公平性のレンズを通した因果的事前学習:TabPFNに関する実証的研究
本研究は、構造的因果モデル(SCM)を用いた膨大な合成データで事前学習された表形式データ向け基盤モデル「TabPFN」について、予測精度、公平性、および頑健性の観点から包括的な実証評価を行った。
TL;DR(結論)
本研究は、構造的因果モデル(SCM)を用いた膨大な合成データで事前学習された表形式データ向け基盤モデル「TabPFN」について、予測精度、公平性、および頑健性の観点から包括的な実証評価を行った。 検証の結果、TabPFNおよびその微調整版であるFT-TabPFNは、従来の機械学習モデルと比較して極めて高い予測精度を維持しつつ、学習データに含まれる偽の相関(スプリアス相関)に対して強い耐性を示すことが明らかになった。 しかし、アルゴリズムの公平性に関する改善は限定的かつ不規則であり、特に選択バイアスが関わる非ランダムな欠損(MNAR)を伴う共変量シフトの下では、因果的な事前学習のみでは十分な公平性を担保できないことが示唆された。
なぜこの問題か
アルゴリズムの公平性は、機械学習モデルが融資審査、採用、医療診断といった社会的に重要な意思決定プロセスに導入される際、特定の保護されたグループに対して差別的な予測を行わないようにするための極めて重要な懸念事項である。 従来の機械学習モデルは、主に統計的な相関関係を利用して高い予測精度を達成しようとするが、不完全なデータセットや不均衡なデータセットに起因する偽の相関(スプリアス相関)に対して非常に脆弱であるという課題を抱えている。 特に訓練データが限られている場合、モデルは「オッカムの剃刀」に従ってより単純な仮説を好む傾向があり、これがバイアスのあるデータセットにおいては、因果関係のない「近道」となる特徴量(例えば、人種や性別、居住地域の郵便番号など)を予測の根拠として利用してしまう原因となる。 また、データ収集時の選択バイアスによって発生する共変量シフトは、訓練データとテストデータの分布を乖離させ、モデルが特定の文脈に依存した不安定な相関を学習してしまうリスクをさらに高める。…
核心:何を提案したのか
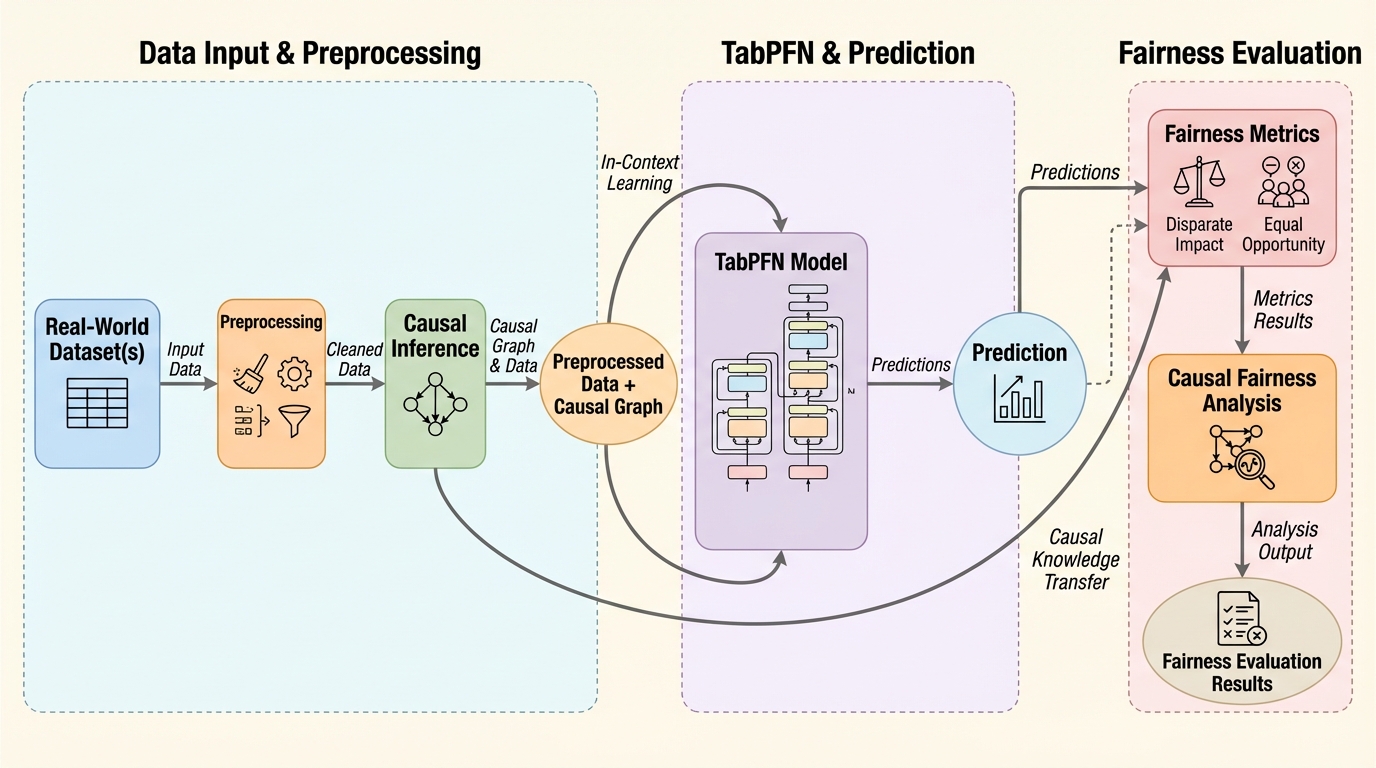
本研究では、表形式データの教師あり学習のためのトランスフォーマー型基盤モデルであるTabPFN、およびその微調整版であるFT-TabPFNの公平性と頑健性を実証的に評価した。 TabPFNは、個別のデータセットごとにゼロから学習を行う従来の分類器とは根本的に異なり、構造的因果モデル(SCM)から生成された数百万もの合成タスクを用いて一度だけ事前学習される。 これらの合成タスクは、多様な因果構造、ノイズレベル、特徴量の不均衡などを反映するように設計されており、モデルは特定のデータセット固有の相関ではなく、因果メカニズム上の事後予測分布を近似することを学習する。 推論時には、大規模言語モデル(LLM)のインコンテキスト学習(ICL)と同様に、タスク固有の少量の実データのみをコンテキストとして使用して予測を行う仕組みとなっている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related