CiMRAG: エッジLLMのためのCiM対応ドメイン適応・ノイズ耐性RAG
エッジデバイス上での大規模言語モデル(LLM)のパーソナライズにおいて、検索拡張生成(RAG)は有効な手法ですが、メモリと演算のボトルネックを解消するために導入されるメモリ内演算(CiM)アーキテクチャは、環境ノイズによって検索精度が低下するという課題を抱えています。
TL;DR(結論)
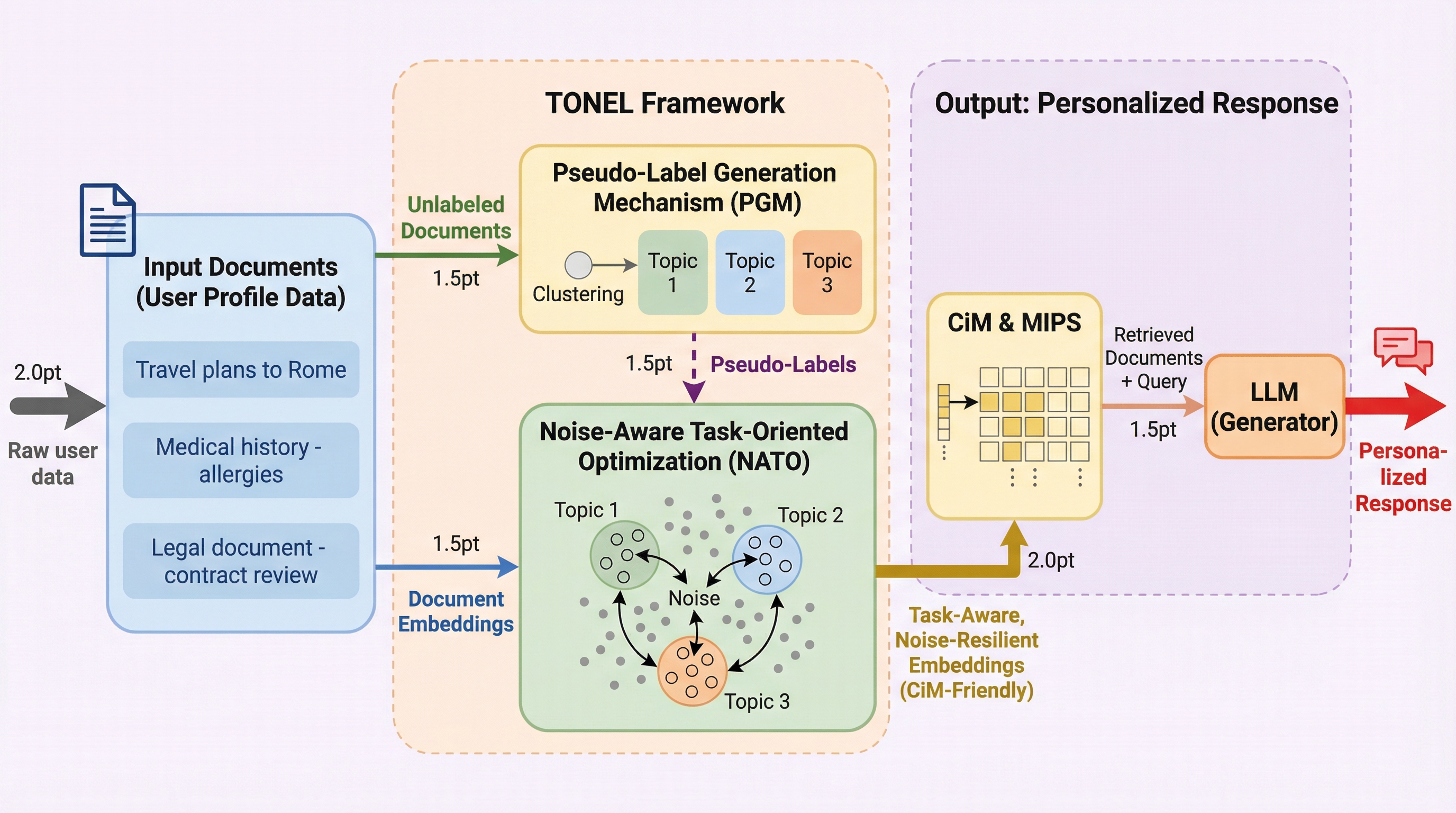
エッジデバイス上での大規模言語モデル(LLM)のパーソナライズにおいて、検索拡張生成(RAG)は有効な手法ですが、メモリと演算のボトルネックを解消するために導入されるメモリ内演算(CiM)アーキテクチャは、環境ノイズによって検索精度が低下するという課題を抱えています。 本研究が提案する「TONEL」フレームワークは、疑似ラベル生成メカニズム(PGM)とノイズを考慮したタスク指向最適化戦略(NATO)を組み合わせることで、ラベルのないデータからドメイン適応を実現し、CiM特有のハードウェアノイズに対して高い耐性を持つ埋め込みベクトルを生成します。 実験の結果、TONELは既存の手法と比較して、ノイズ環境下での最大内積検索(MIPS)の精度を大幅に向上させ、Gemma-2BやLlama-3.2-3Bといったエッジ向けLLMを用いた下流タスクにおいても、高い分類精度とF1スコアを達成することが確認されました。
なぜこの問題か
大規模言語モデル(LLM)は強力な推論能力を持ち、多くのアプリケーションで不可欠な存在となっていますが、個々のユーザーに合わせたパーソナライズされた対話を実現するためには、エッジデバイス上での効率的な展開(エッジLLM)が求められています。しかし、エッジデバイスは計算資源やメモリ容量が限られているため、クラウドベースのモデルで行われるようなモデルパラメータのファインチューニングを頻繁に行うことは現実的ではありません。この課題を解決するために、ファインチューニングを必要とせずに外部知識やユーザープロファイルを取り込むことができる検索拡張生成(RAG)が事実上の標準的な手法として浮上しています。 RAGは、ユーザーのクエリに対して最も意味的に関連性の高いドキュメントを検索し、それをクエリとともにLLMに入力することで、パーソナライズされた回答を生成します。しかし、エッジデバイスにおけるRAGの運用には2つの大きな効率性の壁が存在します。第一に、ユーザーの対話履歴などのプロファイルデータがRAMの容量を超えて増大すると、HDDやSSDといった低速なストレージへの依存度が高まり、データ転送の遅延(レイテンシ)が深刻化します。…
核心:何を提案したのか
本研究では、CiMハードウェア上でのMIPS検索において、ノイズ耐性とドメイン適応能力を同時に高めるためのラベルフリーなフレームワーク「TONEL(Task-Oriented Noise-resilient Embedding Learning)」を提案しました。TONELの核心は、エッジ環境特有の制約であるハードウェアノイズと、ラベル付けされていない膨大なユーザーデータの両方に対処することにあります。 TONELは主に2つの革新的なコンポーネントで構成されています。一つ目は「ノイズを考慮したタスク指向最適化戦略(NATO)」です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related