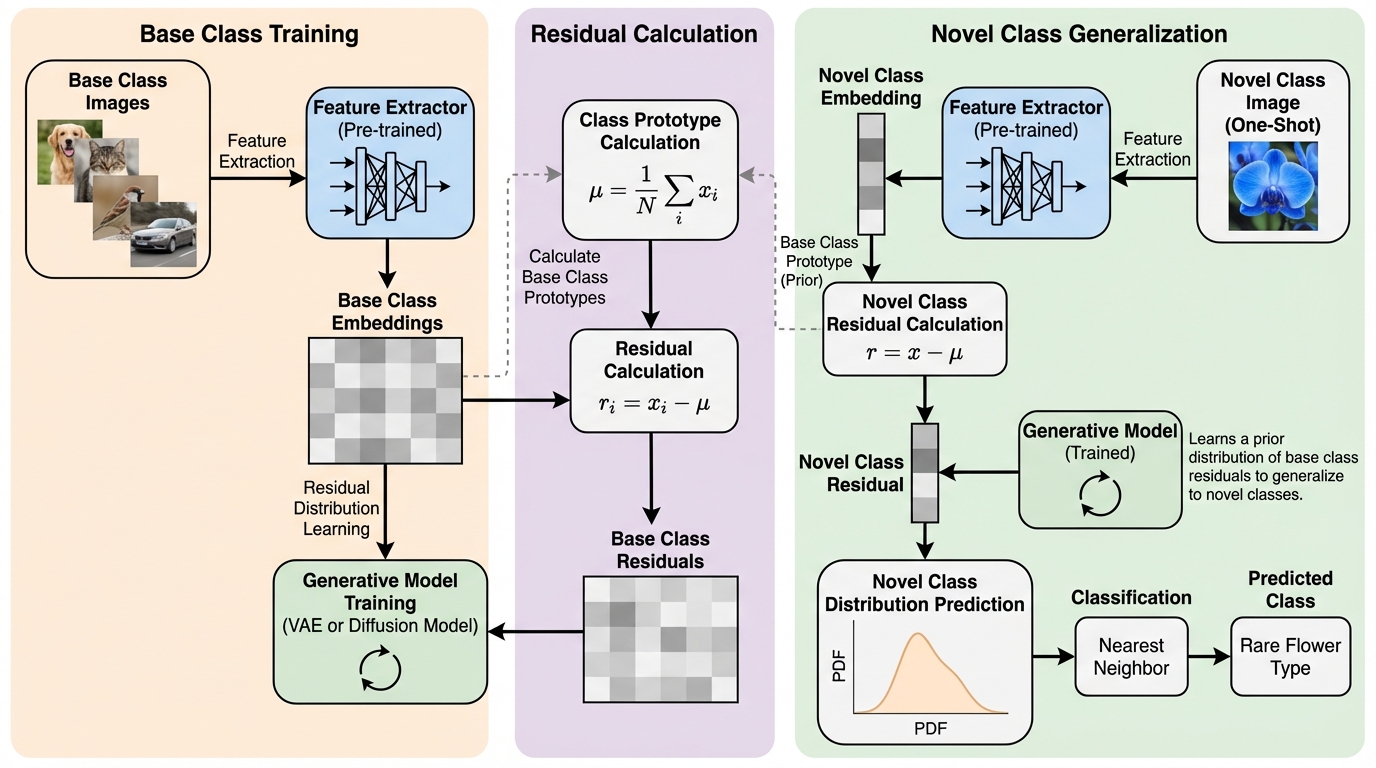
ワンショットクラス増分学習のための特徴空間生成モデル
本研究は、わずか1枚の画像から新しい概念を学習する「ワンショットクラス増分学習(1SCIL)」において、データの極端な不足とクラス分布の複雑さに対応するため、特徴空間上での生成モデルを活用する新手法「Gen1S」を提案した。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究は、わずか1枚の画像から新しい概念を学習する「ワンショットクラス増分学習(1SCIL)」において、データの極端な不足とクラス分布の複雑さに対応するため、特徴空間上での生成モデルを活用する新手法「Gen1S」を提案した。
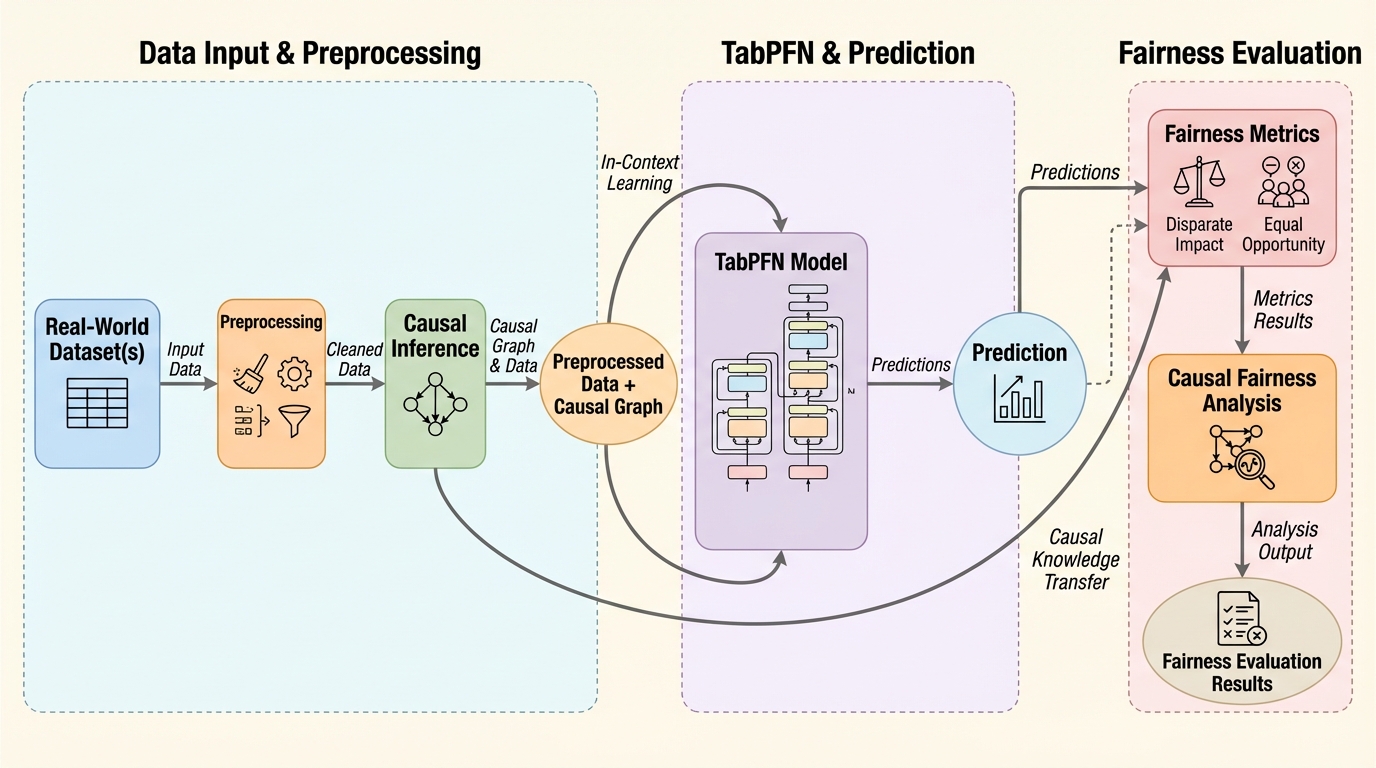
本研究は、構造的因果モデル(SCM)を用いた膨大な合成データで事前学習された表形式データ向け基盤モデル「TabPFN」について、予測精度、公平性、および頑健性の観点から包括的な実証評価を行った。
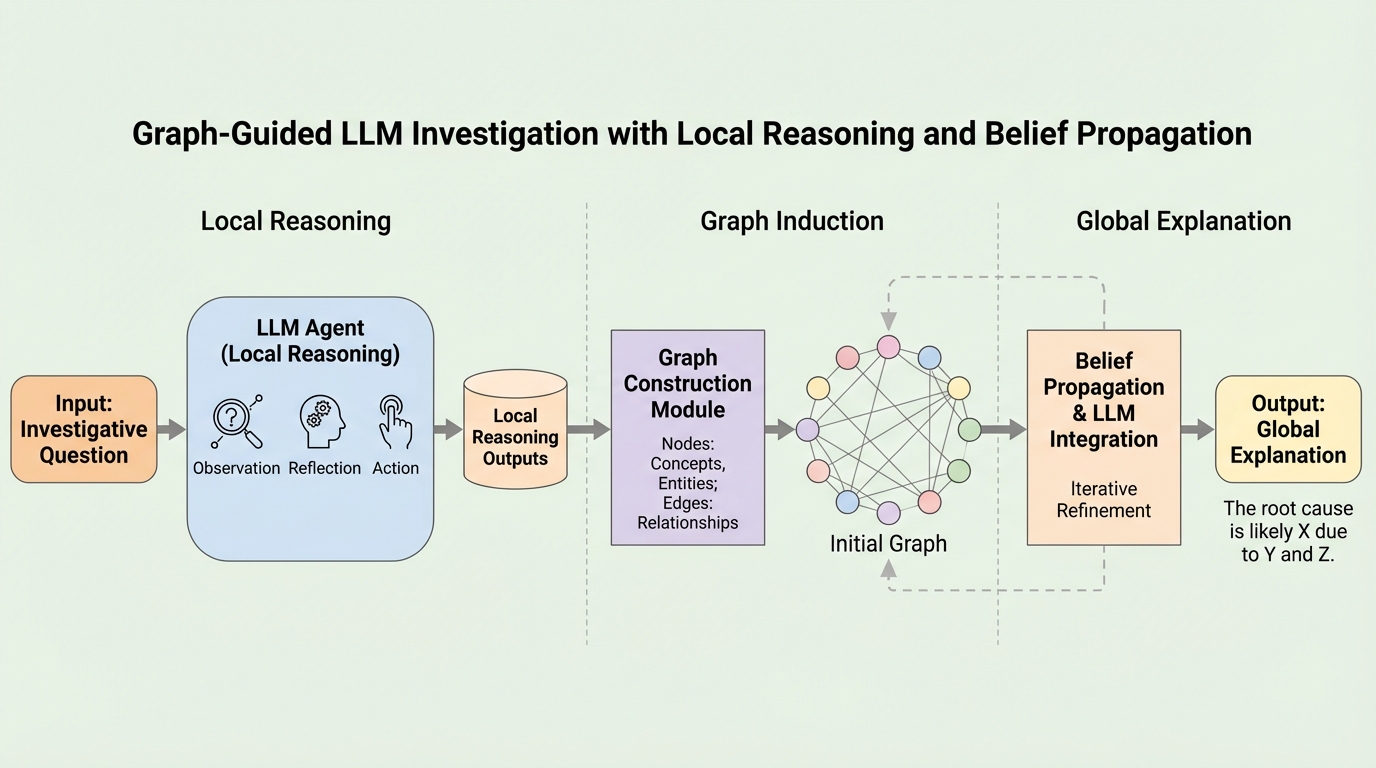
大規模で複雑なITインシデント管理において、従来のLLMエージェントはコンテキスト制限や推論の非決定性により、一度の成功はあっても継続的な信頼性に欠けるという課題を抱えていた。 本研究が提案するEoG(Explanations over Graphs)は、決定論的なコントローラーによる探索管理と、LLMによる局所的なアブダクション推論を分離し、メッセージパッシングを用いたセマンティック信念伝播(SBP)によって動的な判断修正を可能にした。 ITBenchを用いた検証では、従来のReAct手法と比較して、複数回の実行における一貫した正解率を示すMajority@k F1スコアで平均7倍の向上を達成し、複雑な依存関係を持つシステムにおける根本原因特定において極めて高い信頼性を実証した。
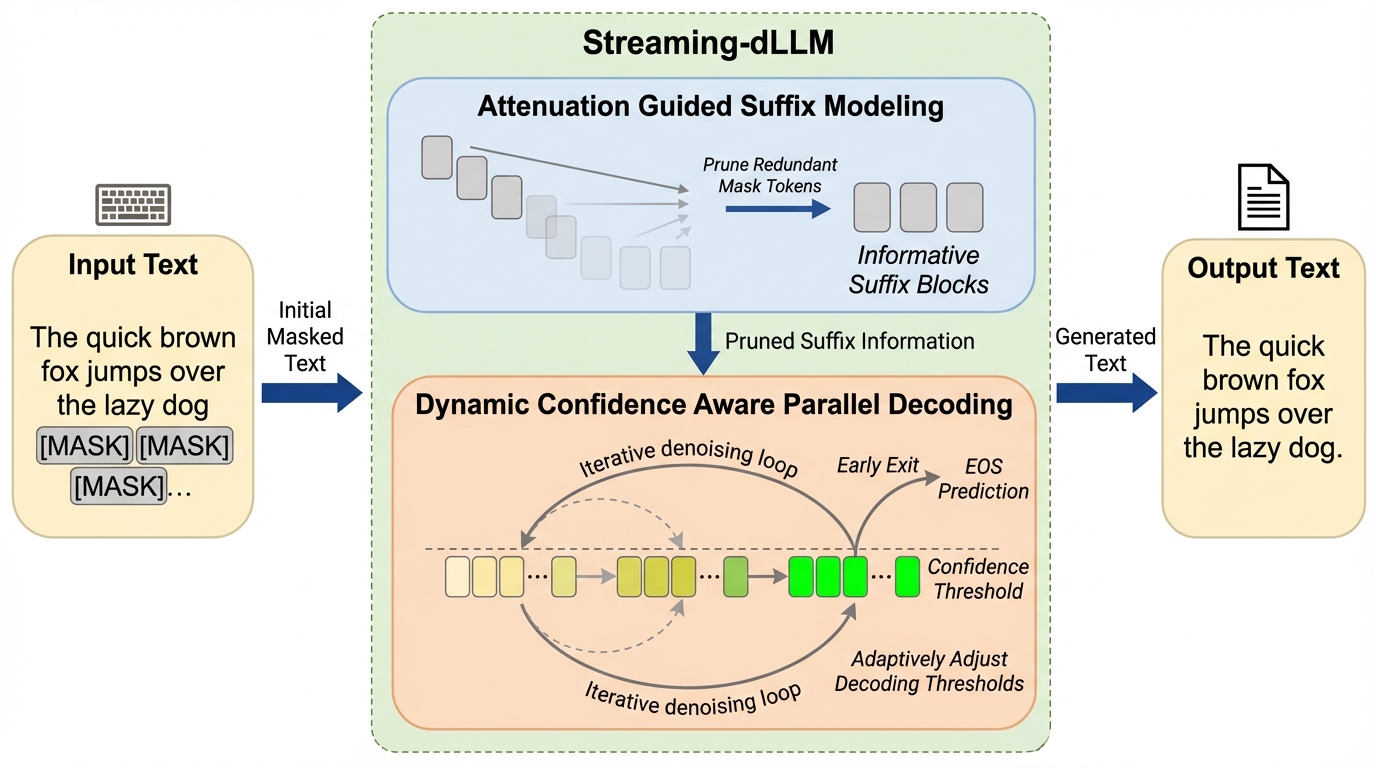
拡散大規模言語モデル(dLLM)は並列デコーディングと双方向アテンションにより高い一貫性を持つが、自己回帰型モデルと比較して推論速度が大幅に遅いという課題がある。 本研究が提案するStreaming-dLLMは、空間的な冗長性を排除する「減衰誘導サフィックスモデリング」と、時間的な非効率性を改善する「動的信頼度認識並列デコーディング」を導入した学習不要のフレームワークである。 検証の結果、生成品質を維持したまま最大68.2倍の推論加速を達成し、既存の手法を大幅に上回るスループットと競争力のある精度を両立することに成功した。
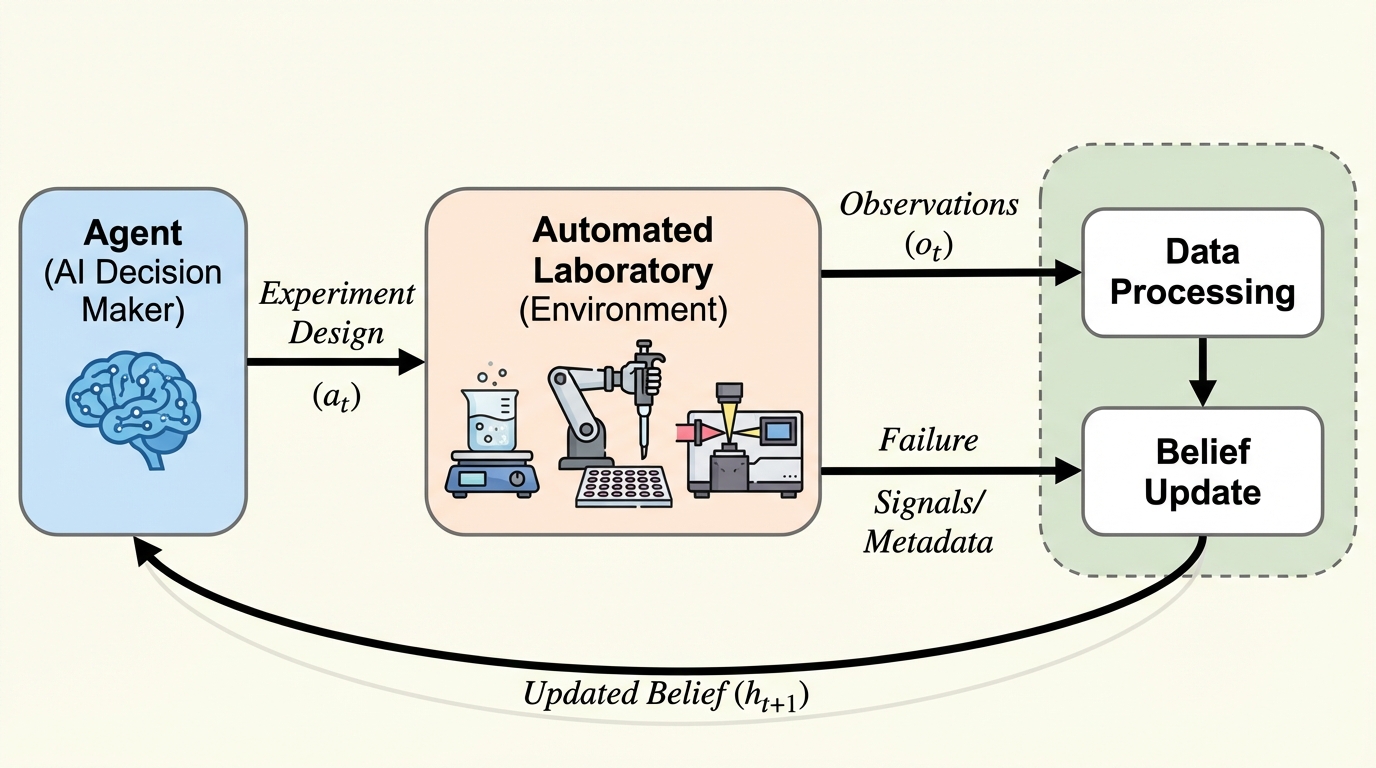
1. 自律型実験室(SDL)は、実験設計、自動実行、データ駆動型の意思決定を統合する仕組みであり、高コストな試行、ノイズや遅延のあるフィードバック、厳格な安全性制約、そして非定常性が存在する物理環境において、エージェントAIの能力を試す重要な場となっている。
本研究では、複雑なアクションRPG『Dark Souls III』の戦闘を「カメラ操作」「ターゲットロック」「移動」「回避」「回復・攻撃判断」という5つの再利用可能なスキルに分解し、それらを有向スキルグラフとして構造化することで、従来の単一ネットワーク手法を圧倒する学習効率と環境適応能力を実現しました。
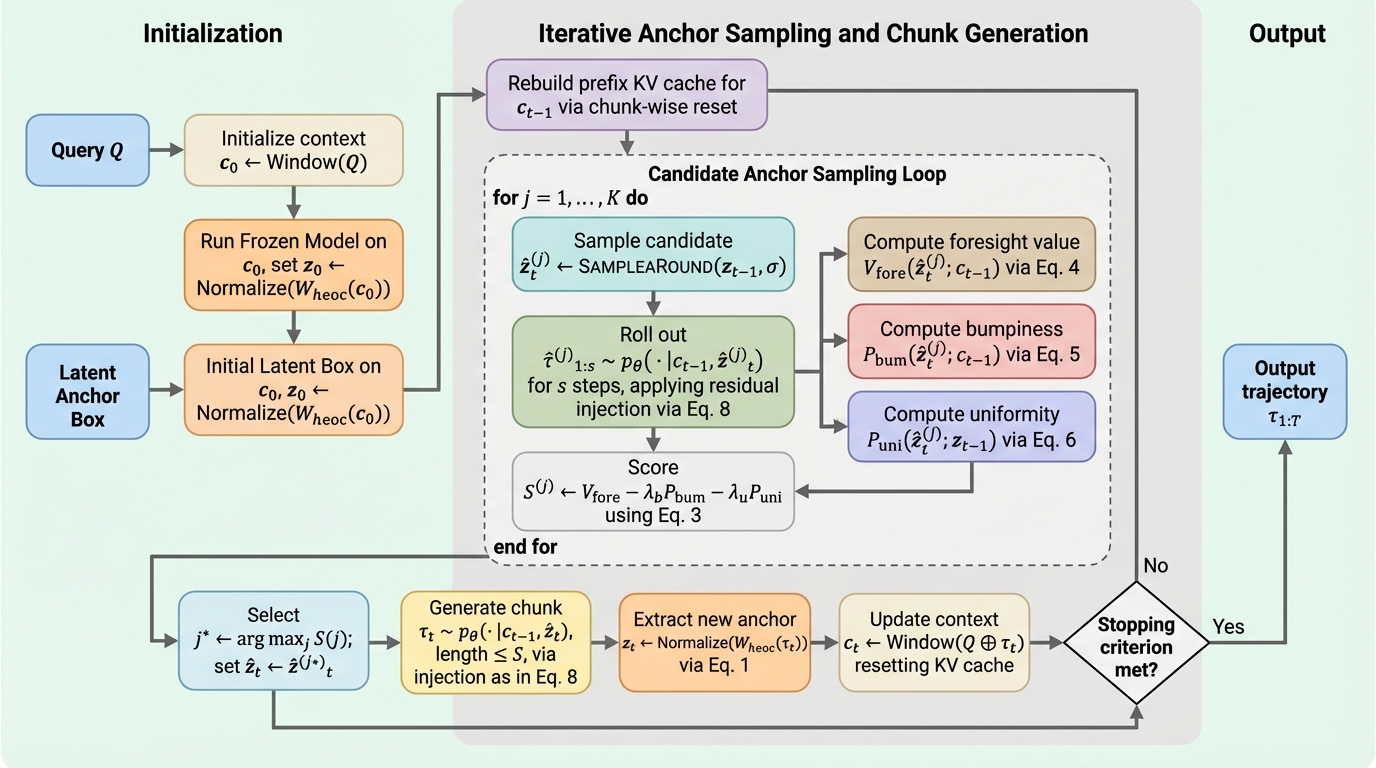
大規模言語モデルの推論能力を向上させるための推論時計算量の拡張において、従来の強化学習やサンプリング手法は膨大な学習コストやメモリ消費、推論経路の重複といった深刻な課題を抱えていましたが、本研究が提案する「TGR(The Geometric Reasoner)」は、追加学習を一切必要とせず、推論過程をチャンク単位に分割してメモリ消費を抑えつつ、潜在空間での多様体情報を活用した「潜在的予見探索」を行う革新的なフレームワークです。 具体的には、推論を短いチャンクに分割し、各境界で潜在アンカーを抽出・サンプリングして、予見スコア、軌跡の滑らかさを表す凹凸ペナルティ、多様性を促す一様性正則化からなる幾何学的スコアで最適な経路を選択し、低ランクの残差注入によってモデルを制御することで、KVキャッシュのメモリ消費を文脈長に対して線形に保ちながら、長大で論理的一貫性のある多様な推論を効率的に生成することに成功しました。 Qwen3-8Bを用いた数学やコード生成の難解なベンチマークでの検証では、Pass@k曲線の曲線下面積(AUC)を最大13ポイント向上させ、計算負荷をわずか1.1倍から1.3倍程度に抑えつつ、既存の強化学習ベースの手法(GRPOやSimKO)を凌駕する高い網羅性と予算効率を実証しており、モデルの重みを更新することなく推論時の工夫のみで高度な探索を実現できる実用性の高い手法であることを示しました。
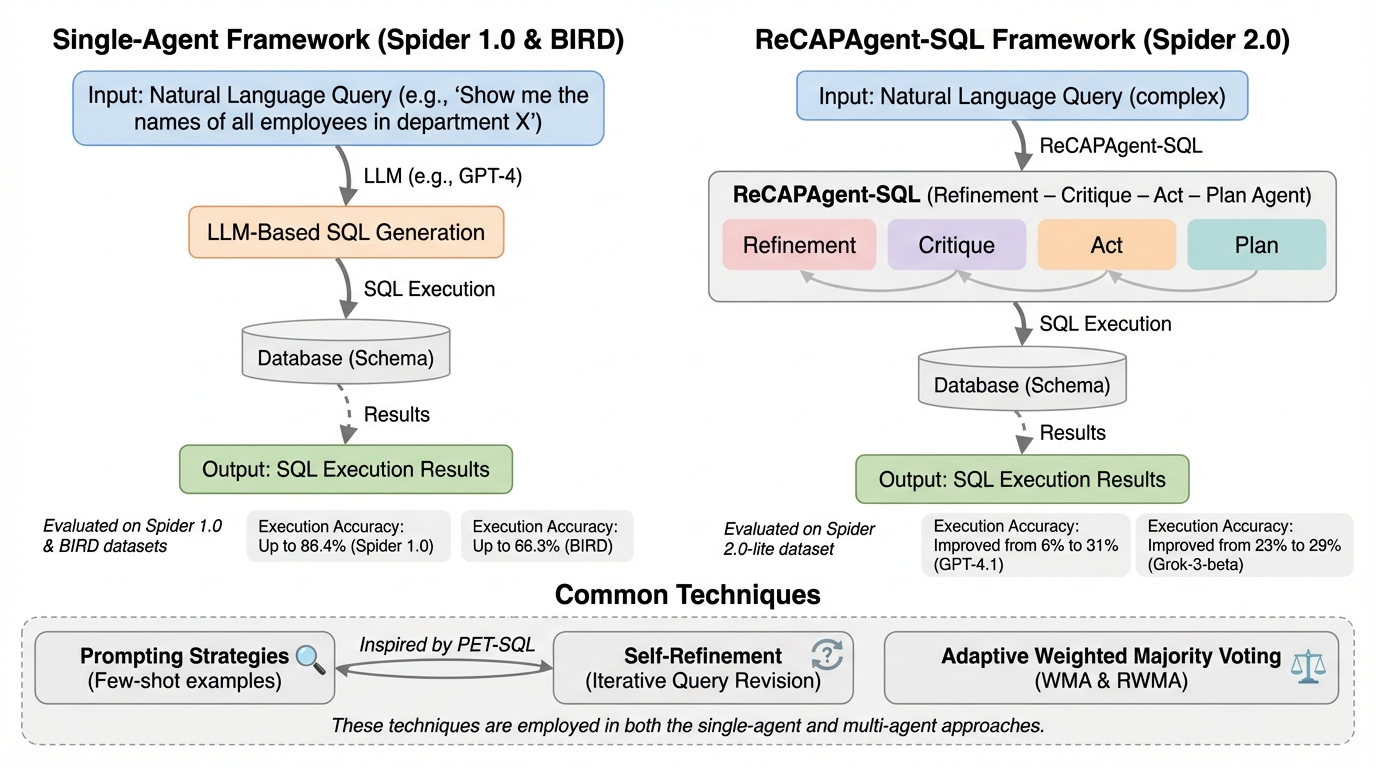
本研究では、大規模言語モデル(LLM)を用いたText-to-SQLの精度を向上させるため、単一エージェントの自己改善とアンサンブル投票を統合したSSEVパイプライン、および複雑な企業データベースに対応する多機能エージェントフレームワークであるReCAPAgent-SQLを提案しました。
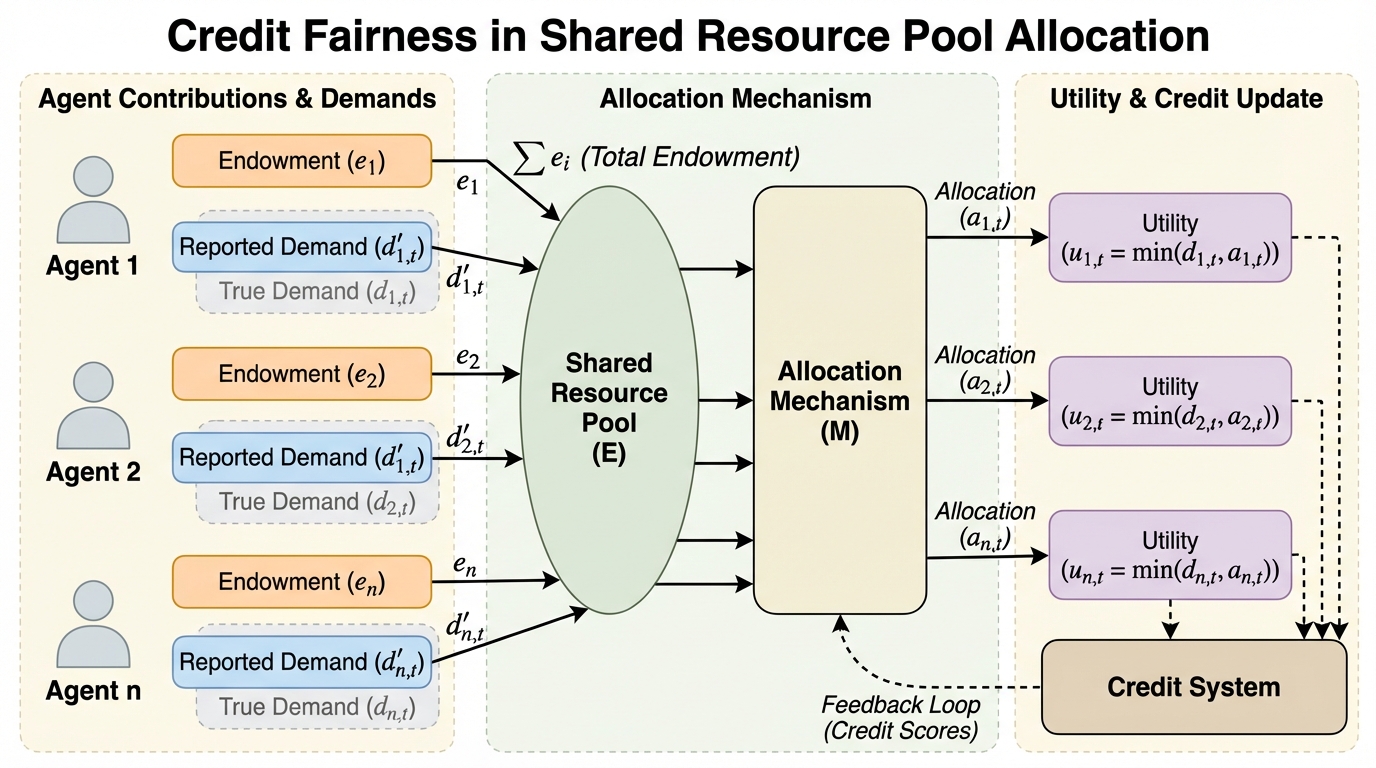
本研究は、計算資源やエネルギーなどの共有リソースを時間経過とともに配分する際、過去にリソースを貸し出したエージェントが将来優先的に報われることを保証する「クレジット公平性」という新しい概念を提案した。
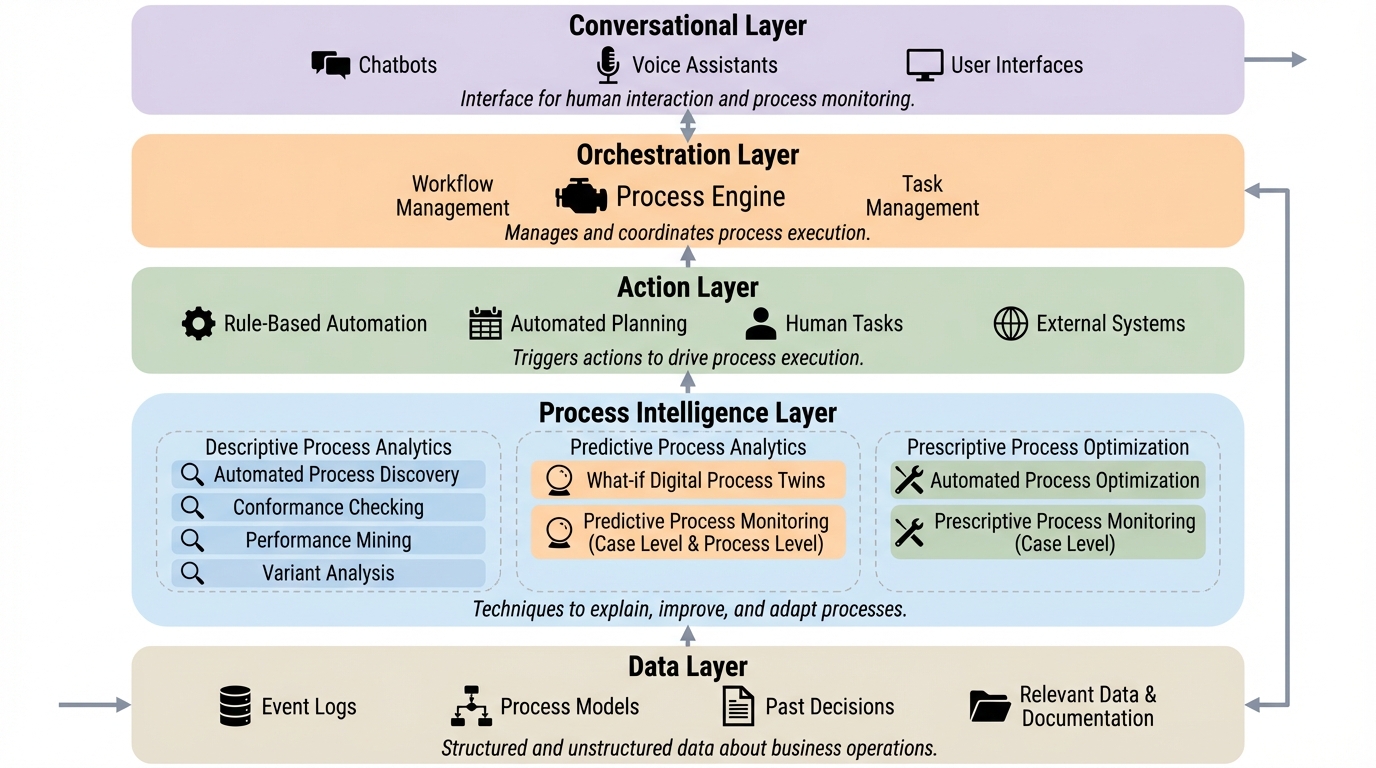
エージェント型ビジネスプロセス管理システム(A-BPMS)は、従来のルールベースの自動化を超え、生成AIやエージェント型AIを活用して自律的なプロセスの実行と最適化を目指す新しいプラットフォームの概念である。