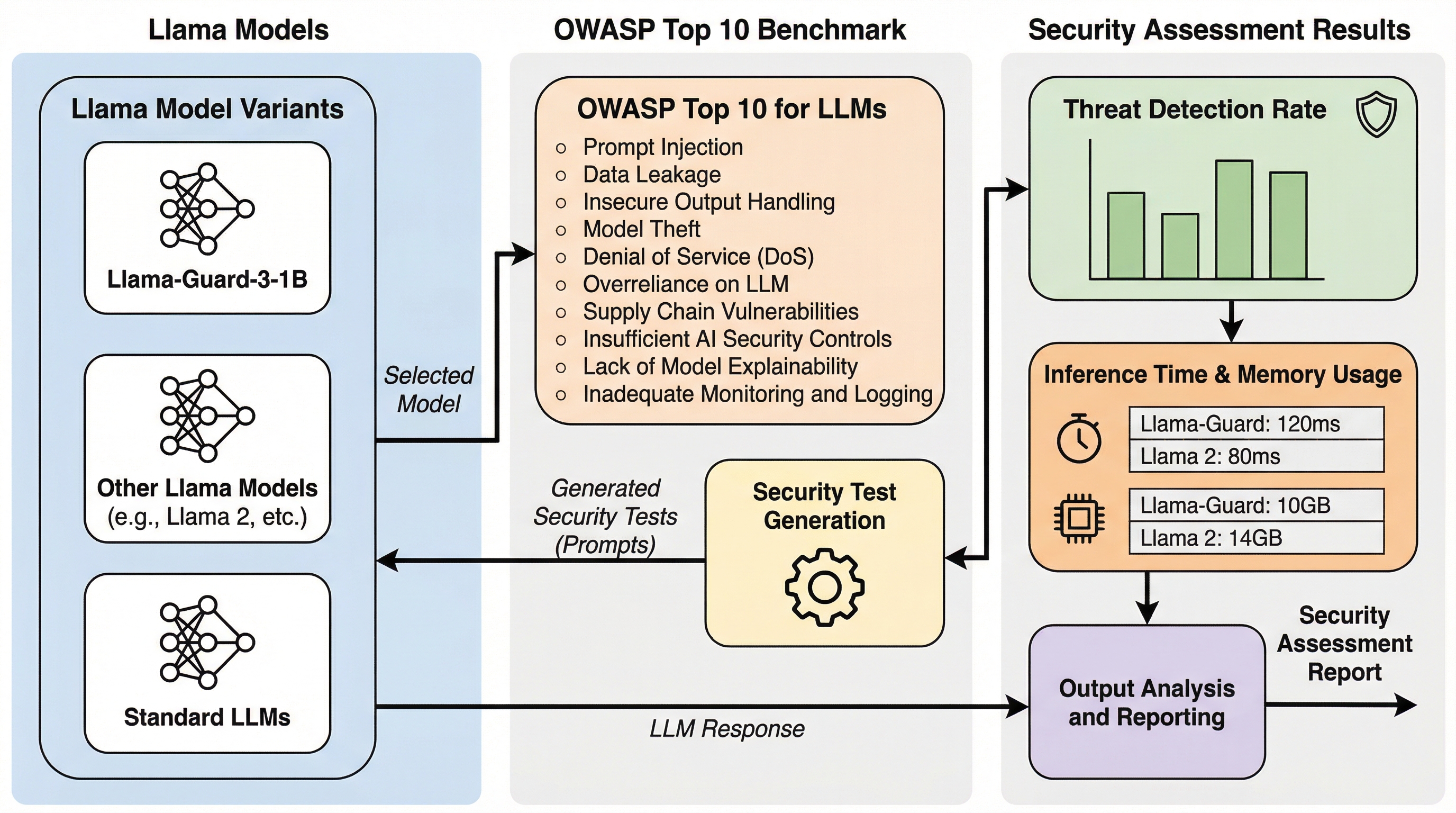
Llama Guard 3-1Bは最強か? OWASP Top 10に対するLlamaモデルのセキュリティ耐性のベンチマーク評価
本研究では、Llamaモデルの多様なバリアントをOWASP Top 10フレームワークに基づき評価した結果、最小クラスのLlama-Guard-3-1Bが76%という最高の検知率を記録し、推論時間0.165秒、VRAM使用量0.94GBという極めて高い効率性を示した。 一方で、Llama-3.
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究では、Llamaモデルの多様なバリアントをOWASP Top 10フレームワークに基づき評価した結果、最小クラスのLlama-Guard-3-1Bが76%という最高の検知率を記録し、推論時間0.165秒、VRAM使用量0.94GBという極めて高い効率性を示した。 一方で、Llama-3.
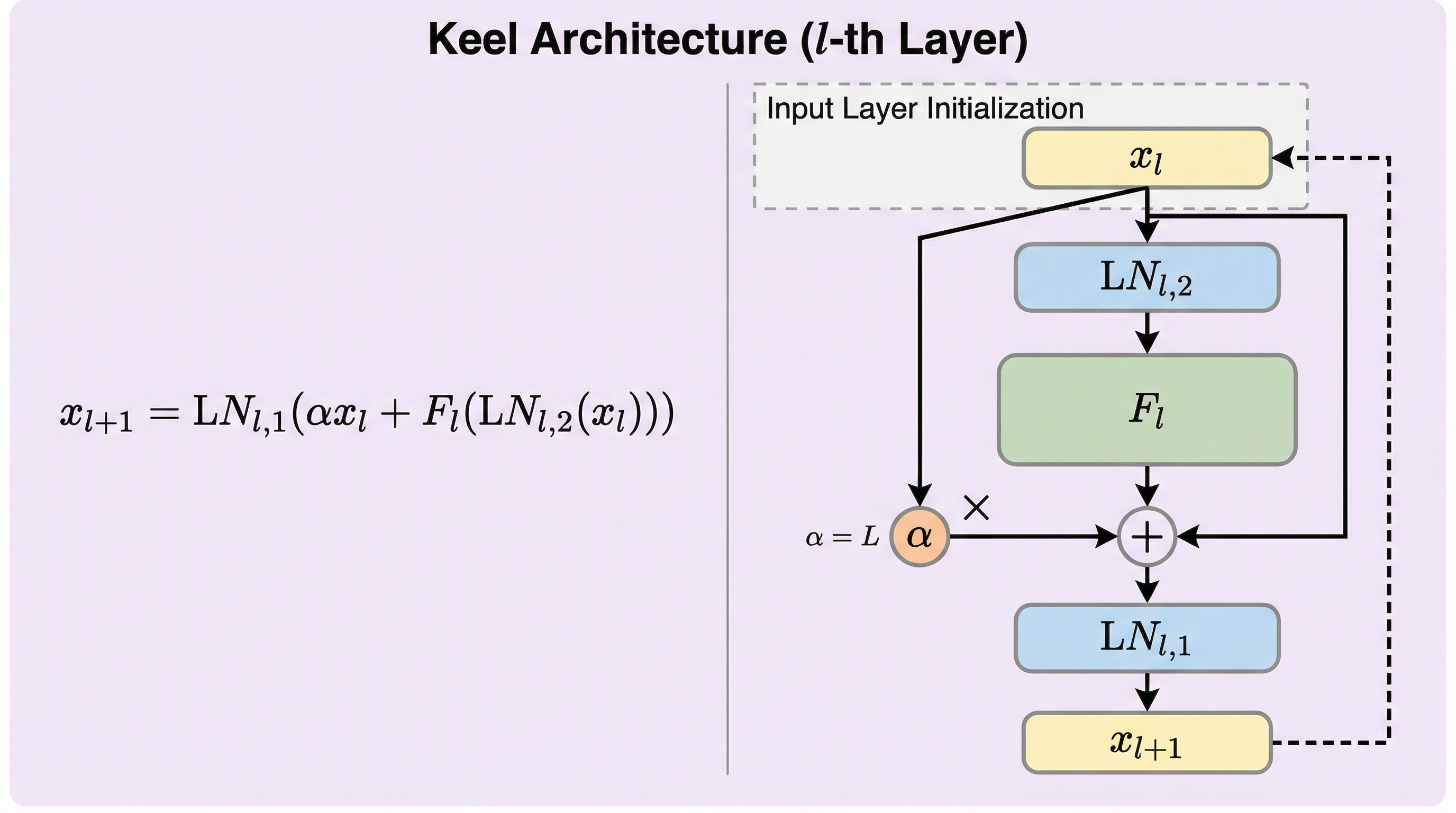
大規模言語モデル(LLM)のスケーリングが限界に達しつつある中、従来のPre-LayerNormに代わり、高い表現力を持つPost-LayerNormを改善した新アーキテクチャ「Keel」が提案されました。
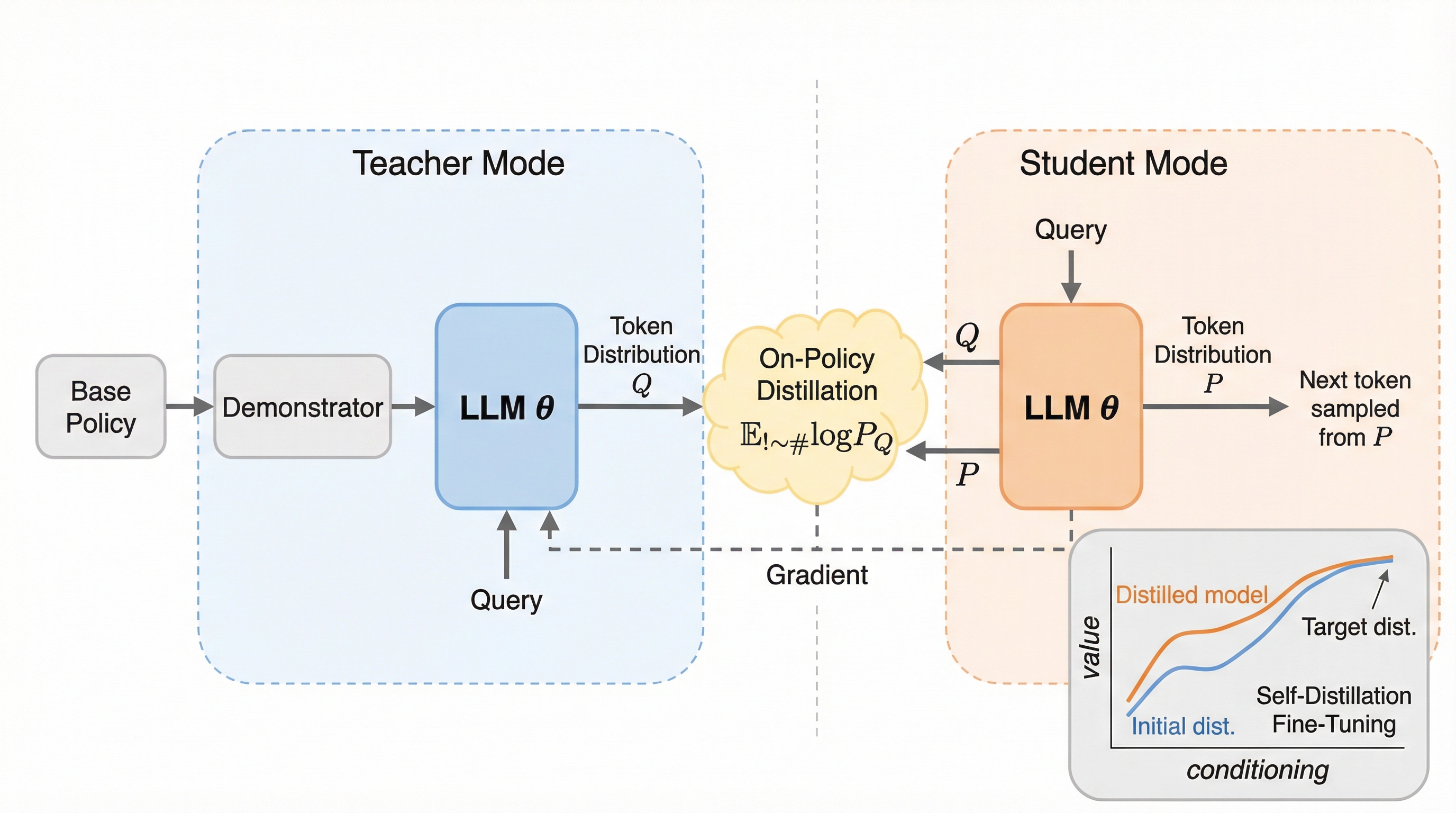
基盤モデルが既存の能力を損なわずに新しい知識やスキルを習得し続ける「継続学習」において、従来の教師あり微調整(SFT)は過去の知識を失う「破滅的忘却」を引き起こすという深刻な課題があった。 本研究が提案する自己蒸留微調整(SDFT)は、モデル自身のインコンテキスト学習能力を活用してデモンストレーションから「オンポリシー」な学習信号を生成し、明示的な報酬関数がない環境でも過去の能力を維持しながら新スキルを習得させる手法である。 検証の結果、SDFTはスキル習得と知識獲得の両面で従来のSFTを凌駕し、複数のスキルを順番に学習させる実験においても性能を低下させることなく蓄積することに成功し、デモンストレーションからの継続学習における実用的な道筋を明確に示した。
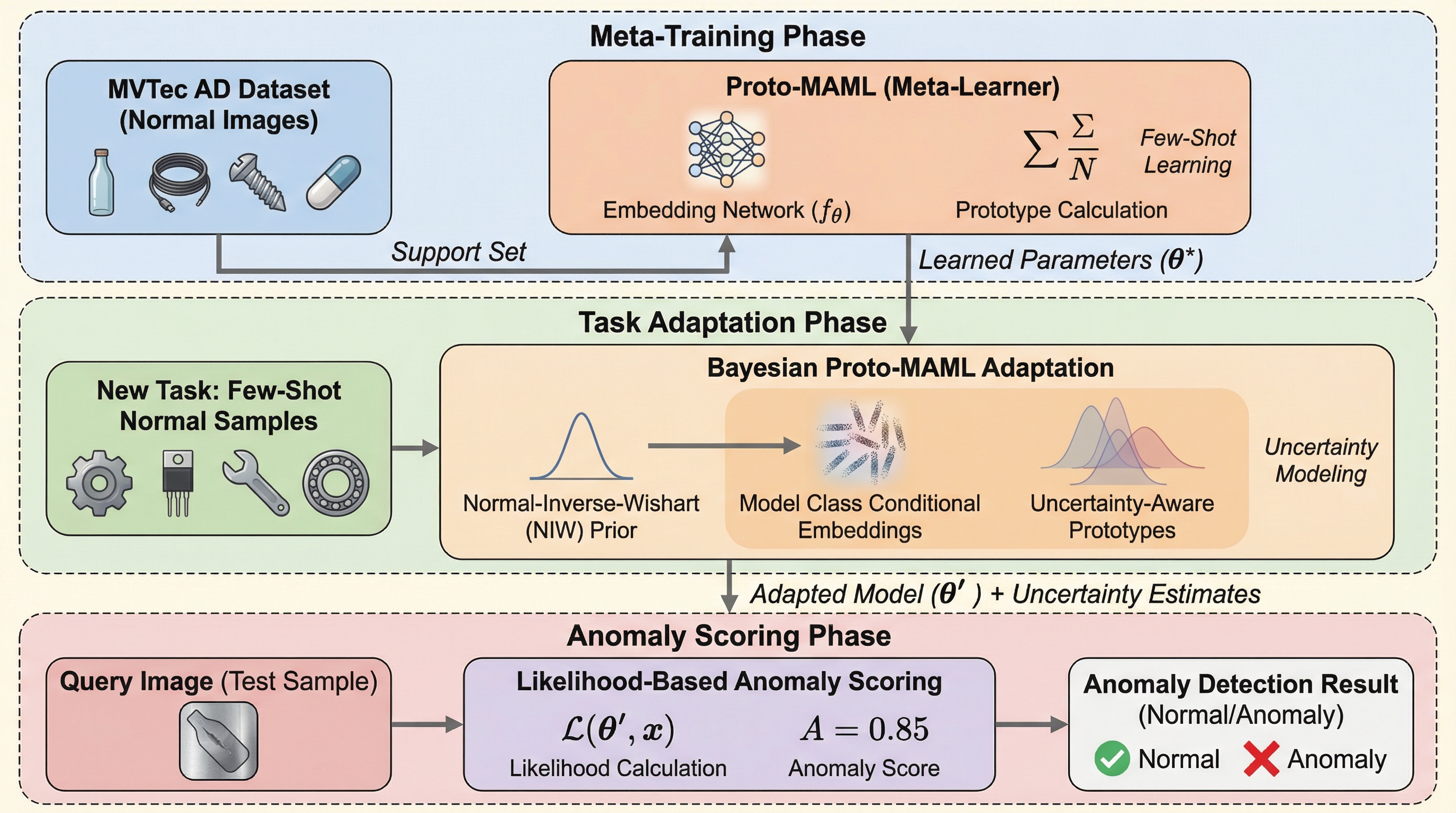
本研究は、工業製品の画像における異常検知において、極端に少ない学習データ(少数ショット)からでも高精度な識別を可能にする新しいフレームワーク「BayPrAnoMeta」を提案し、ベイズ的な確率モデルを導入することで不確実性を考慮した頑健なスコアリングを実現しました。
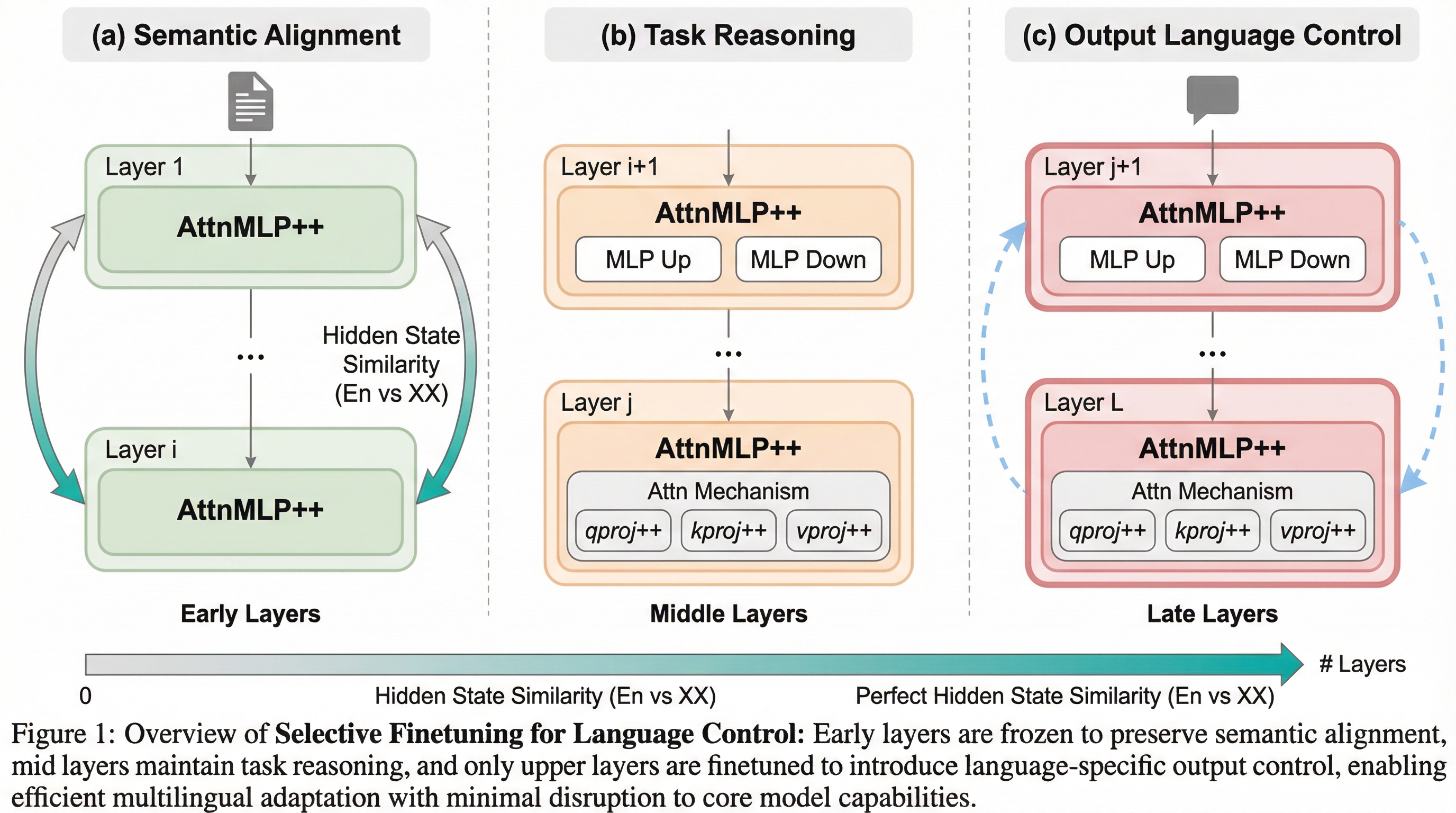
多言語大規模言語モデルが直面する「回答は正しいが出力言語を誤る」という言語一貫性の欠如と、「言語は正しいがタスクに失敗する」という多言語転送の停滞という二つの主要なボトルネックを特定し、モデル内部の層が「初期の意味整合」「中間のタスク推論」「終盤の言語制御」という明確な三段階の機能構造を持つことを解明しました。
重力波観測装置LIGOにおいて、天体信号を模倣し解析を妨げる一過性ノイズ「グリッチ」の識別は、膨大なラベル付きデータを必要とする従来の教師あり学習モデルでは、新しい形態のノイズへの対応や汎化性能に限界がありました。
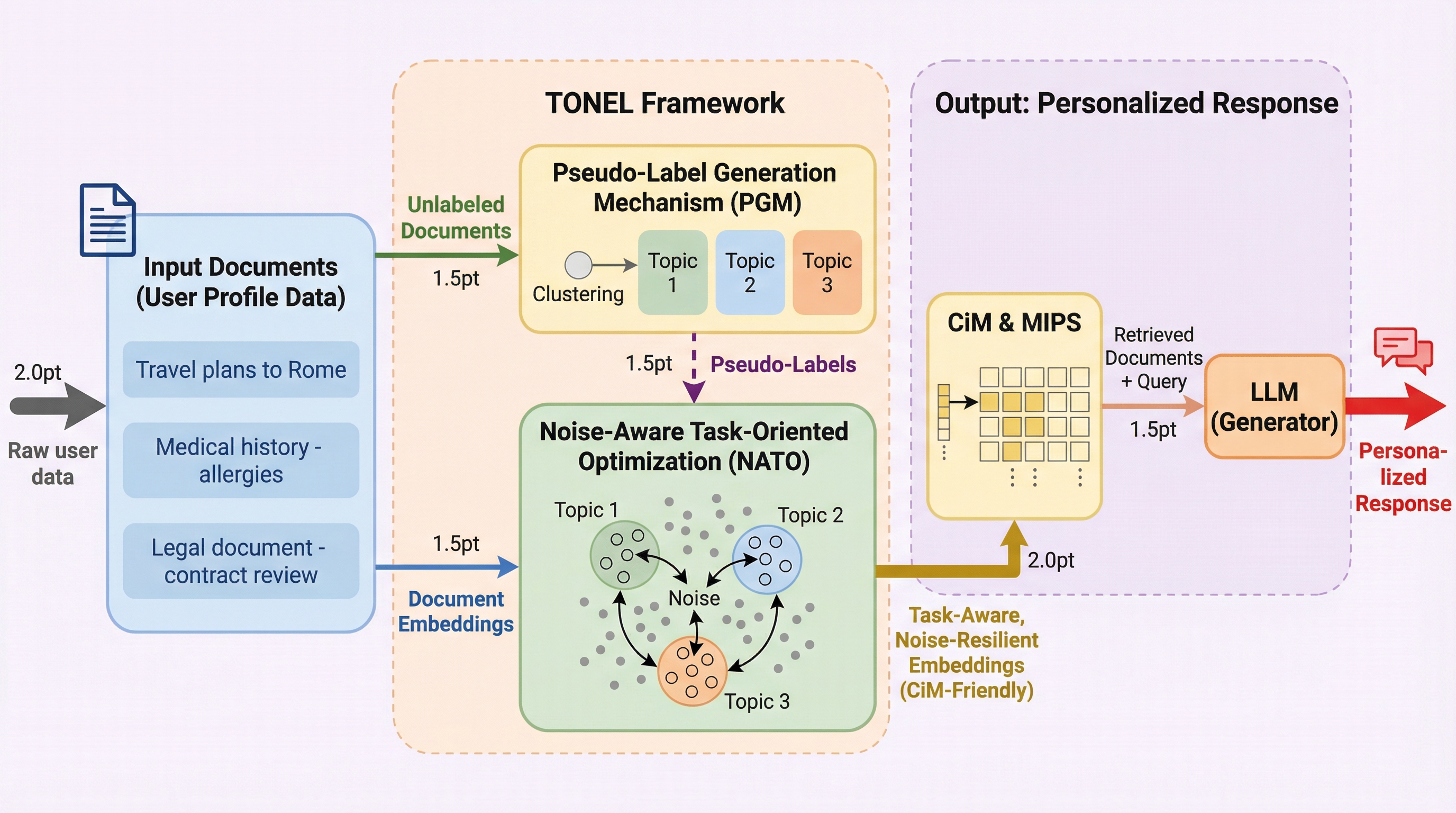
エッジデバイス上での大規模言語モデル(LLM)のパーソナライズにおいて、検索拡張生成(RAG)は有効な手法ですが、メモリと演算のボトルネックを解消するために導入されるメモリ内演算(CiM)アーキテクチャは、環境ノイズによって検索精度が低下するという課題を抱えています。
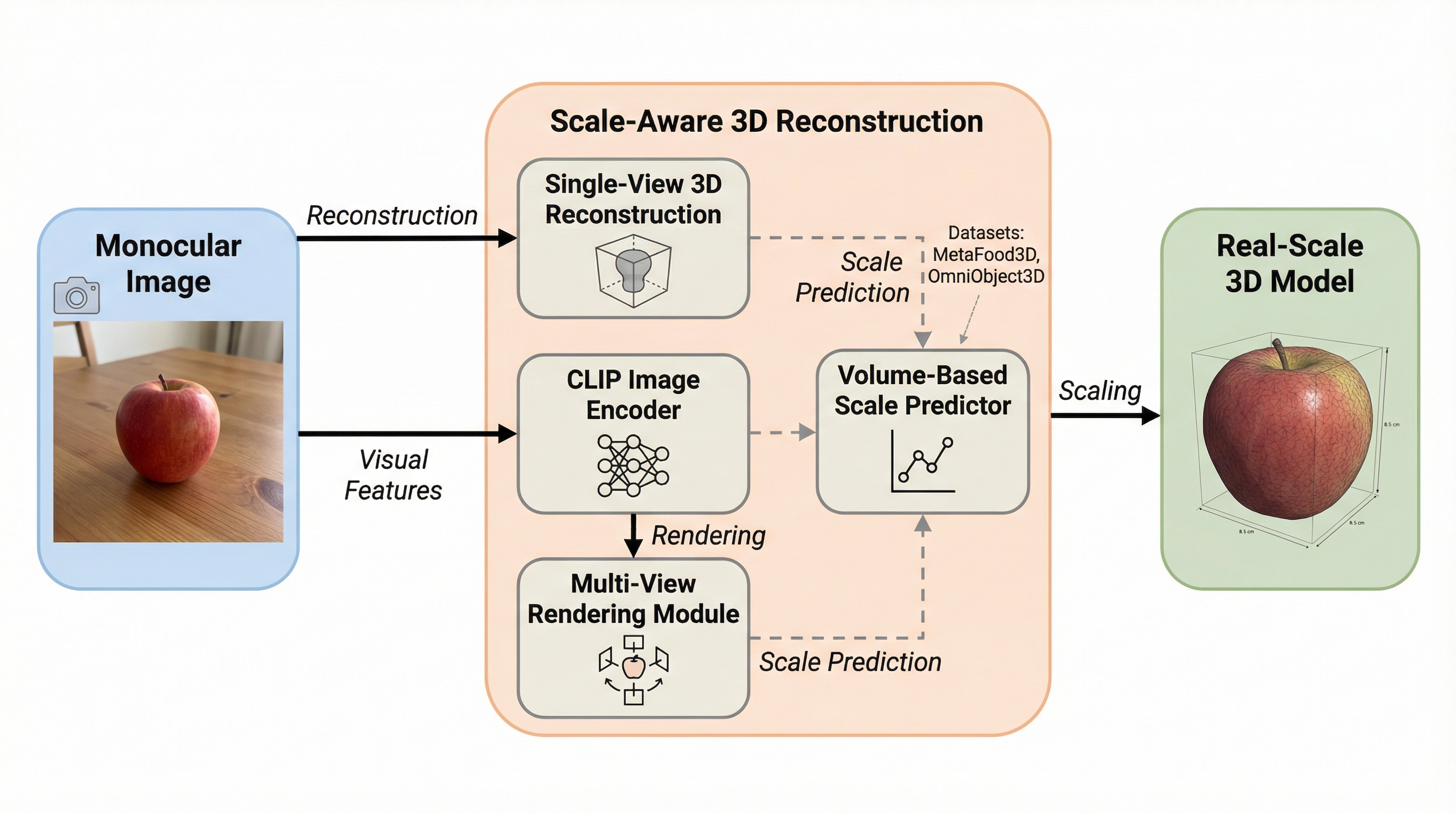
従来の単眼画像からの3D再構築手法では、ブルーベリーとカボチャが同じサイズに見えるような「物理的スケールの欠如」が課題でしたが、本研究はCLIPの視覚的特徴と多角的なレンダリング画像を組み合わせることで、実寸大の3Dモデルを復元する手法を提案しました。
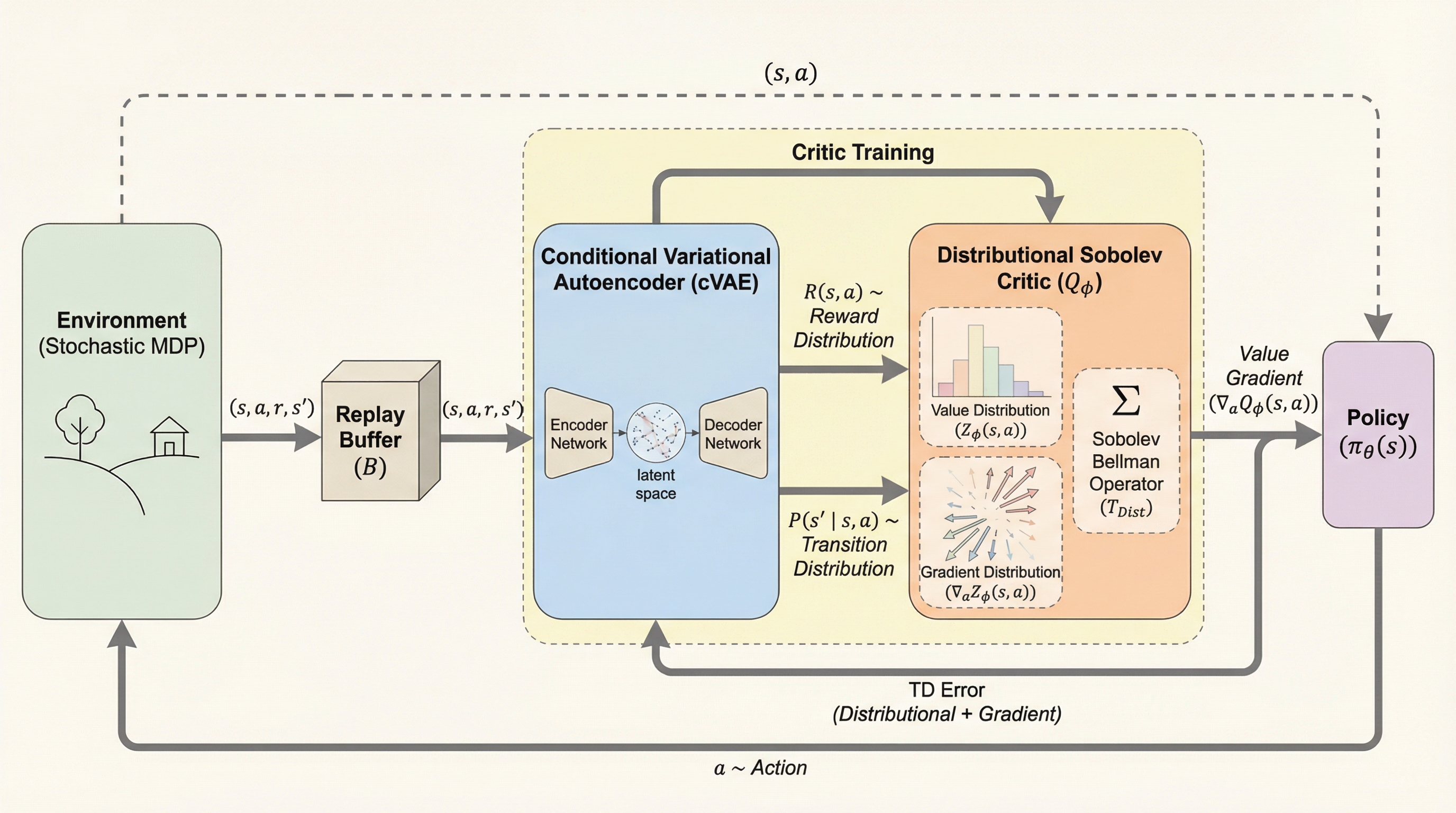
連続アクション空間の強化学習において、報酬の期待値だけでなく、累積報酬とそのアクション勾配の両方をジョイント分布として同時にモデル化する「分布型ソボレフ学習」という新しい枠組みを提案した。 理論面では、最大スライス最大平均不一致(MSMMD)という指標を用いることで、提案したソボレフ・ベルマン演算子が唯一の不動点に収束する縮小写像であることを数学的に証明し、さらに条件付き変分オートエンコーダ(cVAE)を用いた微分可能なワールドモデルを導入することで、非微分可能な環境への適用を可能にした。 実験では、マルチモーダルな不確実性を持つトイタスクやMuJoCoベンチマークにおいて、従来の決定論的な勾配手法や勾配を考慮しない分布型手法を大幅に上回るサンプル効率と堅牢性を実証し、勾配情報の分布を捉えることが連続制御における学習に極めて有効であることを示した。
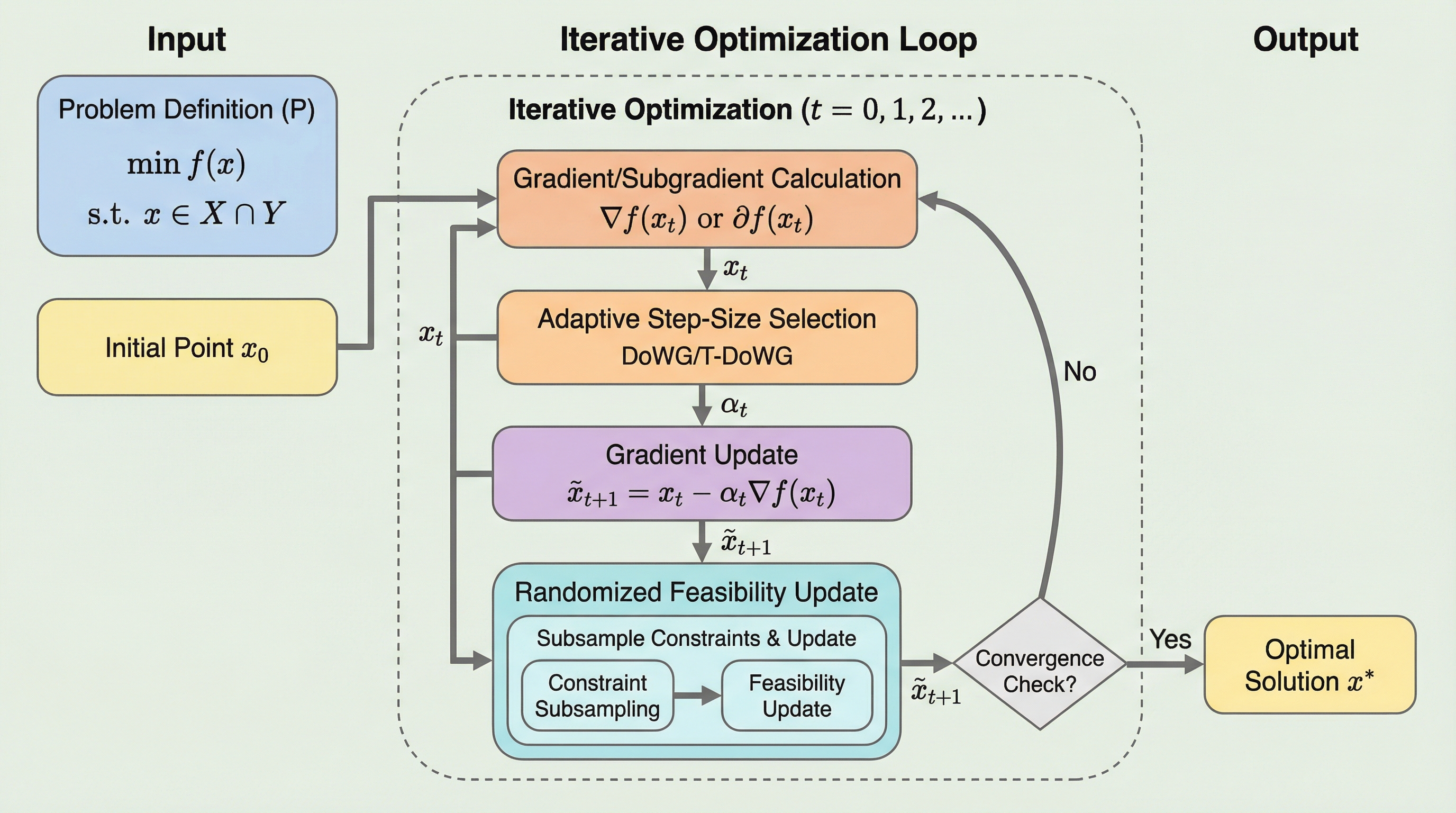
多数の凸関数が交差する複雑な制約条件下での最適化において、計算コストの高い射影操作を回避しつつ、ランダム化された実行可能性更新と適応的ステップサイズを統合した新しいアルゴリズムを提案しました。 強凸かつ平滑な目的関数に対しては任意の許容誤差までの線形収束を証明し、非平滑な凸関数の場合には問題固有のパラメータを一切必要としない「パラメータフリー」な設定で、理論的に最適な収束レートを達成することを数学的に実証しました。 二次制約付き二次計画問題(QCQP)やサポートベクターマシン(SVM)を用いた数値実験により、提案手法は既存の最先端アルゴリズムと比較して、ハイパーパラメータの調整なしに優れた計算効率と制約遵守能力を発揮することが確認されました。