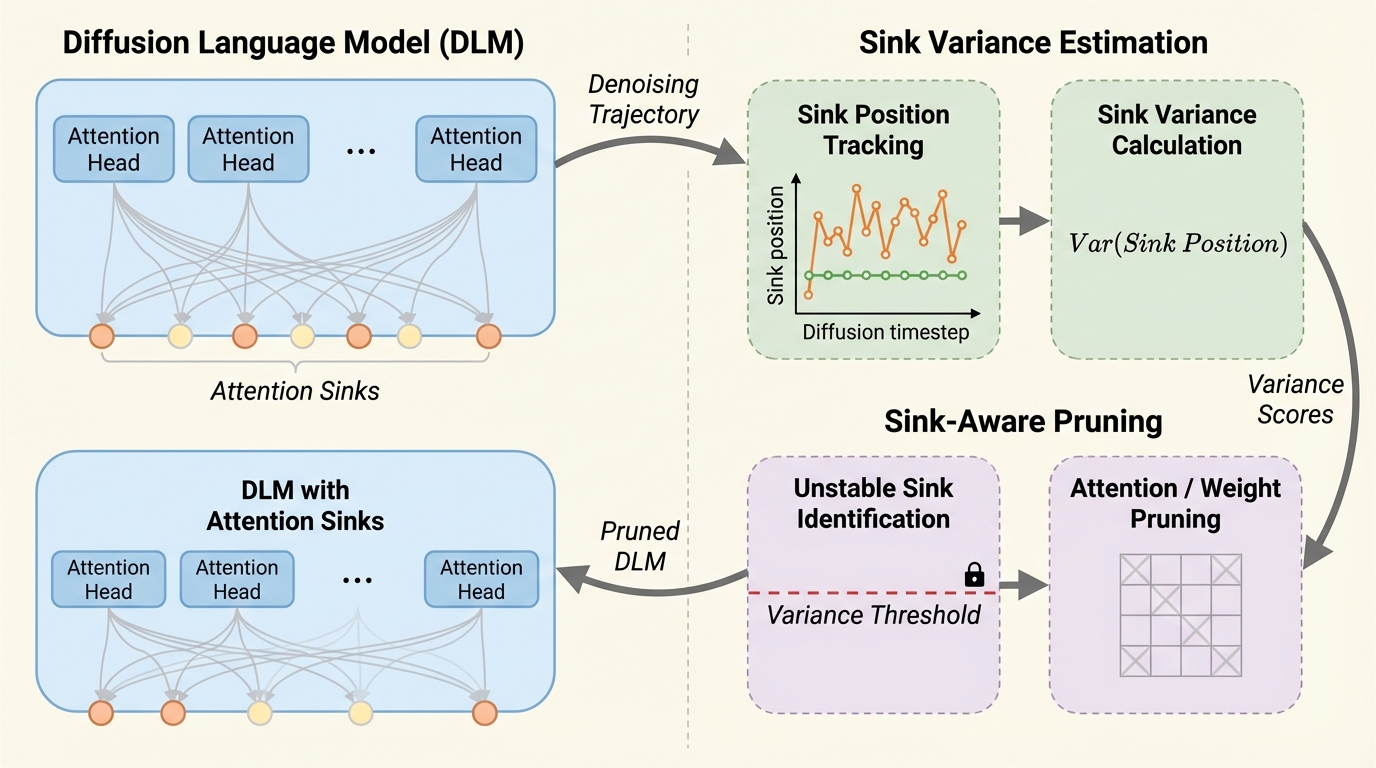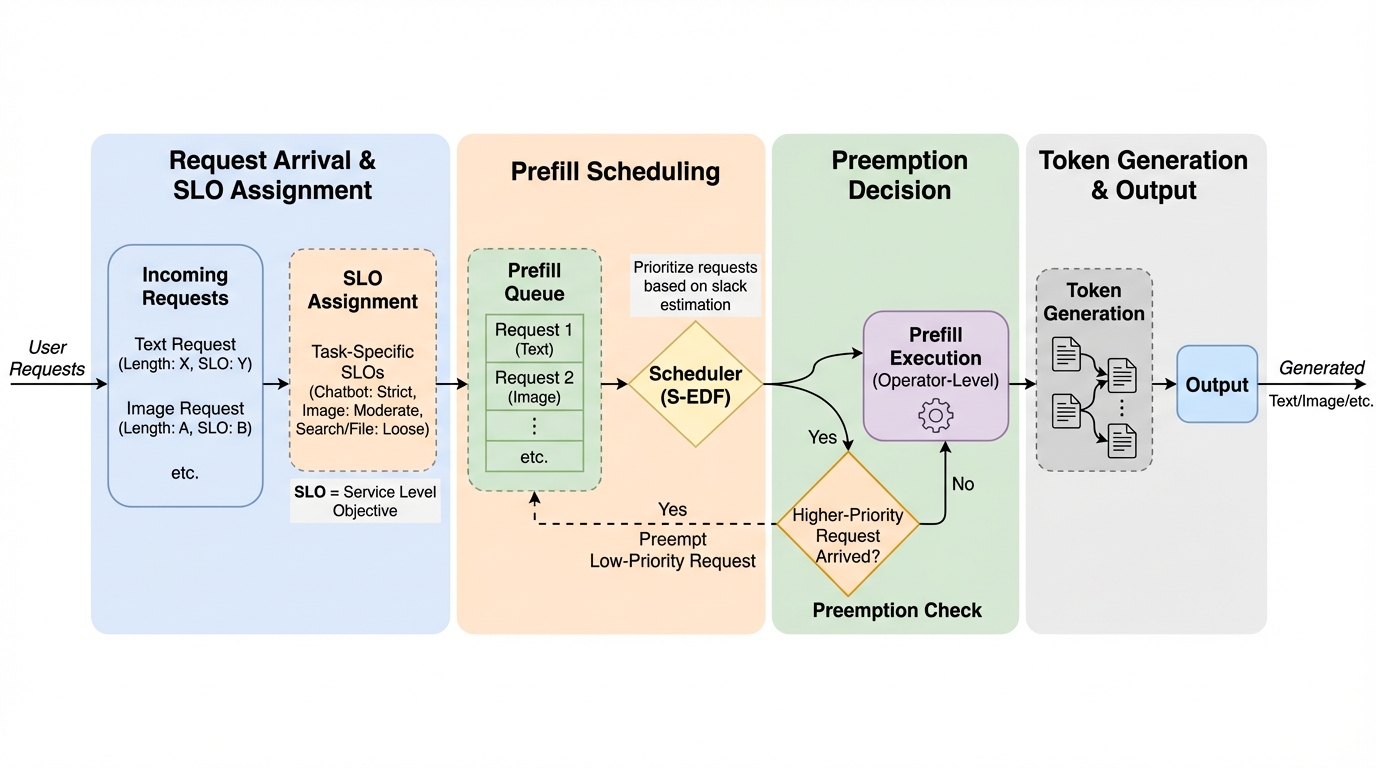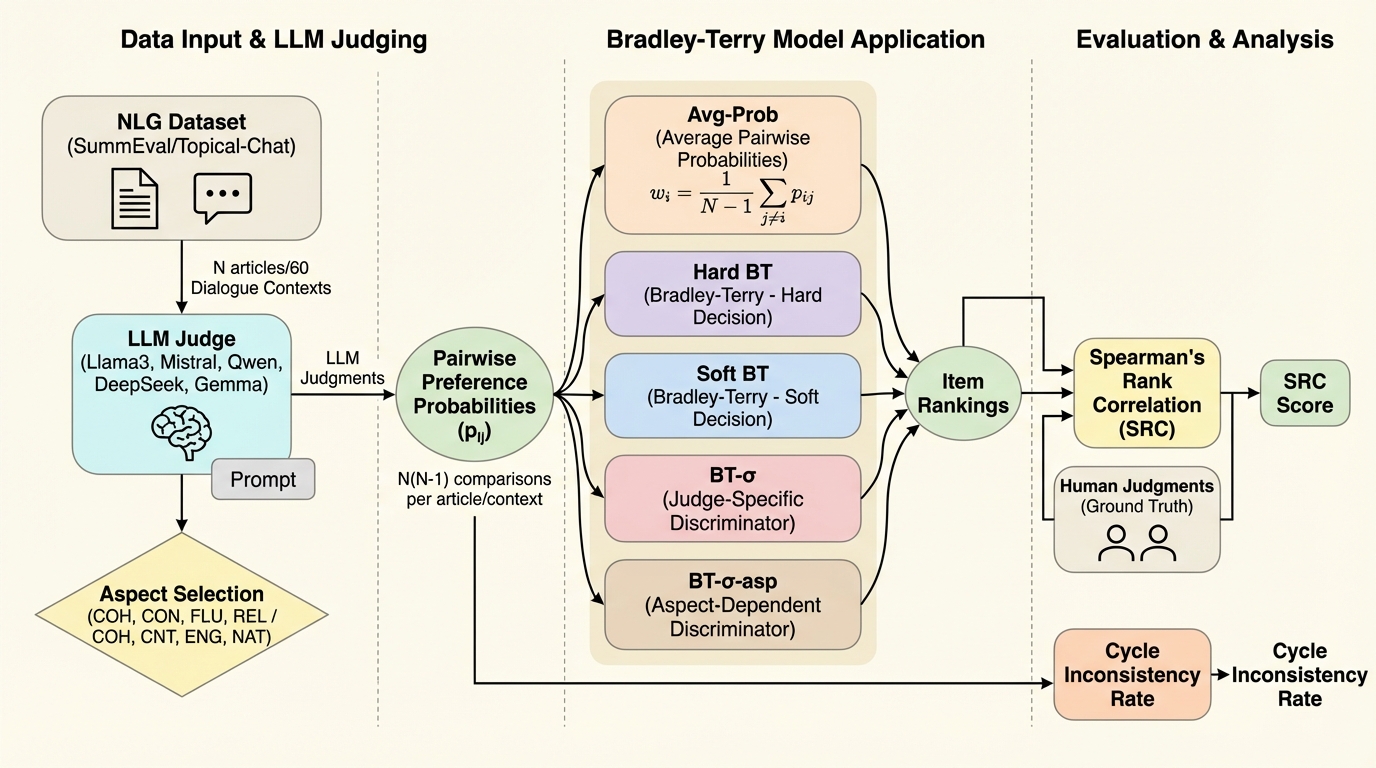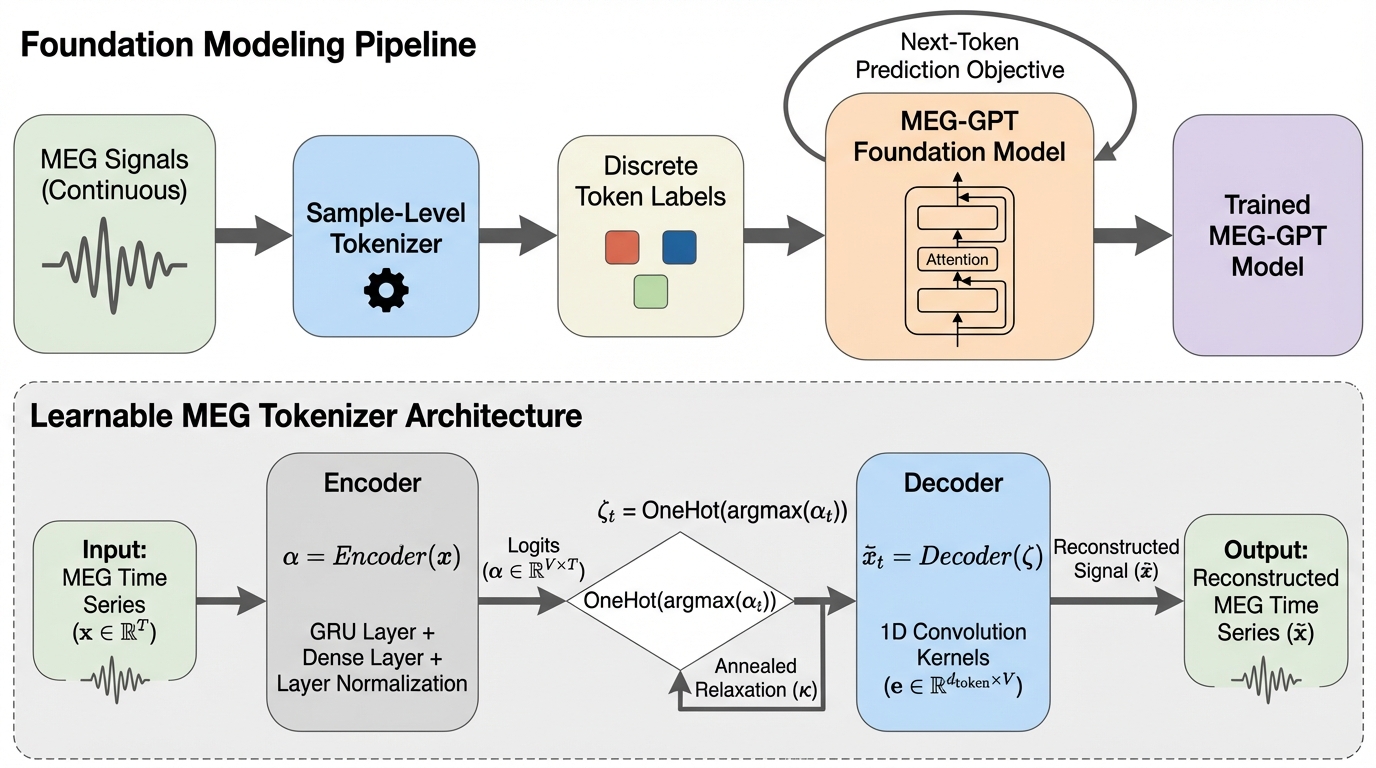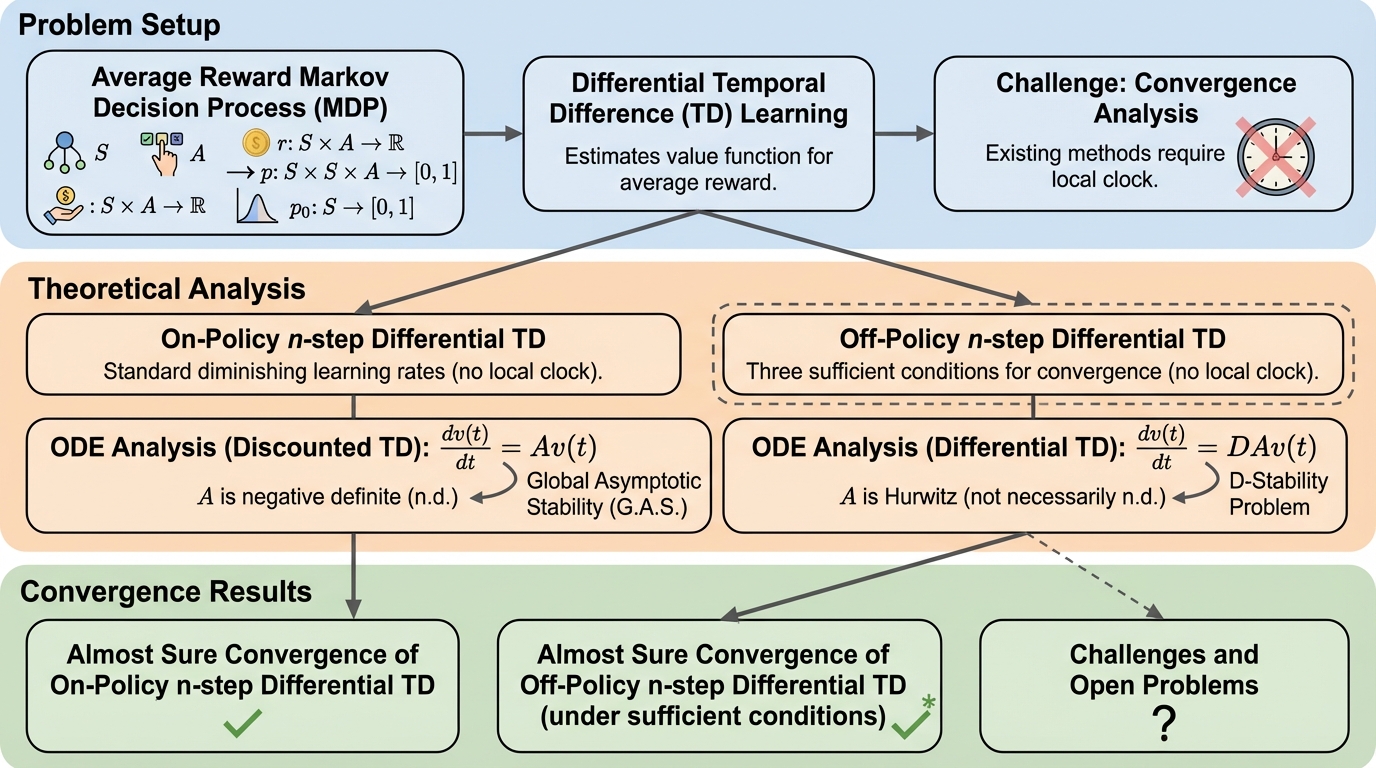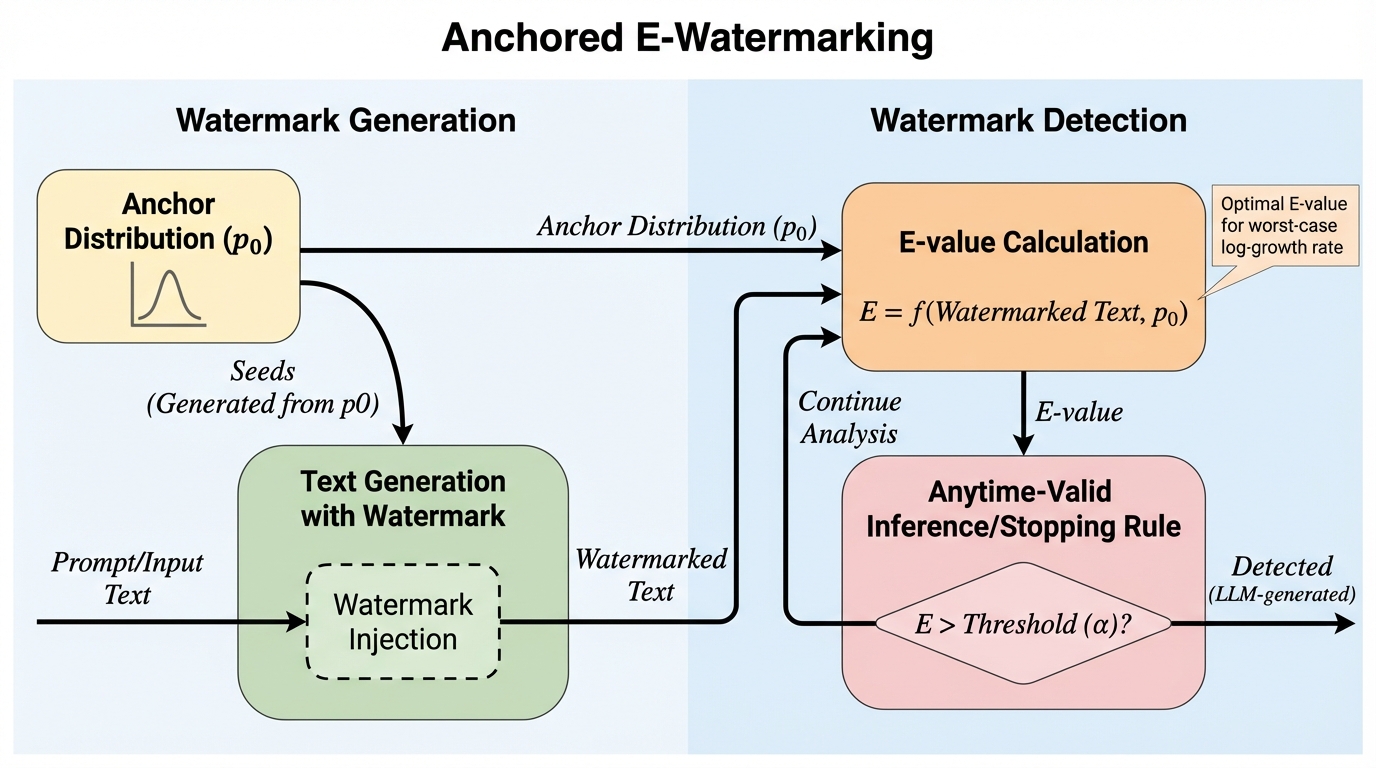
いつでも有効な統計的ウォーターマーキングに向けて
本論文は、統計的ウォーターマーキング検出を逐次(ストリーミング)で監視しながら、止めるタイミングをデータに応じて選んでも偽陽性(Type I error)の上限が崩れない枠組みを示しています。 / 生成側と検出側が共有するアンカー分布p0を導入し、ターゲット分布qがp0の近傍にあるという前提のもとで、トークンと疑似乱数シードの依存を埋め込みつつ、検出をe-value(非負のスーパー・マルチンゲール)として設計します。 / 理論として最悪ケースの対数成長率と期待停止時間の関係を与え、シミュレーションと既存ベンチマーク評価により、平均の検出トークン予算を最先端ベースラインより13〜15%削減できたと報告しています。