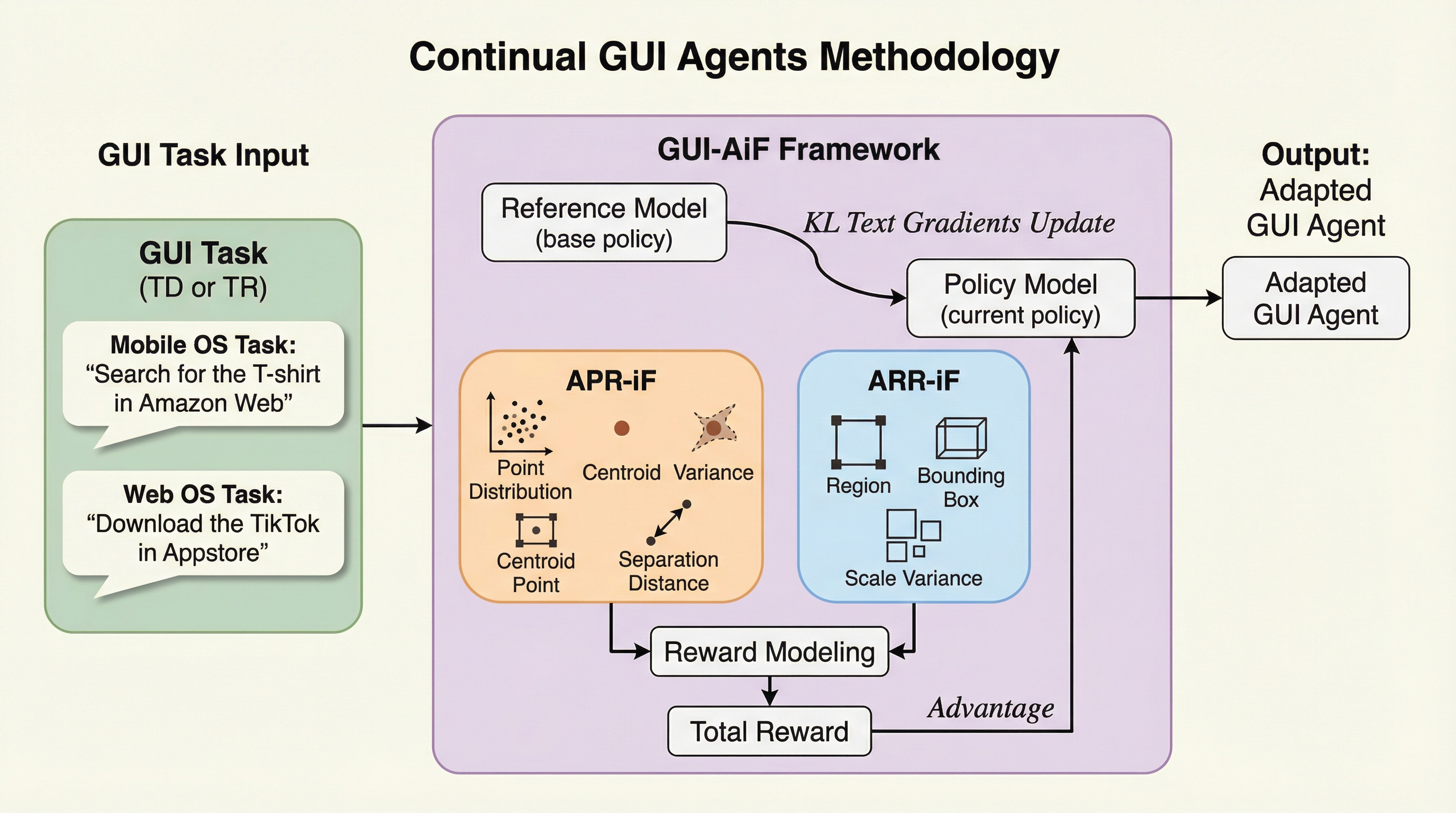
継続的GUIエージェント
現代のデジタル環境は、OSの更新やデバイスの多様化、解像度の変化によって常にデータの分布が変動する「流動的(Flux)」な状態にあり、固定されたデータセットで学習した従来のGUIエージェントでは、未知のドメインや高解像度環境において性能が著しく低下するという課題がある。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
現代のデジタル環境は、OSの更新やデバイスの多様化、解像度の変化によって常にデータの分布が変動する「流動的(Flux)」な状態にあり、固定されたデータセットで学習した従来のGUIエージェントでは、未知のドメインや高解像度環境において性能が著しく低下するという課題がある。
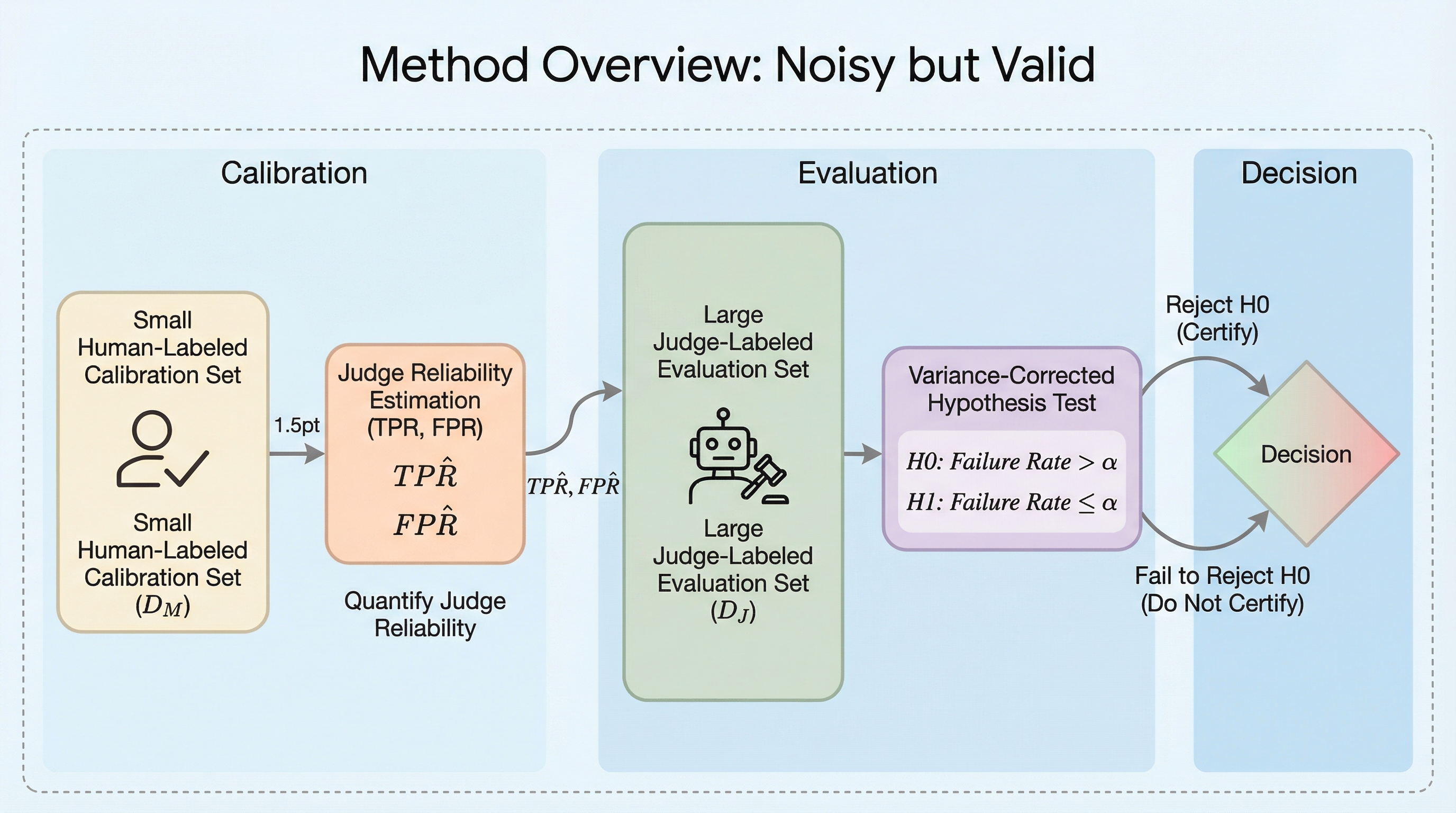
大規模言語モデル(LLM)の安全性を評価する「LLM-as-a-Judge」は、拡張性に優れる一方で評価者の誤りやバイアスが統計的信頼性を損なうという深刻な課題を抱えていたが、本研究は少量の人間によるラベル付きデータを用いて評価者の特性(真陽性率と偽陽性率)を精密に推定し、大規模な自動評価データセットに対して分散補正を適用する新しい統計的枠組み「Noisy but Valid」を提案することで、この問題を根本から解決した。 この枠組みは、評価者が不完全であっても、安全でないモデルを誤って合格させてしまう「第一種過誤」を理論的に有限サンプル内で厳密に制御することを保証しており、従来の人間による直接的な評価手法と比較して、評価者の品質が一定の基準を超えている場合には統計的な検出力を大幅に向上させることが可能であり、評価コストの劇的な削減と信頼性の向上を同時に達成している。 既存の予測駆動型推論(PPI)とは異なり、評価者のエラープロファイルを明示的にモデル化することで、評価プロセスの透明性と診断能力を確保しており、実務者が評価者の信頼性を客観的に判断し、データセットの規模や認定要件に応じた最適な評価プロトコルを設計するための理論的かつ実践的な基盤を提供している点が、本研究の最も重要な貢献である。
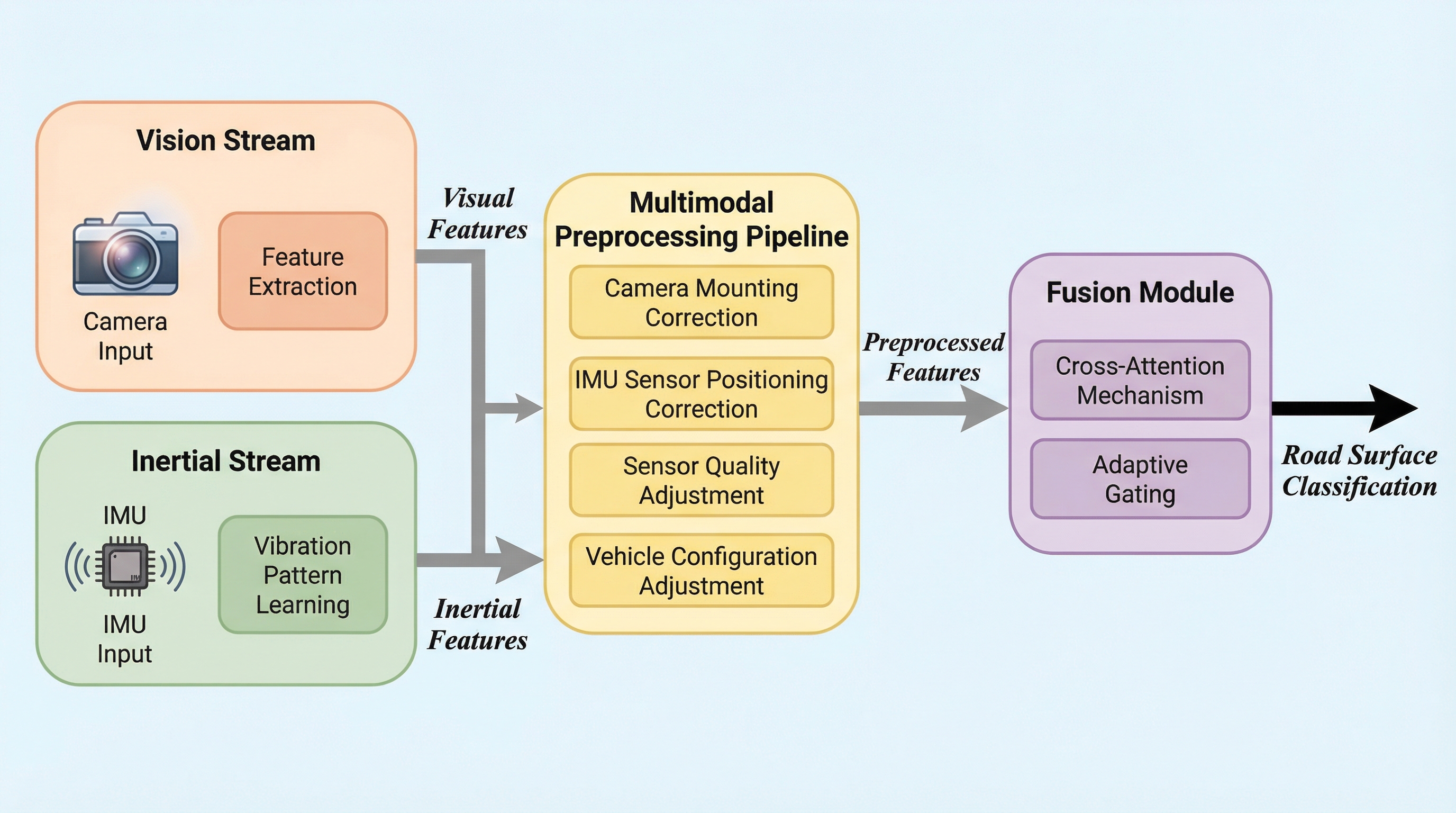
従来の路面分類技術は、日中の良好な視界を前提とした単一センサーの手法が主流であり、夜間や豪雨、未舗装路といった過酷な実環境下での堅牢性や汎用性に課題があった。本研究では、カメラ画像と慣性計測装置(IMU)のデータを統合し、環境変化に柔軟に対応できる新しいマルチモーダル学習フレームワークを提案することで、視覚情報が制限される条件下でも安定した認識を実現した。 提案手法の核心は、軽量な双方向クロスアテンション機構と適応型ゲート融合モジュールを導入した点にあり、画像と振動の情報を相互に補完させながら、状況に応じて各センサーの寄与度を動的に調整する。これにより、特定のセンサーがノイズの影響を受けた場合でも、もう一方の情報を優先的に活用することで、高精度かつ一貫性のある路面判別を継続することが可能となった。 検証のために構築された大規模データセット「ROAD」は、実世界の多様な天候や照明条件、連続走行シーケンス、さらには合成データを含んでおり、従来のベンチマークを大幅に上回る性能向上を実証した。この成果は、安価なセンサー構成での高度な路面理解を可能にし、車両の走行環境に応じた適切な予防保守システムの実現や、自動運転技術の信頼性向上に大きく貢献するものである。
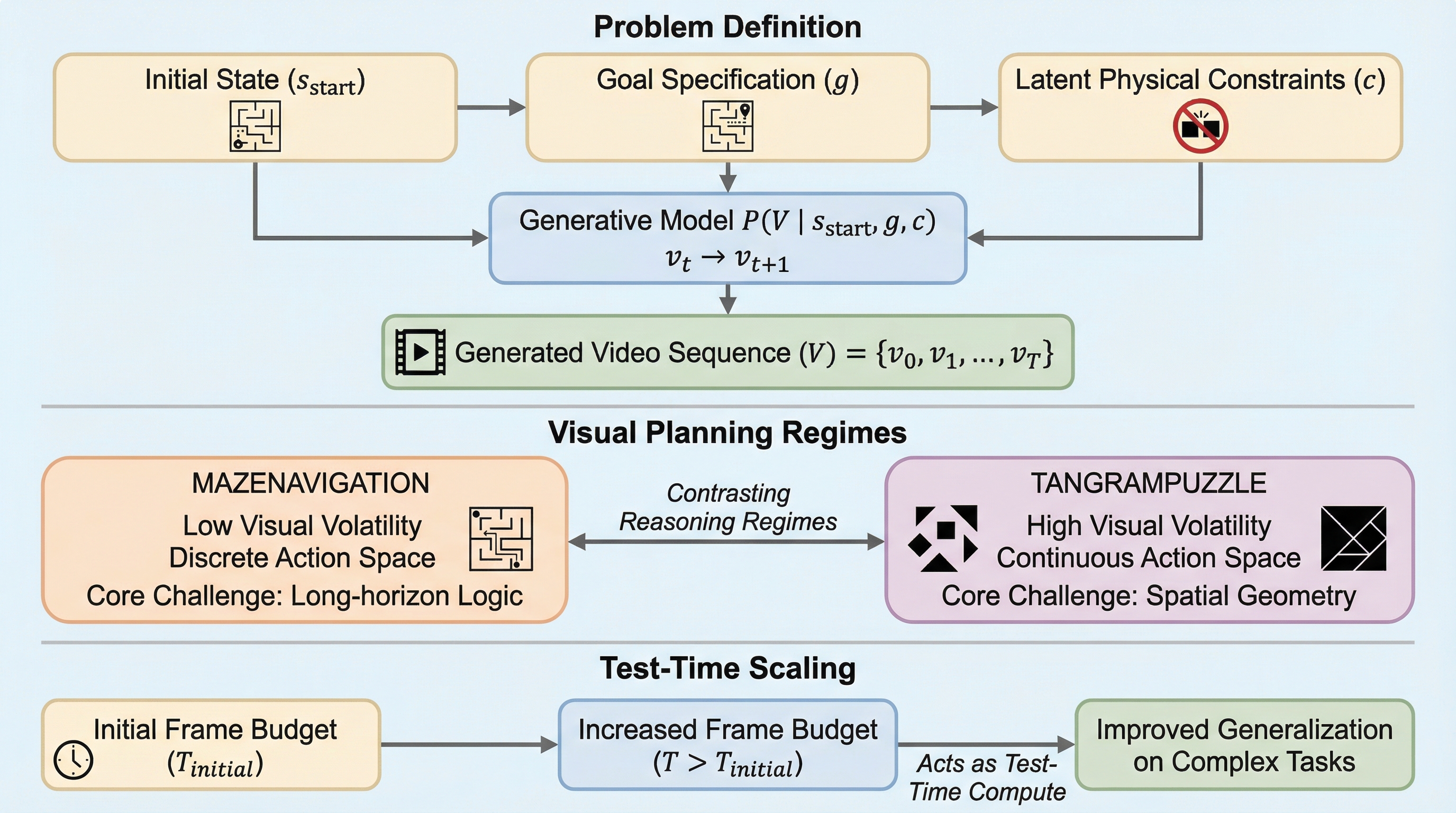
従来のマルチモーダル大規模言語モデル(MLLM)は、テキストベースの推論において優れた成果を収めてきましたが、物理的なダイナミクスや精密な空間的理解を必要とするタスクには依然として課題を抱えています。
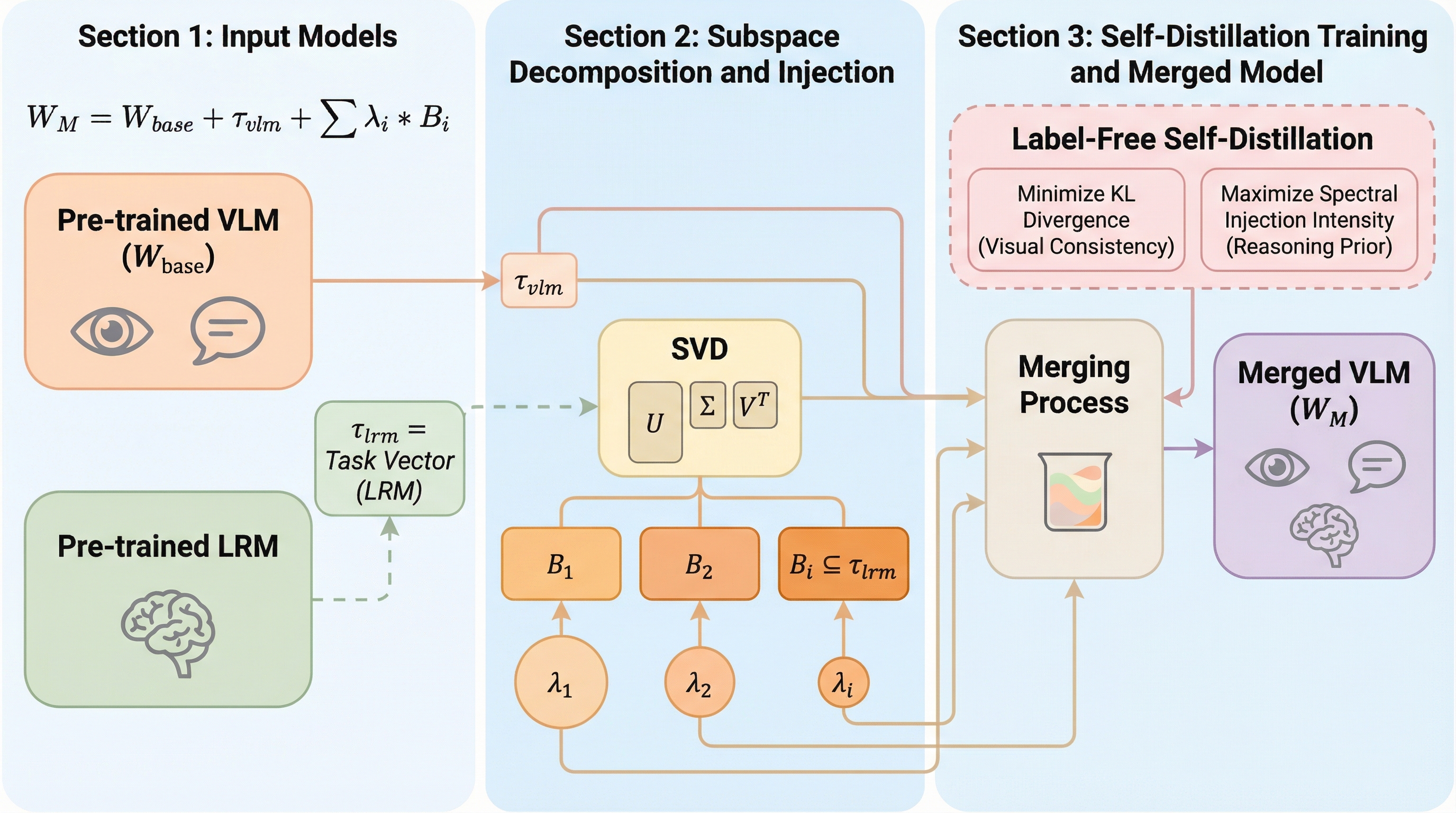
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚認識能力と推論能力の間に深刻なトレードオフが生じるという課題がありました。本研究で提案されたFRISMは、特異値分解(SVD)を用いて推論モデルのタスクベクトルをサブスペース単位に分解し、学習可能なゲートを通じて各成分の注入強度を適応的に調整することで、細粒度な推論能力の注入を実現します。ラベルなしの自己蒸留戦略と二重目的最適化を導入することで、元の視覚能力を損なうことなく、多様な視覚推論ベンチマークにおいて最先端の性能を達成することに成功しました。
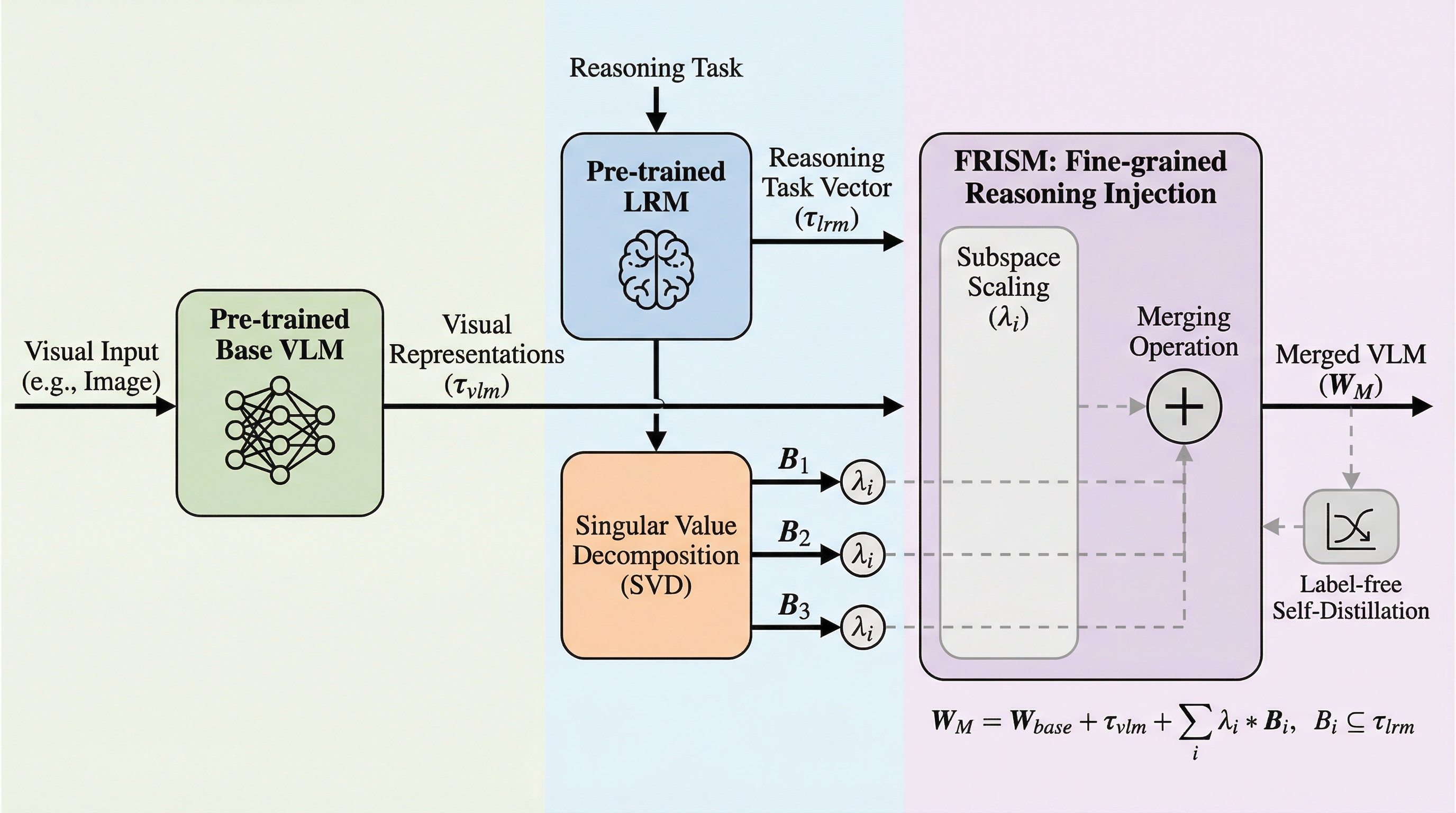
視覚言語モデル(VLM)に大規模推論モデル(LRM)の能力を統合する際、従来の層単位のマージ手法では視覚的な認識能力が損なわれるという課題がありましたが、本研究では特異値分解(SVD)を用いてタスクベクトルをサブスペース単位に分解し、推論能力を細粒度で注入するフレームワーク「FRISM」を提案しました。
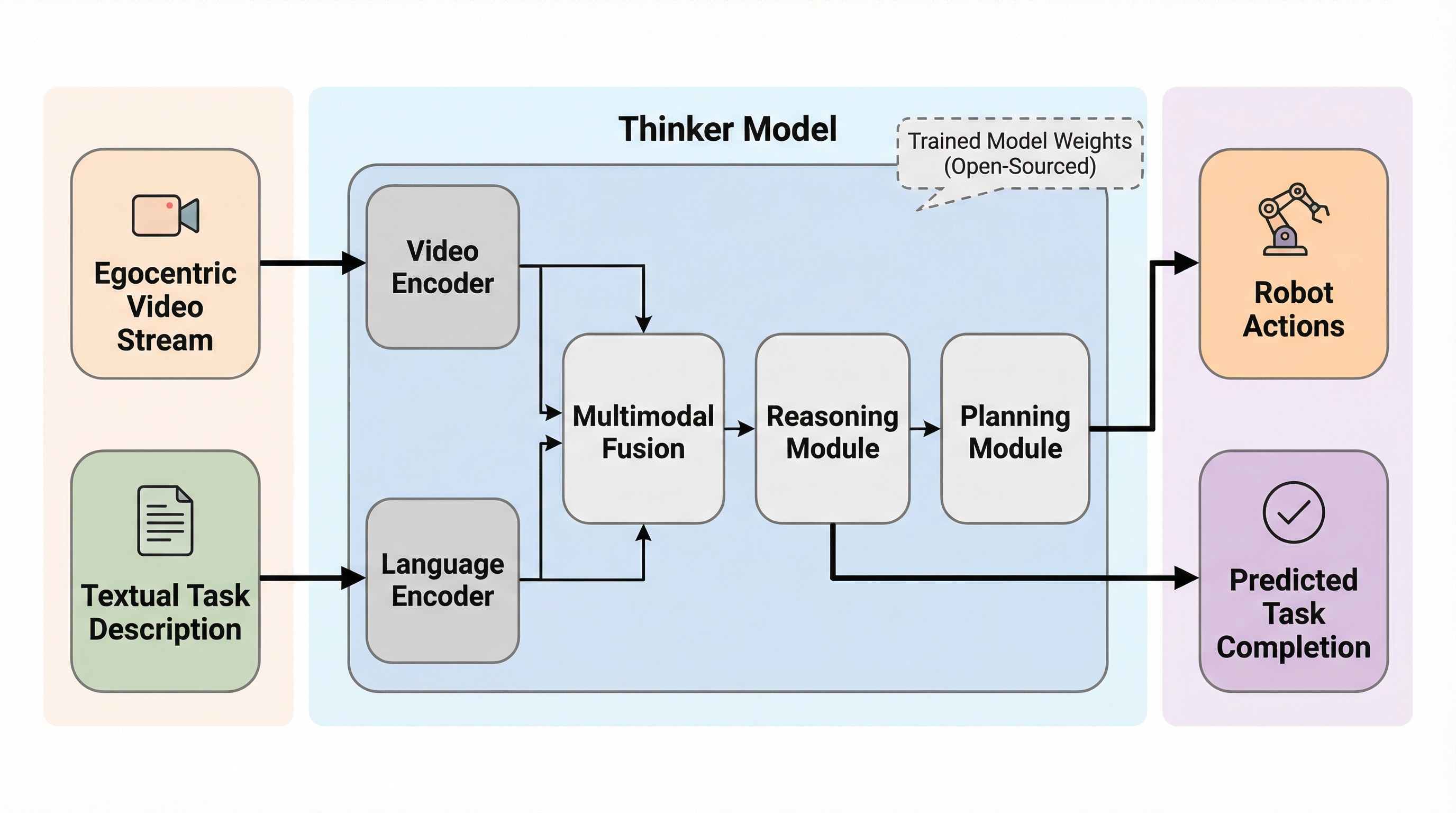
Thinkerは、ロボット工学における視覚と言語の統合を目的とした100億パラメータ規模の基盤モデルであり、従来のモデルが抱えていた三人称視点と一人称視点の混同や、ビデオ終盤情報の見落としといった課題を解決するために開発されました。
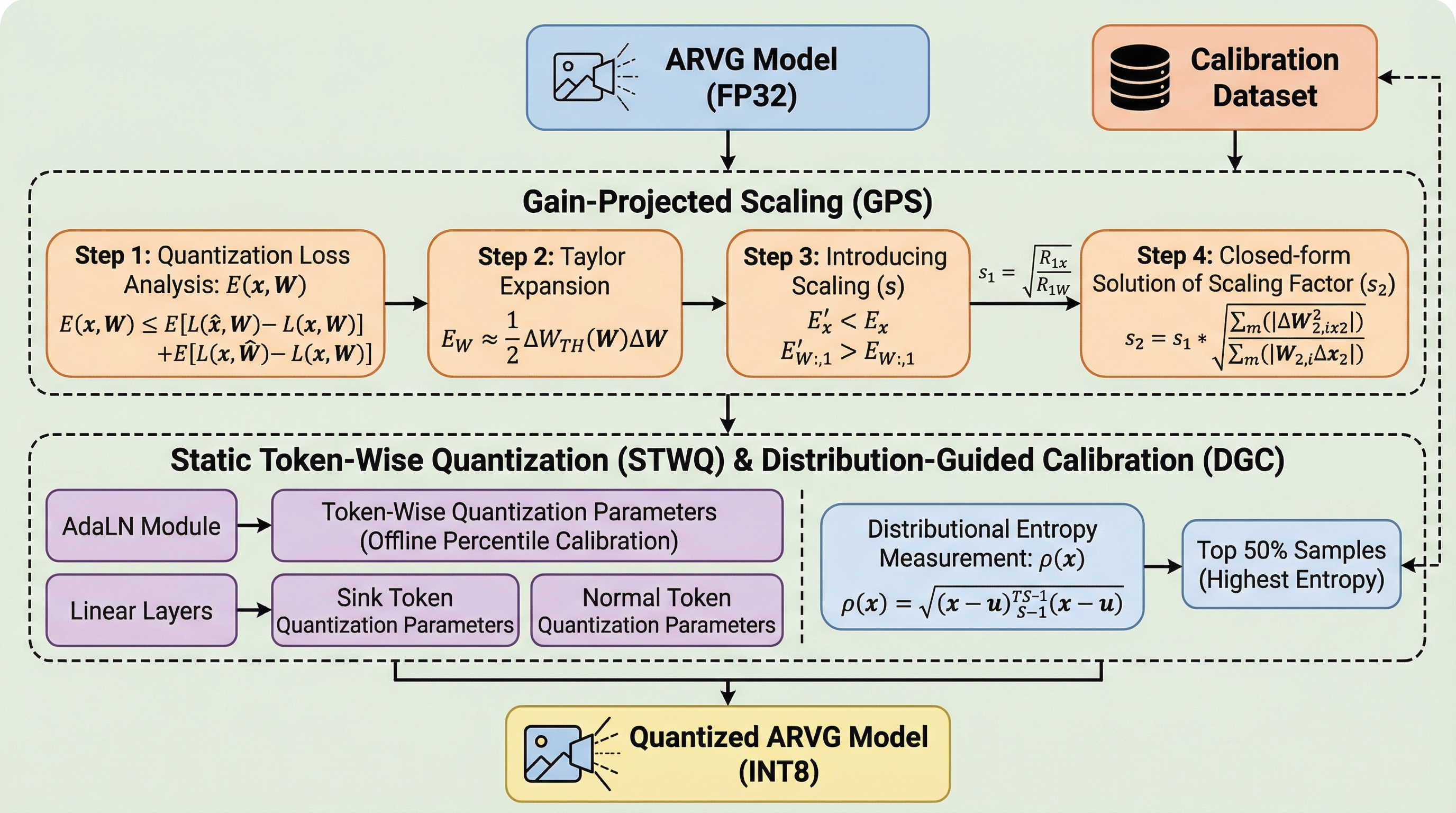
自己回帰型視覚生成(ARVG)モデルは、拡散モデルに匹敵する性能を持つ一方で、巨大なモデルサイズと推論時の計算コストが課題となっており、既存の量子化手法ではチャネル間の外れ値や動的なアクティベーション、サンプル間の分布の不一致を十分に解決できていない。
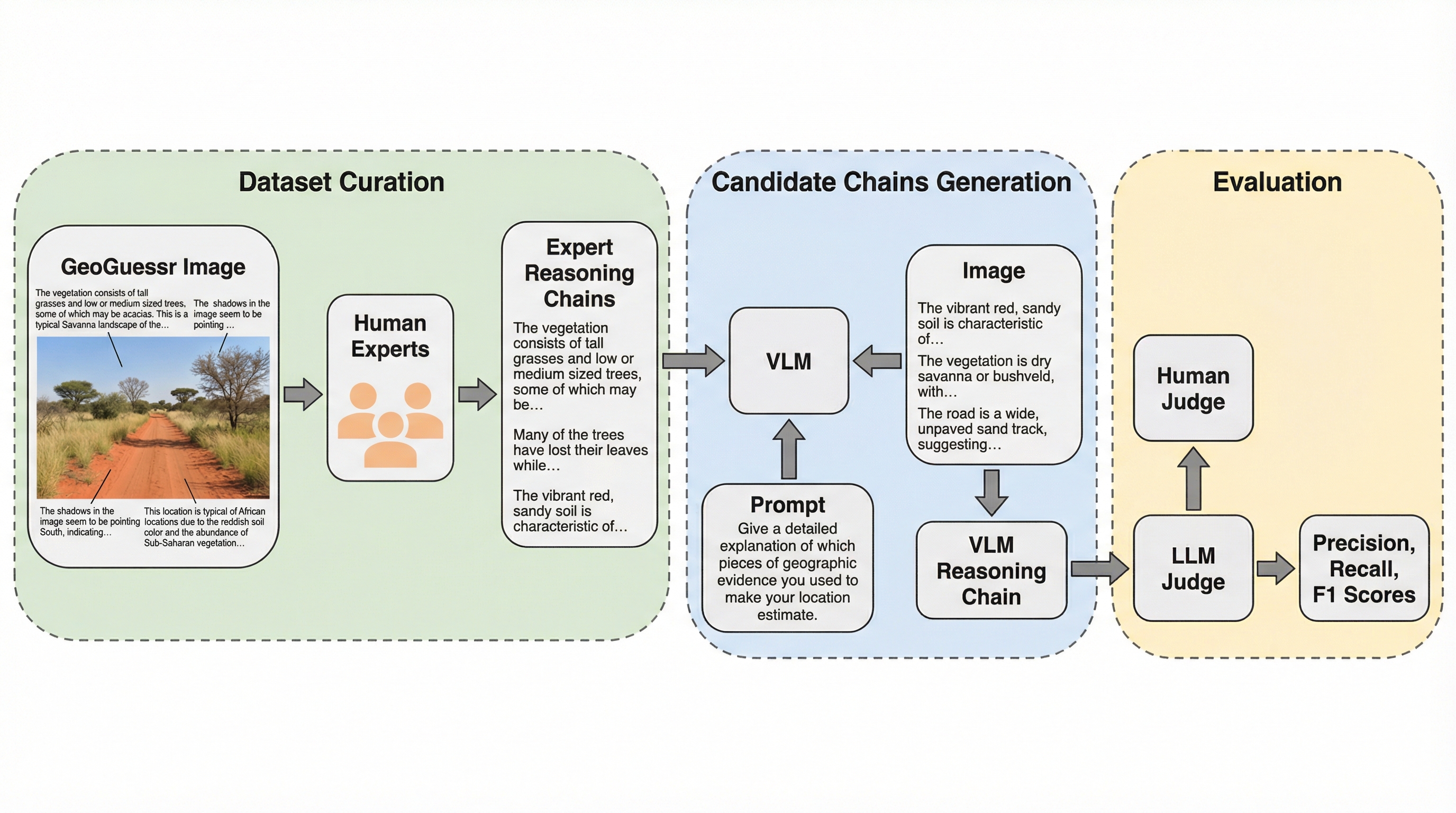
視覚言語モデル(VLM)は写真の撮影場所を特定する精度で人間に匹敵する能力を見せ始めていますが、その予測に至った根拠を説明する際に、画像内に存在しない情報を捏造するハルシネーションが頻発するという深刻な課題を抱えています。
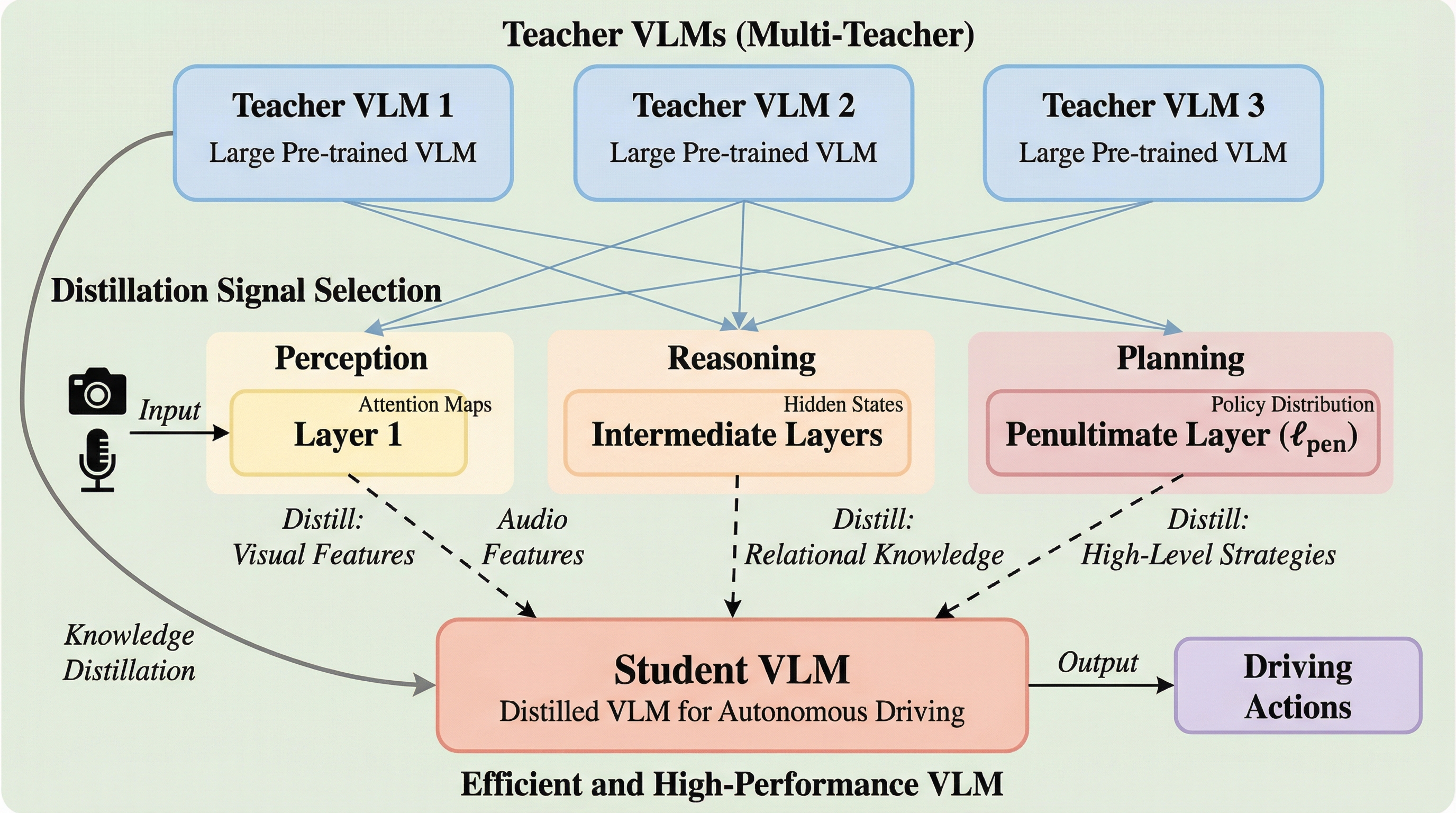
Drive-KDは、自動運転における視覚言語モデル(VLM)の効率化を実現するため、知覚・推論・計画という3つの能力に分解して大規模モデルから小規模モデルへ知識を転移する新しい蒸留フレームワークである。