LinguaMap: LLMのどの層が「あなたの言語」を話し、どう調整すべきか?
多言語大規模言語モデルが直面する「回答は正しいが出力言語を誤る」という言語一貫性の欠如と、「言語は正しいがタスクに失敗する」という多言語転送の停滞という二つの主要なボトルネックを特定し、モデル内部の層が「初期の意味整合」「中間のタスク推論」「終盤の言語制御」という明確な三段階の機能構造を持つことを解明しました。
TL;DR(結論)
多言語大規模言語モデルが直面する「回答は正しいが出力言語を誤る」という言語一貫性の欠如と、「言語は正しいがタスクに失敗する」という多言語転送の停滞という二つの主要なボトルネックを特定し、モデル内部の層が「初期の意味整合」「中間のタスク推論」「終盤の言語制御」という明確な三段階の機能構造を持つことを解明しました。 この内部構造の知見に基づき、モデル全体のパラメータを更新するのではなく、言語出力を司る最終盤のわずか3パーセントから5パーセントの層のみを対象とする「選択的微調整」という極めて効率的な手法を提案し、計算資源を大幅に節約しながら特定の言語環境への適応を可能にする新しいアプローチを確立しました。 Qwen-3-32BやBloom-7.1Bを用いた検証において、タスクの推論精度を一切損なうことなく、混合言語プロンプトなどの困難な条件下でも98パーセント以上の極めて高い言語一貫性を達成し、全パラメータを微調整する従来手法と同等の効果を最小限のコストで実現できることを実証しました。
なぜこの問題か
多言語で事前学習された大規模言語モデルは、理論上は多くの言語を扱えるはずですが、実際には意図した言語で回答できないという深刻な「言語制御」の問題に直面しています。本研究ではこの問題を二つの側面から定義しています。一つは、出力言語は指示通りですがタスクの回答内容を間違えてしまう「多言語転送ボトルネック」であり、もう一つは、タスクの正解は導き出せているのに出力言語が指示と異なってしまう「言語一貫性ボトルネック」です。特に後者は、モデルが内部的に高い知能を持ちながらも、ユーザーが求める言語的な文脈に適応できていないことを示しており、実用化における大きな障壁となっています。これまでの研究では、モデルが英語以外の入力を処理する際、内部的に英語の表現を経由して推論を行う「潜在的な英語優位性」や「英語で思考する現象」が指摘されてきました。このため、英語中心の学習データによるバイアスや、異なる言語間での干渉が、モデルの推論能力と言語出力能力を切り離してしまっているのです。…
核心:何を提案したのか
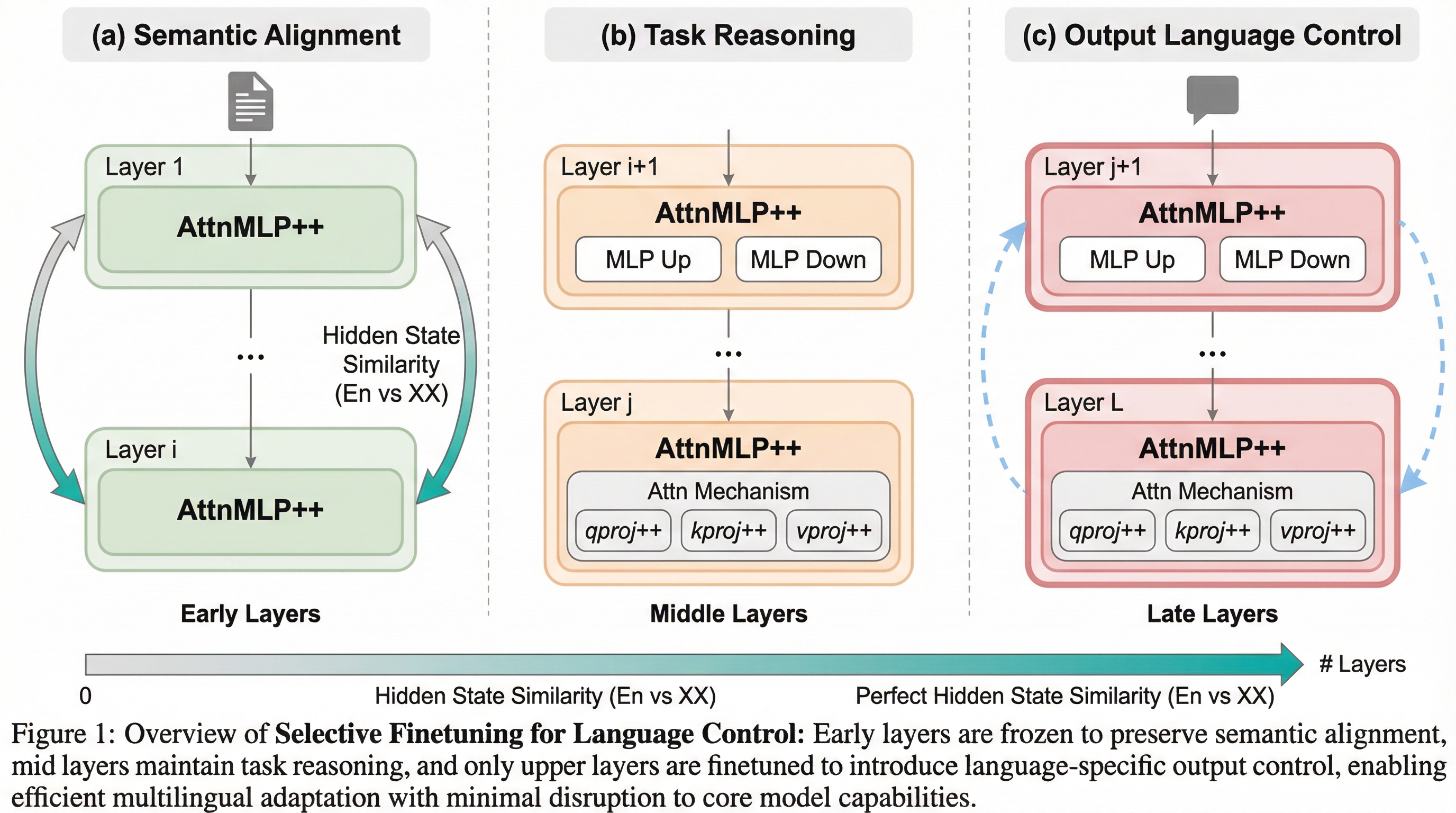
本研究の核心は、多言語モデルの内部構造が「初期層での意味整合」「中間層でのタスク推論」「終盤層での言語出力制御」という三つのフェーズに分かれていることを突き止めた点にあります。この発見に基づき、言語制御を司る最終盤のわずか3パーセントから5パーセントの層のみを更新する「選択的微調整」という手法を提案しました。これは、モデルの大部分を凍結したまま、出力に近い特定の層だけを特定の言語に合わせて調整することで、モデルが本来持つ高い推論能力を維持しつつ、出力言語の正確な制御を可能にするものです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related