幾何学的形態測定学の機械学習への応用におけるプロクラステス汚染について
幾何学的形態測定学(GMM)を機械学習に統合する際、データ分割前に全標本を一括で整列させる標準的な一般化プロクラステス解析(GPA)が、訓練データとテストデータの間に不適切な統計的依存関係を生じさせ、予測精度を不当に高く見積もる「プロクラステス汚染」を引き起こすことを数学的・実験的に解明しました。
TL;DR(結論)
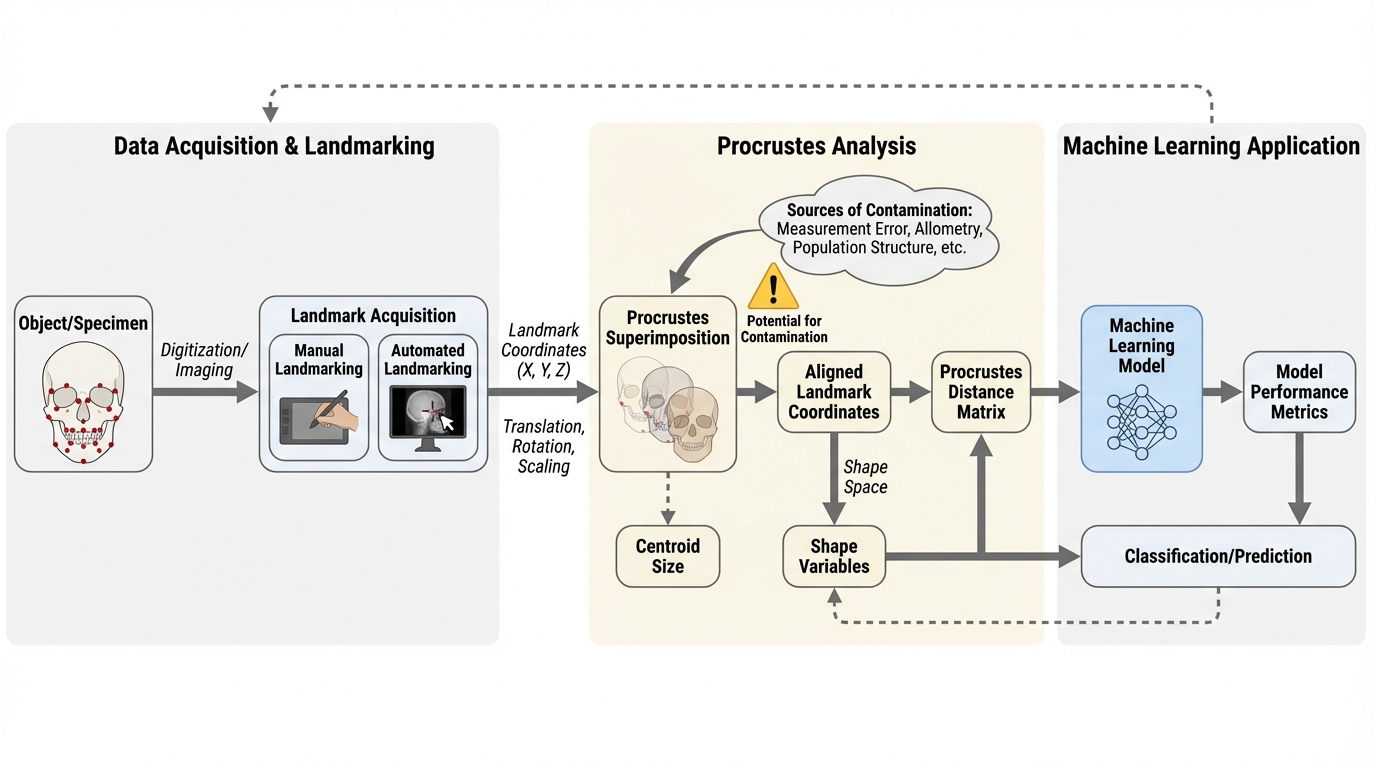
幾何学的形態測定学(GMM)を機械学習に統合する際、データ分割前に全標本を一括で整列させる標準的な一般化プロクラステス解析(GPA)が、訓練データとテストデータの間に不適切な統計的依存関係を生じさせ、予測精度を不当に高く見積もる「プロクラステス汚染」を引き起こすことを数学的・実験的に解明しました。 この問題を解決するため、テスト標本を訓練セットから独立して計算された幾何学的基準に対して個別に整列させる新しい再アライメント手順を提案し、2次元および3次元の制御されたシミュレーションを通じて、サンプルサイズやランドマーク密度、アロメトリーのパターンが二乗平均平方根誤差(RMSE)に与える影響を詳細に評価しました。 検証の結果、ランドマーク間の空間的自己相関を無視するとモデルの性能が著しく低下することが示され、本研究はGMMデータを機械学習に用いる際の厳密な前処理の必要性を確立するとともに、過学習やデータ漏洩を防ぎ、形状空間に固有の統計的制約を考慮した信頼性の高い解析を行うための実践的なガイドラインを提示しています。
なぜこの問題か
現代の科学研究は、従来の仮説駆動型のアプローチから、人工知能や機械学習によって加速されるデータ中心のモデルへと大きな転換期を迎えています。進化生物学、古生物学、考古学といった分野においても、機械学習はかつての特殊な計算ツールから、研究の基盤を支える重要な柱へと進化しました。しかし、この急速な普及の裏側で、手法の解釈可能性や理論的仮定の妥当性については十分な検討がなされていないという懸念があります。特に、予測性能の高さが、データの精度の低さや手法の堅牢性の欠如を隠蔽している可能性を批判的に評価することが求められています。機械学習には「フリーランチはない(No Free Lunch)」という定理があり、あらゆる問題に対して万能に機能する単一のアルゴリズムは存在しません。多くの失敗はモデルの選択ミスではなく、学習アルゴリズムが前提とする「訓練データとテストデータの独立性」を、前処理の段階で暗黙のうちに侵害してしまうことに起因しています。…
核心:何を提案したのか
本研究の核心は、幾何学的形態測定学における機械学習アプリケーションで発生する「プロクラステス汚染」の影響を正式に定義し、その問題を根本的に解決するための新しい「再アライメント手順」を提案したことにあります。この提案手法は、テスト標本を訓練セットと同時に処理するのではなく、訓練セットのみから推定された幾何学的基準(平均形状など)に対して、テスト標本を後から個別に整列させるというアプローチをとります。これにより、訓練データとテストデータの間の統計的結合を完全に断ち切り、機械学習の基本原則であるデータの独立性を担保することが可能になります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related