確率的環境における分布型価値勾配法:分布型ソボレフ学習
連続アクション空間の強化学習において、報酬の期待値だけでなく、累積報酬とそのアクション勾配の両方をジョイント分布として同時にモデル化する「分布型ソボレフ学習」という新しい枠組みを提案した。 理論面では、最大スライス最大平均不一致(MSMMD)という指標を用いることで、提案したソボレフ・ベルマン演算子が唯一の不動点に収束する縮小写像であることを数学的に証明し、さらに条件付き変分オートエンコーダ(cVAE)を用いた微分可能なワールドモデルを導入することで、非微分可能な環境への適用を可能にした。 実験では、マルチモーダルな不確実性を持つトイタスクやMuJoCoベンチマークにおいて、従来の決定論的な勾配手法や勾配を考慮しない分布型手法を大幅に上回るサンプル効率と堅牢性を実証し、勾配情報の分布を捉えることが連続制御における学習に極めて有効であることを示した。
TL;DR(結論)
連続アクション空間の強化学習において、報酬の期待値だけでなく、累積報酬とそのアクション勾配の両方をジョイント分布として同時にモデル化する「分布型ソボレフ学習」という新しい枠組みを提案した。 理論面では、最大スライス最大平均不一致(MSMMD)という指標を用いることで、提案したソボレフ・ベルマン演算子が唯一の不動点に収束する縮小写像であることを数学的に証明し、さらに条件付き変分オートエンコーダ(cVAE)を用いた微分可能なワールドモデルを導入することで、非微分可能な環境への適用を可能にした。 実験では、マルチモーダルな不確実性を持つトイタスクやMuJoCoベンチマークにおいて、従来の決定論的な勾配手法や勾配を考慮しない分布型手法を大幅に上回るサンプル効率と堅牢性を実証し、勾配情報の分布を捉えることが連続制御における学習に極めて有効であることを示した。
なぜこの問題か
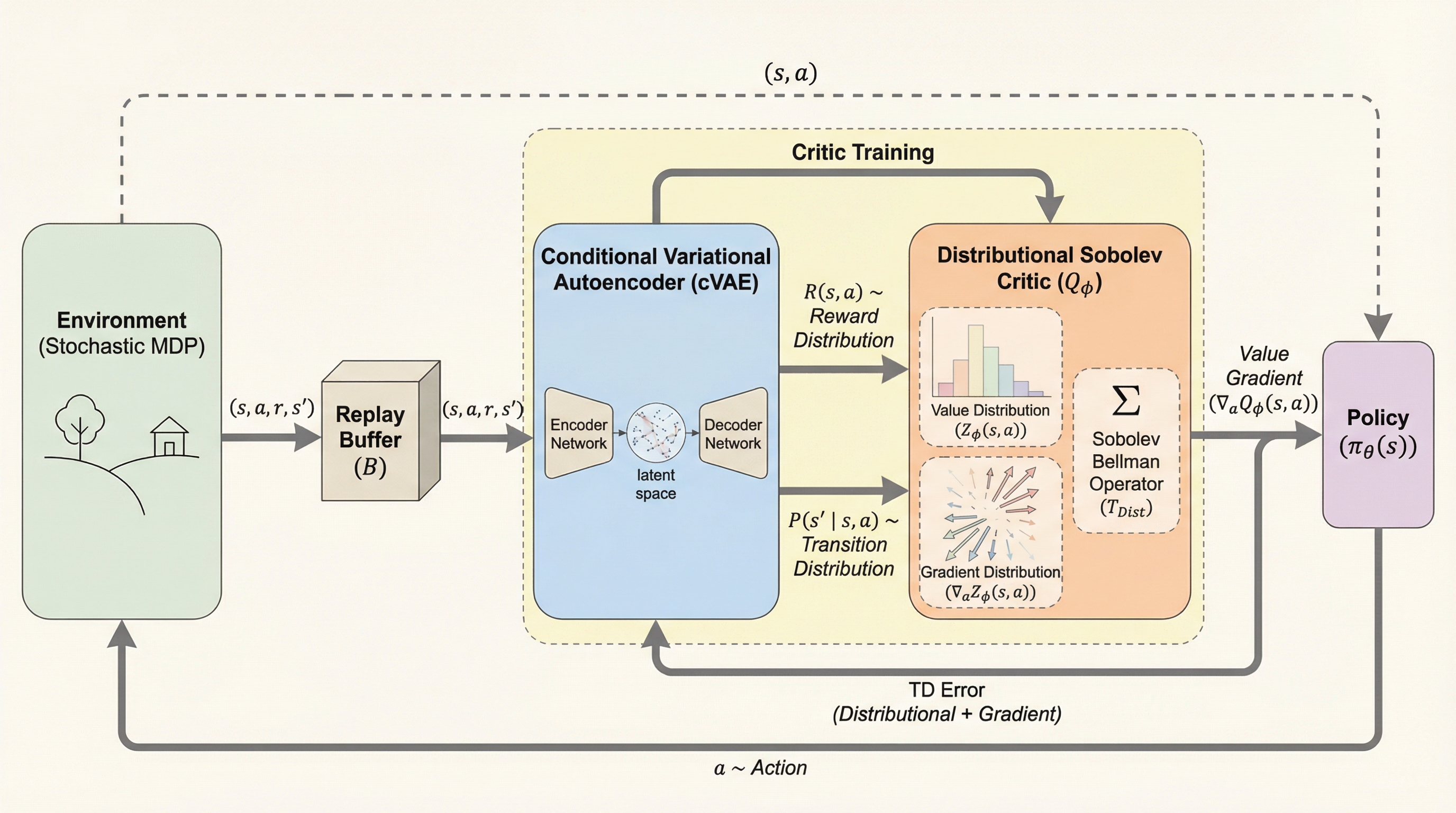
連続的なアクション空間における強化学習では、エージェントが最適な行動を選択するために、方策(アクター)と価値関数(クリティック)を同時に学習させる手法が一般的である。特に、クリティックが提供するアクション勾配、すなわち「どのアクションをどのように微調整すれば期待リターンが向上するか」という情報は、方策を効率的に更新するために極めて重要である。しかし、従来の時間差(TD)学習法は、真の価値関数が滑らかであるという強い仮定に依存しており、複雑な環境やノイズの多い状況では、この勾配情報の推定精度が著しく低下し、学習が不安定になるという課題があった。この問題に対し、既存の研究では環境の遷移や報酬を模倣する微分可能なワールドモデルを学習し、それを通じて勾配情報を直接取り入れる手法や、報酬の期待値だけでなくリターンの分布そのものをモデル化する「分布型強化学習」が提案されてきた。 分布型強化学習は、環境に内在する回避不可能な不確実性を捉えることで、学習の安定性と性能を向上させてきたが、これら既存の手法には共通の盲点が存在する。それは、環境のランダム性がリターンの「値」だけでなく、その「勾配」にも直接的な影響を与えるという点である。…
核心:何を提案したのか
本研究の核心的な提案は、リターンとそのアクション勾配の両方を一つのジョイント乱数として定義し、その同時分布を学習する「分布型ソボレフ強化学習(Distributional Sobolev Reinforcement Learning)」という新しい理論的枠組みを構築したことにある。具体的には、従来のスカラー値としてのリターンを拡張し、割引累積報酬の総和とそのアクションに関する勾配を要素に持つベクトルとして「ランダム・アクション・ソボレフ・リターン」を定義した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related