MATA: マルチエージェント視覚的推論のための学習可能な階層的オートマトンシステム
視覚言語モデルは高い知覚能力を持つ一方で、複雑な推論における「幻覚」やプロセスの不透明さが課題となっており、本研究ではこれを解決するために推論過程を有限状態オートマトンとしてモデル化しました。 提案手法である「MATA」は、学習可能なハイパーエージェントが複数の専門エージェントを動的に切り替える階層構造を採用し、共有メモリを介してエージェント間の高度な協調と競争を実現することで、推論の透明性と精度を両立させています。 9万件の遷移軌跡から構築されたデータセットを用いて微調整された大規模言語モデルを制御塔とすることで、複数の視覚推論ベンチマークにおいて従来手法を凌駕する最高水準の性能を達成し、複雑なタスクにおける新たな基準を提示しました。
TL;DR(結論)
視覚言語モデルは高い知覚能力を持つ一方で、複雑な推論における「幻覚」やプロセスの不透明さが課題となっており、本研究ではこれを解決するために推論過程を有限状態オートマトンとしてモデル化しました。 提案手法である「MATA」は、学習可能なハイパーエージェントが複数の専門エージェントを動的に切り替える階層構造を採用し、共有メモリを介してエージェント間の高度な協調と競争を実現することで、推論の透明性と精度を両立させています。 9万件の遷移軌跡から構築されたデータセットを用いて微調整された大規模言語モデルを制御塔とすることで、複数の視覚推論ベンチマークにおいて従来手法を凌駕する最高水準の性能を達成し、複雑なタスクにおける新たな基準を提示しました。
なぜこの問題か
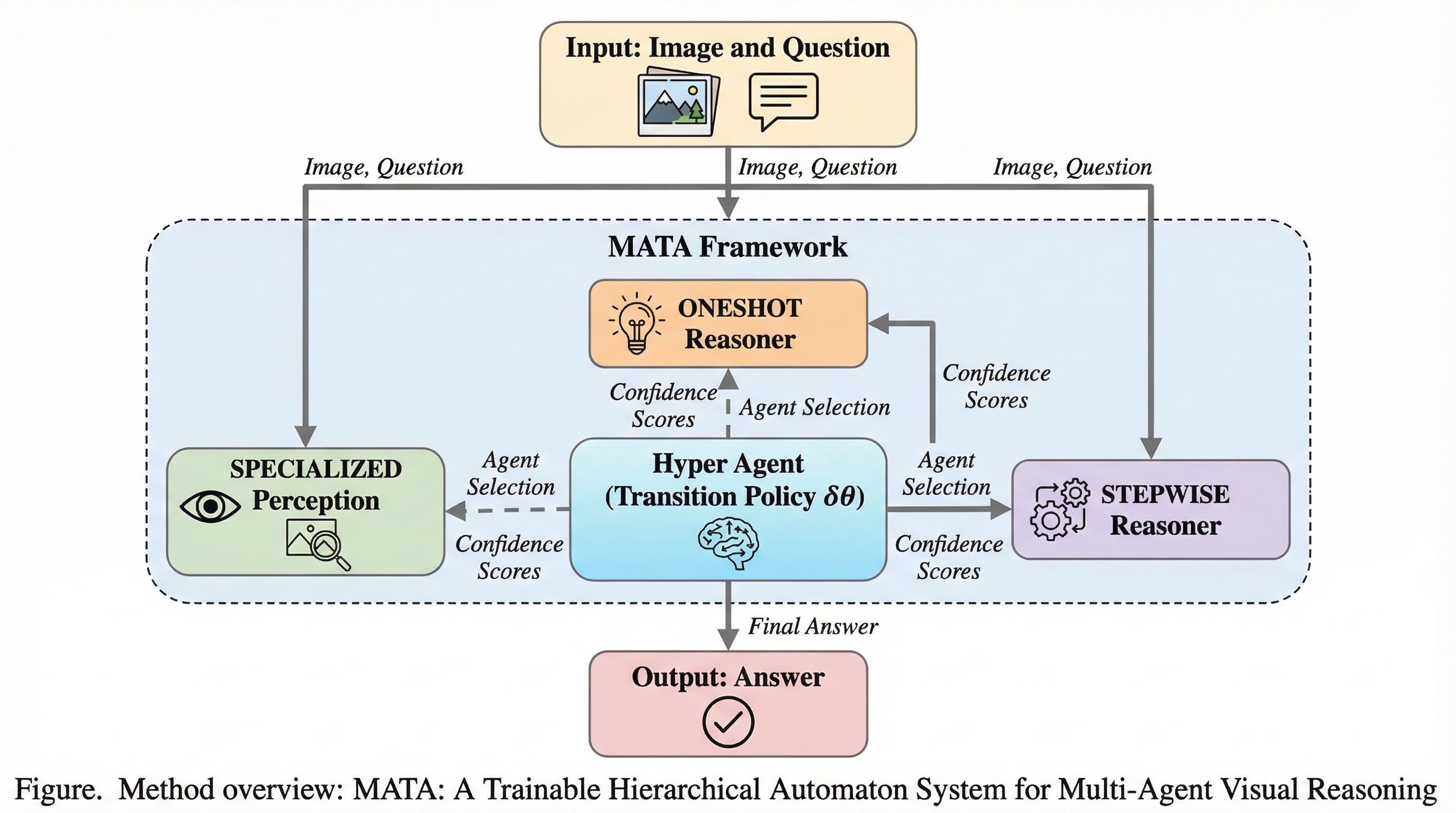
近年の視覚言語モデルは、画像の内容を読み取る知覚能力においては目覚ましい発展を遂げていますが、その内部で行われる推論プロセスは依然としてブラックボックスであり、説明が困難であるという根本的な問題を抱えています。特に、複数の物体間の空間的な位置関係の特定や、特定の属性を持つ物体の正確な計数、あるいは多段階の論理ステップを必要とする複雑なクエリに対しては、事実とは異なる回答を生成する「幻覚」が頻繁に発生します。これに対し、タスクを複数の段階に分解して処理する構成的な手法も提案されていますが、その多くは単一のエージェントによる処理や、人間が事前に設計した固定的なパイプラインに依存しており、状況に応じた柔軟な判断ができません。既存の構成的手法における大きな欠点は、相補的な能力を持つ複数のエージェントをいつ協調させるべきか、あるいは機能が重複するエージェント間でどのように競争させて最適な解を選ぶべきかという意思決定を、モデル自身が行えない点にあります。…
核心:何を提案したのか
本研究では、視覚的推論のための学習可能な階層的オートマトンシステムである「MATA」を提案しました。このシステムの核心は、推論プロセスを有限状態オートマトンとしてモデル化し、その最上位レベルの遷移制御を、学習可能な「ハイパーエージェント」に委ねるという設計思想にあります。MATAは、複数の専門エージェントをオートマトン内の「状態」として定義し、ハイパーエージェントが現在の状況や過去の履歴に基づいて、次にどのエージェントを起動すべきかを動的に決定します。これにより、従来の手法では困難であった、エージェント間の高度な協調と、最適な解を導き出すための競争を同時に実現しています。システムの構造は二層の階層性を持っており、上位レベルではハイパーエージェントがエージェント間の遷移を司り、下位レベルでは各エージェントが「サブオートマトン」として、ルールベースの精密なマイクロコントロールを実行します。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related