自己蒸留が継続学習を可能にする:SDFTの提案
基盤モデルが既存の能力を損なわずに新しい知識やスキルを習得し続ける「継続学習」において、従来の教師あり微調整(SFT)は過去の知識を失う「破滅的忘却」を引き起こすという深刻な課題があった。 本研究が提案する自己蒸留微調整(SDFT)は、モデル自身のインコンテキスト学習能力を活用してデモンストレーションから「オンポリシー」な学習信号を生成し、明示的な報酬関数がない環境でも過去の能力を維持しながら新スキルを習得させる手法である。 検証の結果、SDFTはスキル習得と知識獲得の両面で従来のSFTを凌駕し、複数のスキルを順番に学習させる実験においても性能を低下させることなく蓄積することに成功し、デモンストレーションからの継続学習における実用的な道筋を明確に示した。
TL;DR(結論)
基盤モデルが既存の能力を損なわずに新しい知識やスキルを習得し続ける「継続学習」において、従来の教師あり微調整(SFT)は過去の知識を失う「破滅的忘却」を引き起こすという深刻な課題があった。 本研究が提案する自己蒸留微調整(SDFT)は、モデル自身のインコンテキスト学習能力を活用してデモンストレーションから「オンポリシー」な学習信号を生成し、明示的な報酬関数がない環境でも過去の能力を維持しながら新スキルを習得させる手法である。 検証の結果、SDFTはスキル習得と知識獲得の両面で従来のSFTを凌駕し、複数のスキルを順番に学習させる実験においても性能を低下させることなく蓄積することに成功し、デモンストレーションからの継続学習における実用的な道筋を明確に示した。
なぜこの問題か
現代の基盤モデルは言語、視覚、ロボティクスなど多岐にわたる分野で目覚ましい成果を上げているが、デプロイ後のモデルは基本的に静的な存在に留まっている。推論時に検索やプロンプティングを通じて挙動を適応させることは可能だが、モデル自体のパラメータを更新して新しいスキルを獲得したり、新しい知識を内部化したり、経験から自己改善したりすることは依然として困難である。次世代の基盤モデルを実現するためには、人間が一生を通じて知識を蓄えスキルを磨くように、AIシステムも時間の経過とともに学習し改善し続ける「継続学習」の問題を解決しなければならない。 これまでの研究により、継続学習においては「オンポリシー学習」が極めて重要であることが明らかになっている。モデルが現在の自身のポリシー(方策)によって生成されたデータから学習する場合、オフポリシーな代替手法と比較して破滅的忘却が大幅に抑制されることが示されている。しかし、成功を収めているオンポリシー手法の多くは強化学習(RL)の文脈で開発されたものであり、明示的な報酬関数が必要となる。現実世界の多くの設定では、このような報酬関数は利用不可能であるか、定義することが困難である。…
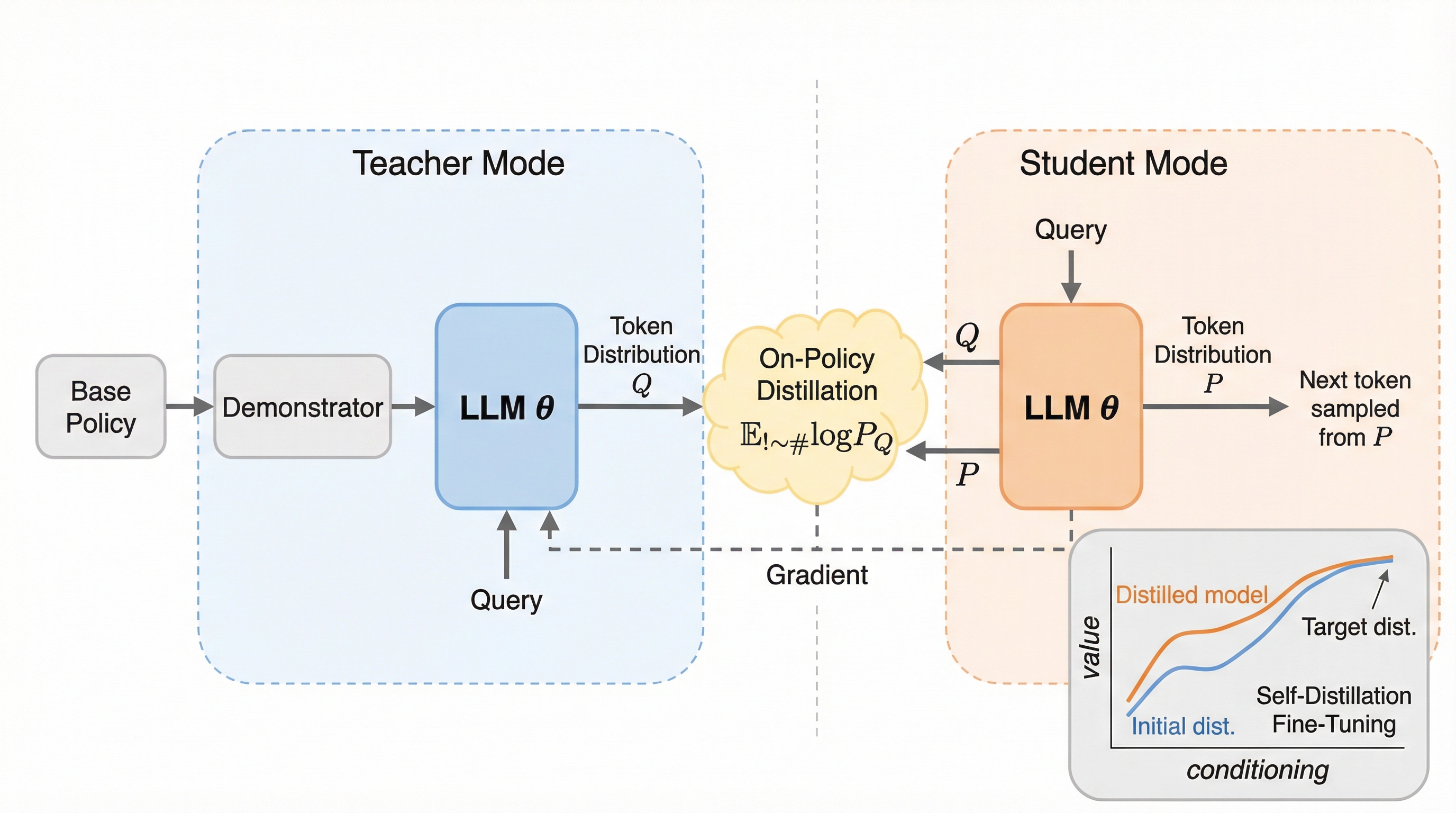
核心:何を提案したのか
本研究では、デモンストレーションから直接オンポリシー学習を行うためのフレームワークとして、自己蒸留微調整(Self-Distillation Fine-Tuning: SDFT)を提案している。この手法の根幹にあるのは、大規模な学習済みモデルがパラメータの更新なしに、与えられた例示(コンテキスト)に応じて挙動を適応させる「インコンテキスト学習(ICL)」という強力な能力を備えているという観察である。 SDFTはこの特性を巧みに利用し、同じモデルに「教師」と「生徒」という二つの役割を担わせる。教師モデルは、タスクの入力プロンプトと専門家によるデモンストレーションの両方を与えられた状態のモデルである。一方で生徒モデルは、タスクの入力プロンプトのみを与えられたベースモデルである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related