Post-LayerNormが帰ってきた:安定、表現力豊か、そして深い
大規模言語モデル(LLM)のスケーリングが限界に達しつつある中、従来のPre-LayerNormに代わり、高い表現力を持つPost-LayerNormを改善した新アーキテクチャ「Keel」が提案されました。
TL;DR(結論)
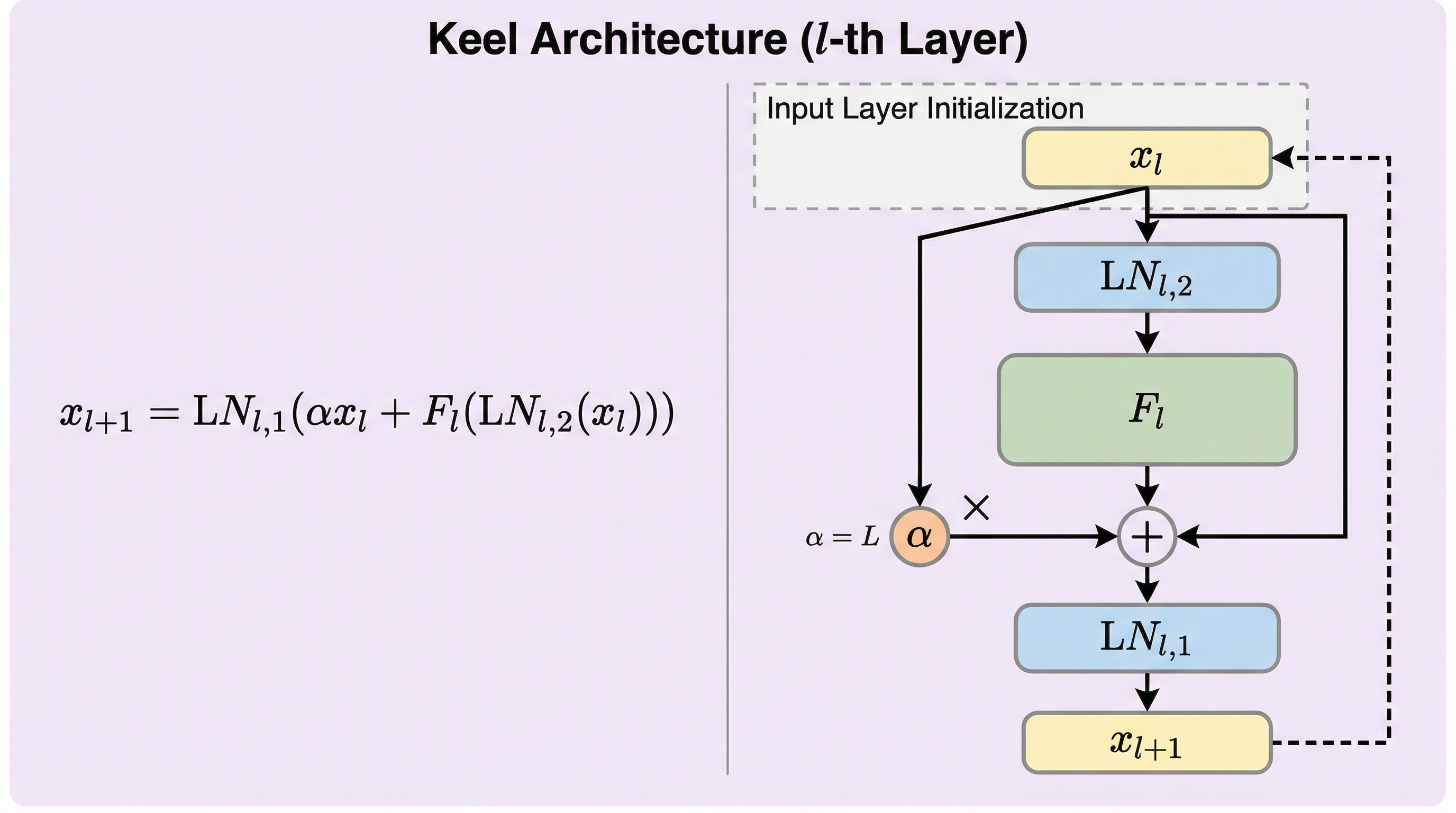
大規模言語モデル(LLM)のスケーリングが限界に達しつつある中、従来のPre-LayerNormに代わり、高い表現力を持つPost-LayerNormを改善した新アーキテクチャ「Keel」が提案されました。 この手法は、残差経路をHighway型の接続に置き換え、スケーリング因子を導入することで、深層ネットワークにおける勾配消失問題を理論的に解決し、1000層を超える極端な深さでも安定した学習を可能にします。 検証の結果、Keelは従来のPre-LayerNormと比較して、特に数学やコードなどの複雑なタスクで16.5%の性能向上を達成し、モデルの深さに応じたスケーリング特性を劇的に改善することが確認されました。
なぜこの問題か
大規模言語モデル(LLM)の進歩は、これまでモデルの幅の拡大、コンテキスト長の延長、そして学習データの増大というスケーリング則によって牽引されてきました。しかし、これらの従来の拡張軸は、次第に収穫逓減の壁に直面しています。モデルの幅を広げることによる恩恵は飽和し始めており、コンテキスト長の延長もモデルの根本的な表現力を向上させるには至っていません。一方で、理論的にはモデルを深くすること、つまり層を増やすことが、より豊かな関数表現や階層的な推論能力を獲得するために極めて有効であると考えられています。しかし、現在のTransformerアーキテクチャでは、極端な深さにおいて安定して学習を行うことが困難であるという構造的な課題がありました。 この問題の核心は、Layer Normalization(LN)の配置にあります。初期のTransformerではPost-LayerNorm(Post-LN)が採用されていましたが、深層化に伴う学習の不安定さから、現代のLLMの多くはPre-LayerNorm(Pre-LN)を採用しています。…
核心:何を提案したのか
本論文では、Post-LNアーキテクチャを安定化させ、超深層LLMの学習を可能にする新しいアーキテクチャ「Keel」を提案しています。Keelの最大の特徴は、従来のResNetスタイルの単純な加算による残差経路を、軽量な「Highwayスタイル」のゲート付き接続に置き換えた点にあります。この変更により、残差ブランチを通る勾配の流れが適切に維持され、ネットワークの最上層から最下層までの信号の消失を防ぐことができます。これは、特別な初期化手法や複雑な最適化のトリックを必要とせずに、極端な深さでの安定した学習を実現するシンプルかつ強力な解決策です。 具体的には、Keelは残差接続にスケーリング因子「α」を導入し、さらに変換関数(AttentionやFFN)の入力直前に追加のLayerNormを挿入する構造をとっています。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related