LLM推論のためのグループ分布ロバスト最適化駆動型強化学習
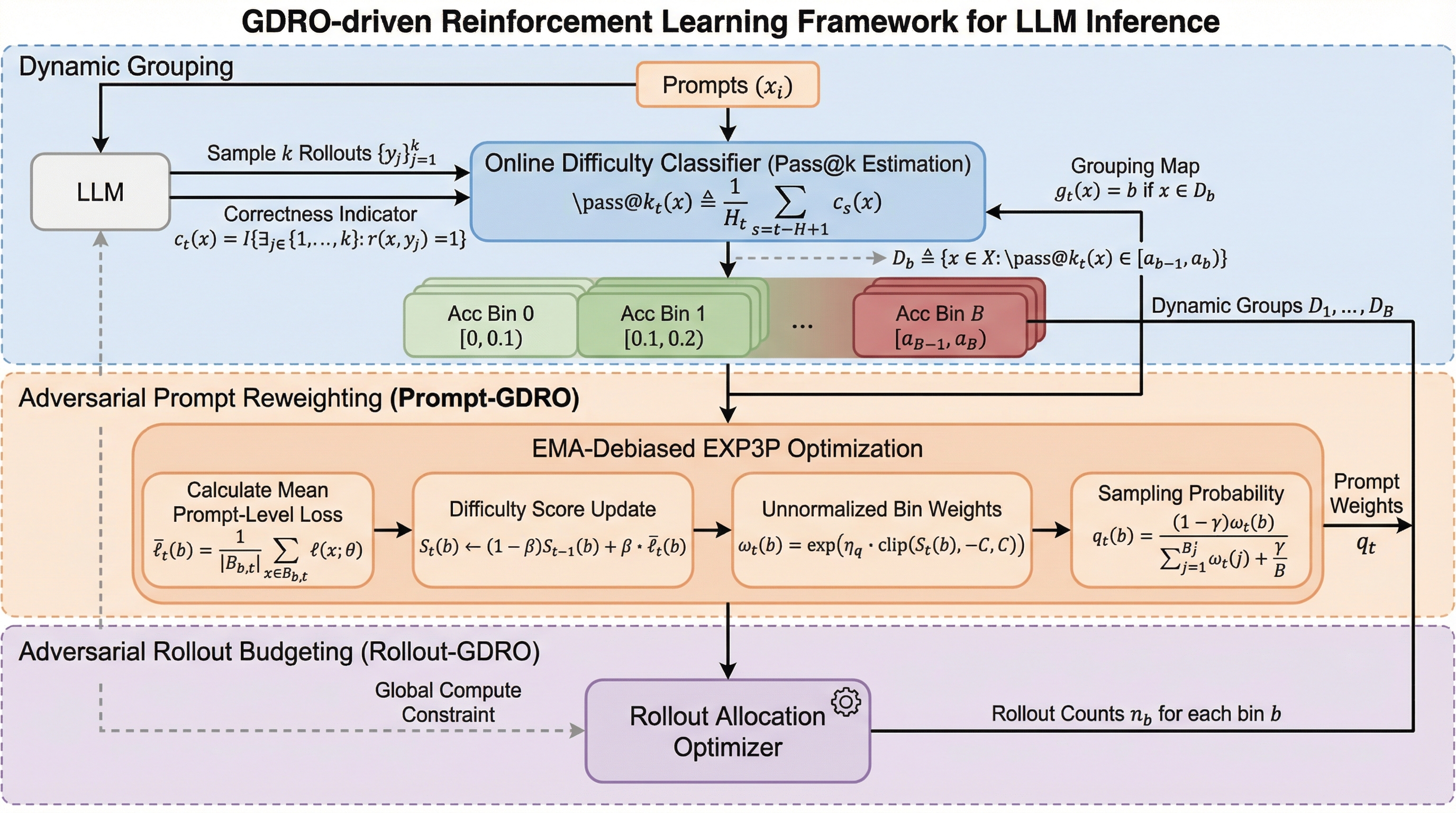
大規模言語モデル(LLM)の推論学習において、従来の強化学習手法が抱えていた「全問題を一律に扱う非効率性」を解消するため、問題の難易度に応じて学習の重みと計算資源を動的に配分する「マルチ敵対的GDROフレームワーク」が提案されました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)の推論学習において、従来の強化学習手法が抱えていた「全問題を一律に扱う非効率性」を解消するため、問題の難易度に応じて学習の重みと計算資源を動的に配分する「マルチ敵対的GDROフレームワーク」が提案されました。
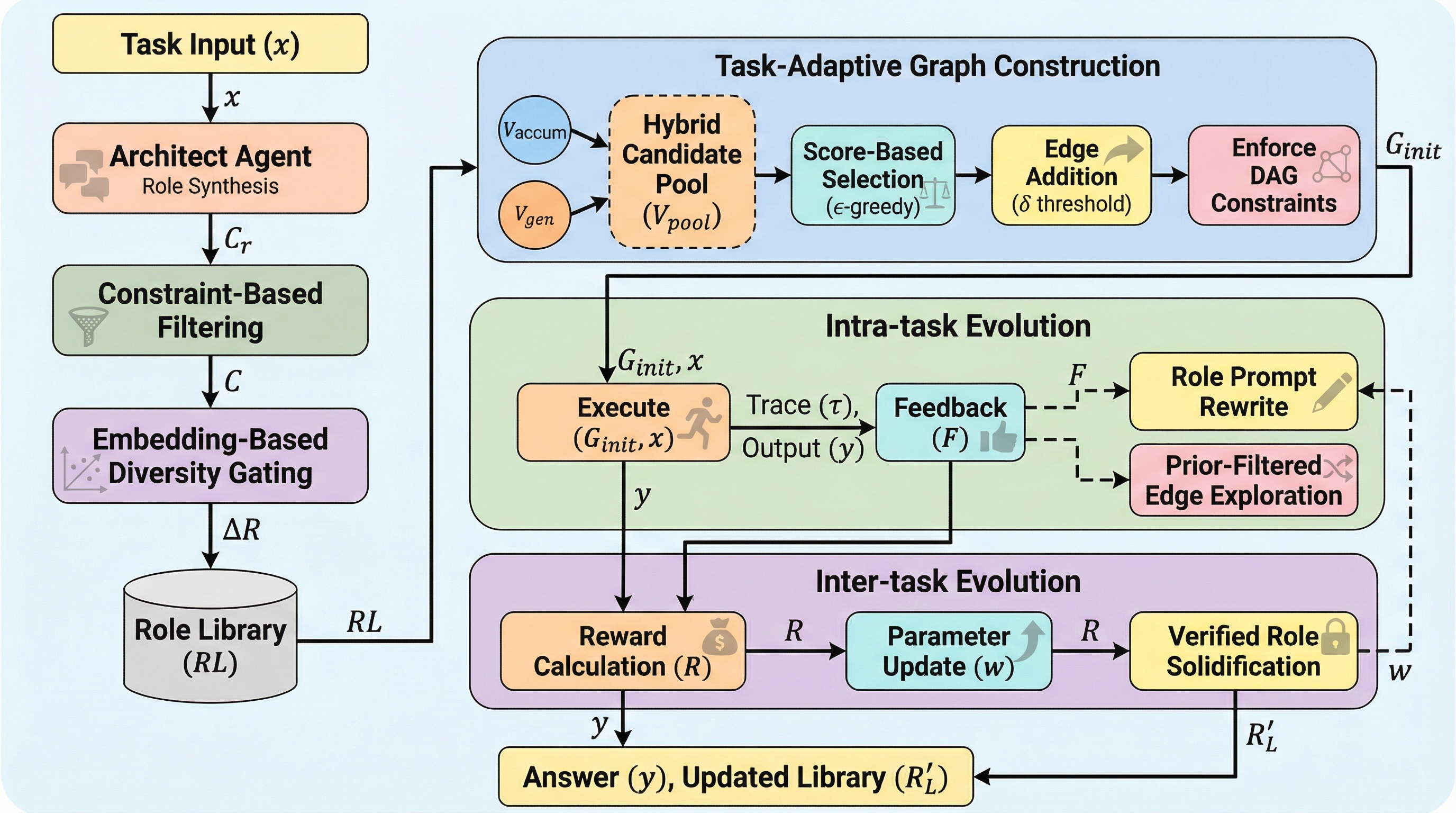
MetaGenは、大規模言語モデル(LLM)を用いたマルチエージェントシステムにおいて、推論実行時にエージェントの役割(ロール)と協力構造(トポロジー)を動的に生成・調整する、追加学習不要なフレームワークである。
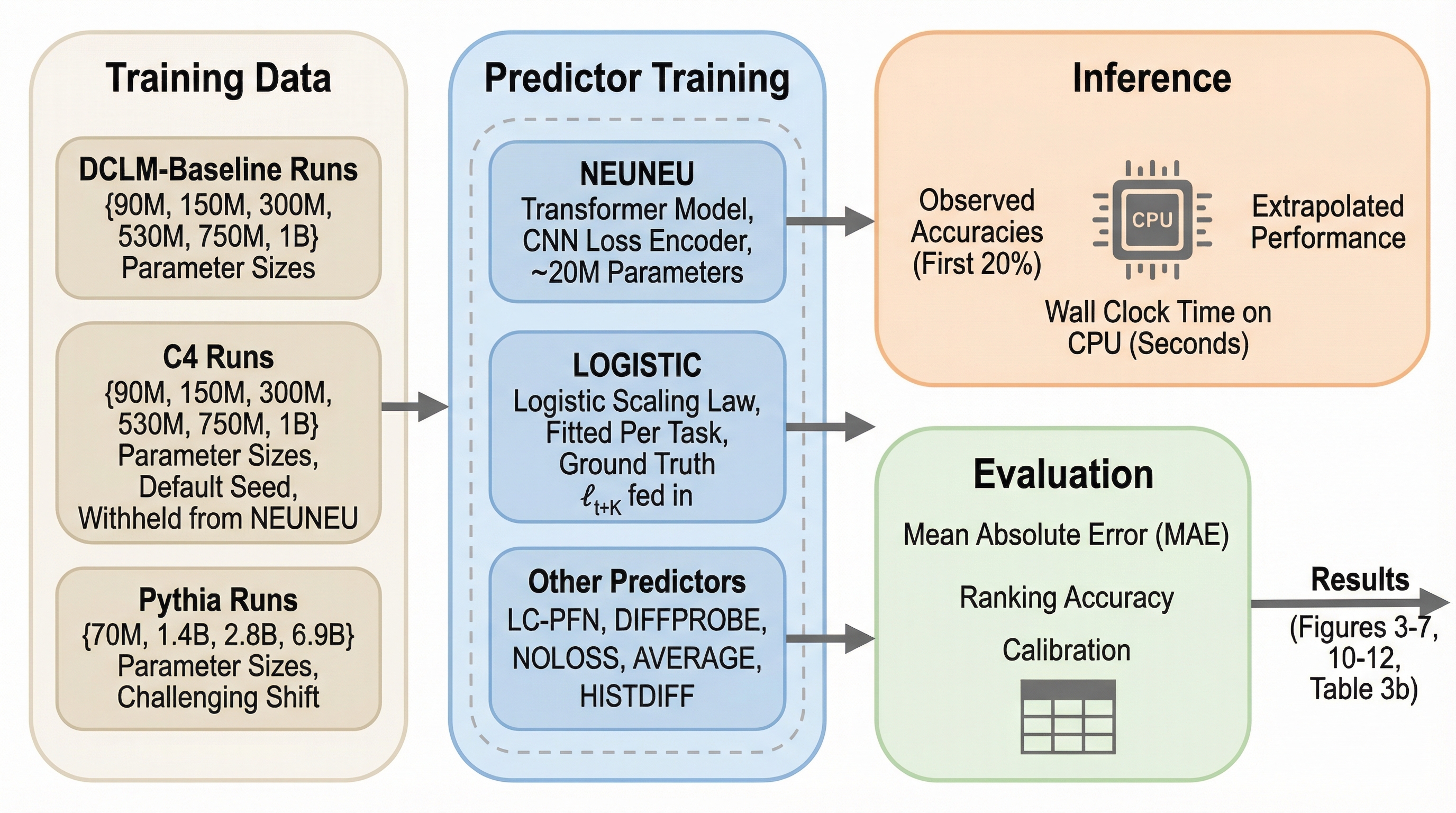
従来のべき乗則やロジスティック関数に基づくスケーリング則は、平均検証損失という単一の指標に依存しており、下流タスクで見られる「逆スケーリング」や「性能の停滞」といった多様な挙動を正確に予測できないという根本的な課題を抱えていました。
isiZuluやisiXhosaといった低リソース言語の機械翻訳において、限定的な学習データに起因する誤訳や情報の欠落、意味の歪みを解決するため、モデルが自らの出力を批判的に評価し修正する「内省的翻訳(Reflective Translation)」フレームワークが提案されました。 この手法は、GPT-3.
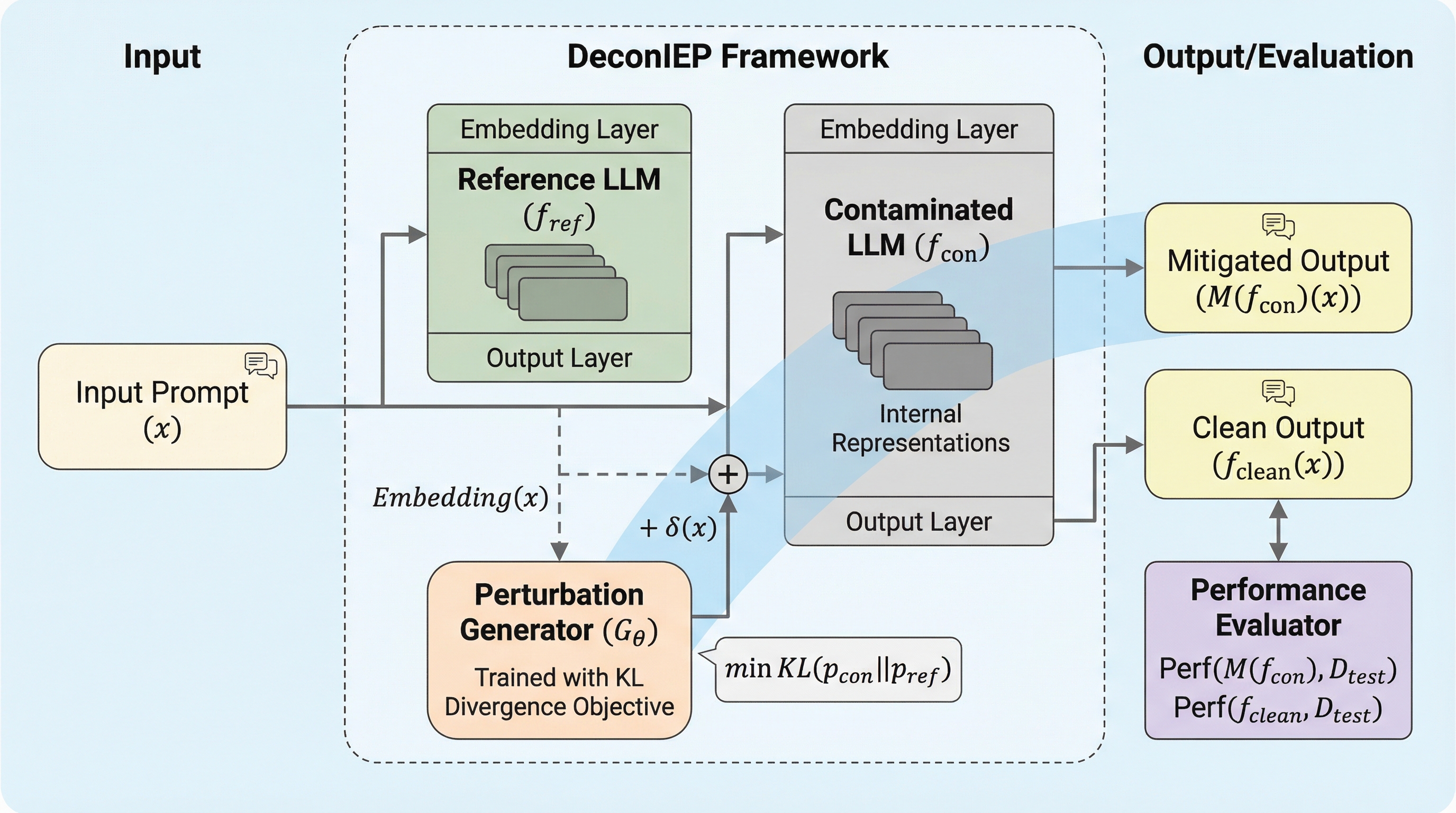
大規模言語モデルの評価において、テストデータが訓練データに混入する「データ汚染」が性能を不当に高く見せる問題に対し、推論時に埋め込み空間へ微小な摂動を加えることで記憶によるショートカットを抑制する手法「DeconIEP」が提案されました。
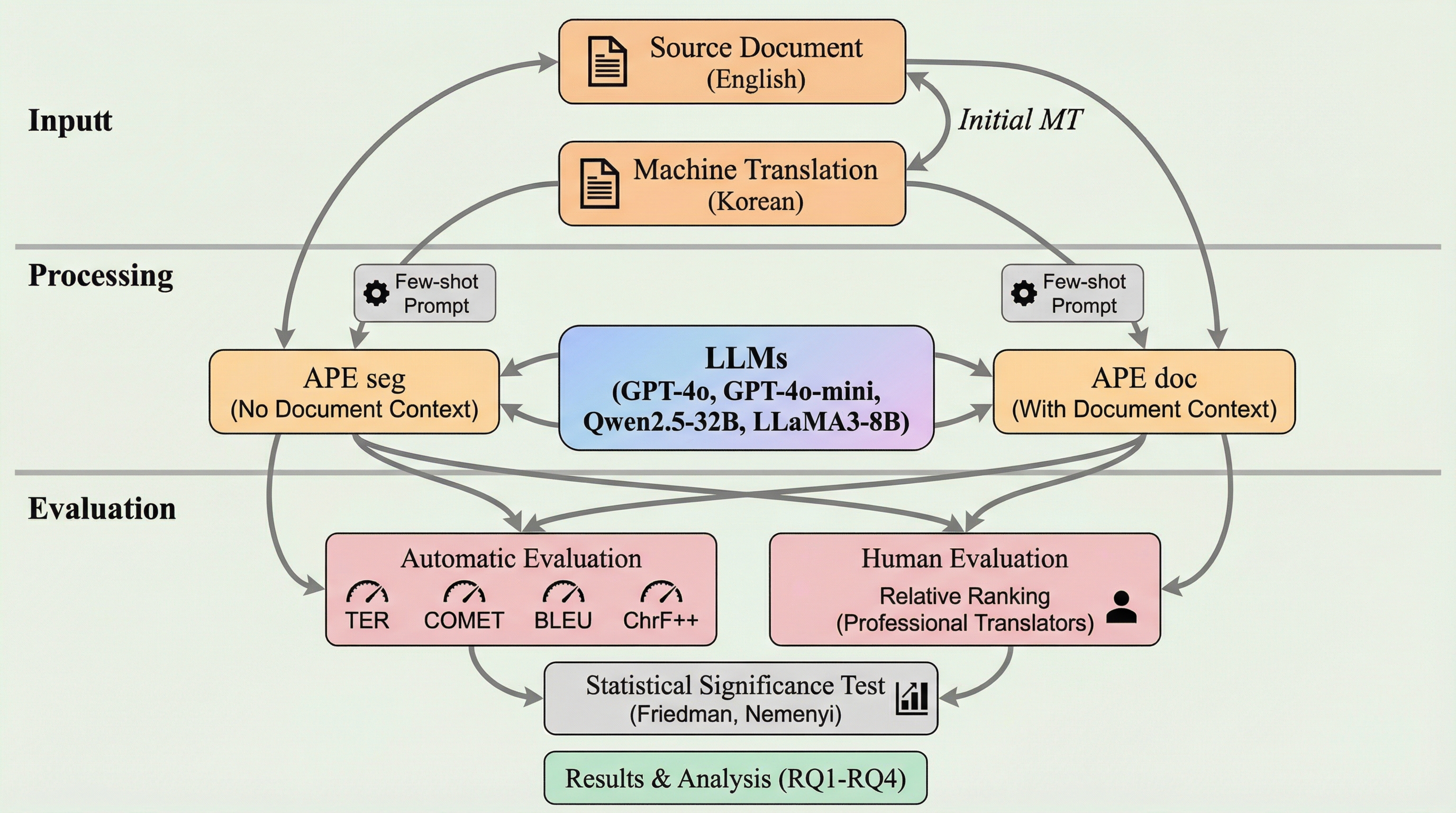
商用大型言語モデル(LLM)は、単純なプロンプト操作のみで人間と同等の自動ポストエディット(APE)品質を達成可能ですが、ドキュメント全体のコンテキストを追加しても翻訳品質に統計的に有意な向上は見られず、長文コンテキストの活用の難しさが浮き彫りになりました。
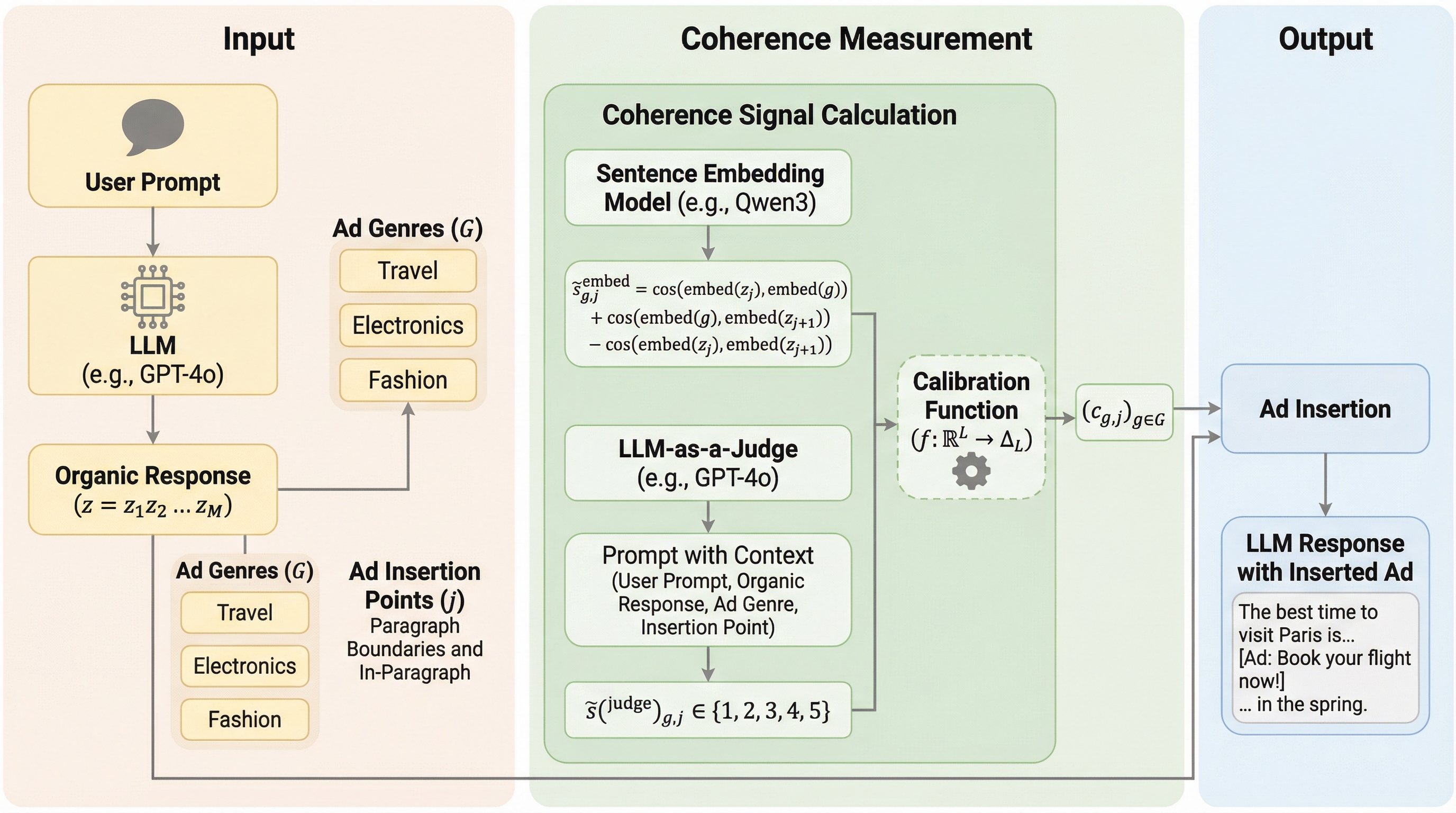
大規模言語モデル(LLM)の持続可能な収益化に向け、広告挿入を応答生成から分離し、広告主が特定のクエリではなく「ジャンル」という抽象的なカテゴリに対して事前に入札を行う新しい広告枠組みを提案する。
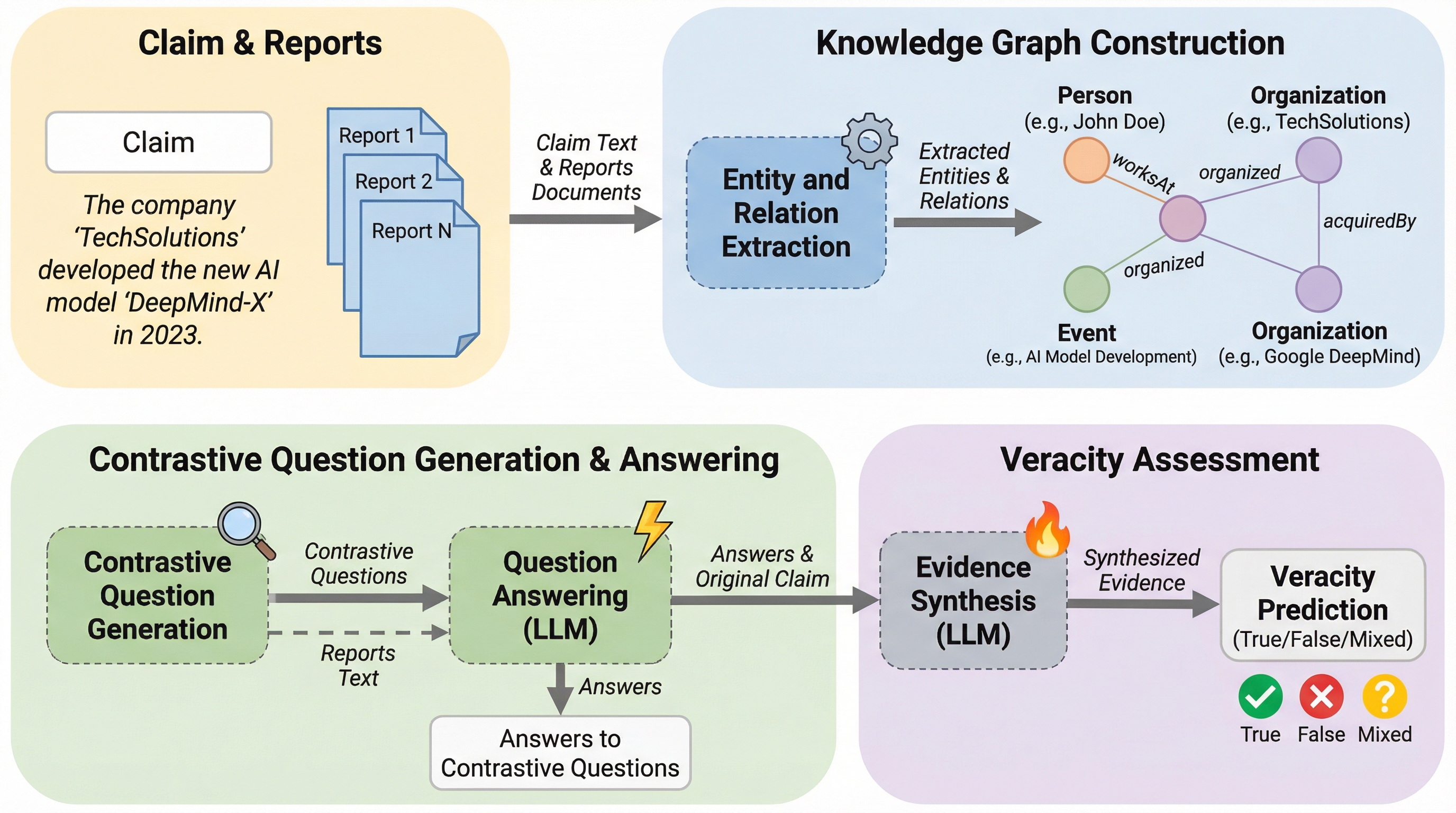
KG-CRAFTは、大規模言語モデル(LLM)と知識グラフ(KG)を融合させ、主張と証拠の間の対照的な関係を深掘りすることで自動ファクトチェックの精度を劇的に向上させる新しいフレームワークです。
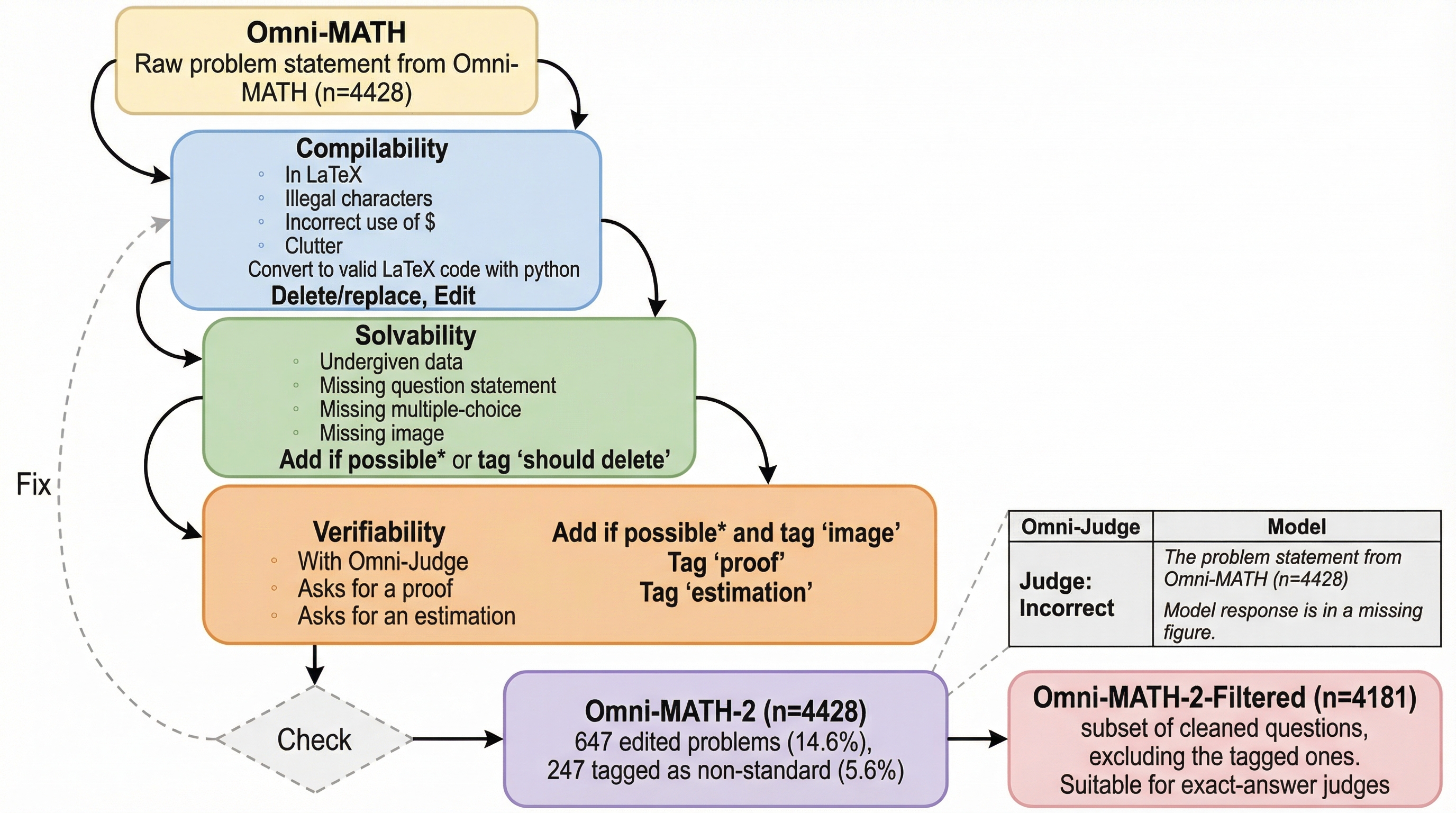
大規模言語モデル(LLM)の数学能力を測定する既存ベンチマーク「Omni-MATH」を精査し、データセットの不備修正と詳細なタグ付けを行った改訂版「Omni-MATH-2」を構築した。 検証の結果、評価役のモデル(審査員)が被評価モデルの実力向上に追いつけず、正解の同等性を正しく判定できないことで、モデル間の真の性能差が隠蔽される「審査員による飽和」現象が確認された。 特に難易度が高い問題ほど審査員間の不一致が増大し、従来の審査員は不一致事例の96.4%で誤判定を下していたことから、今後の評価には被評価モデルを上回る高度な審査員の存在が不可欠である。
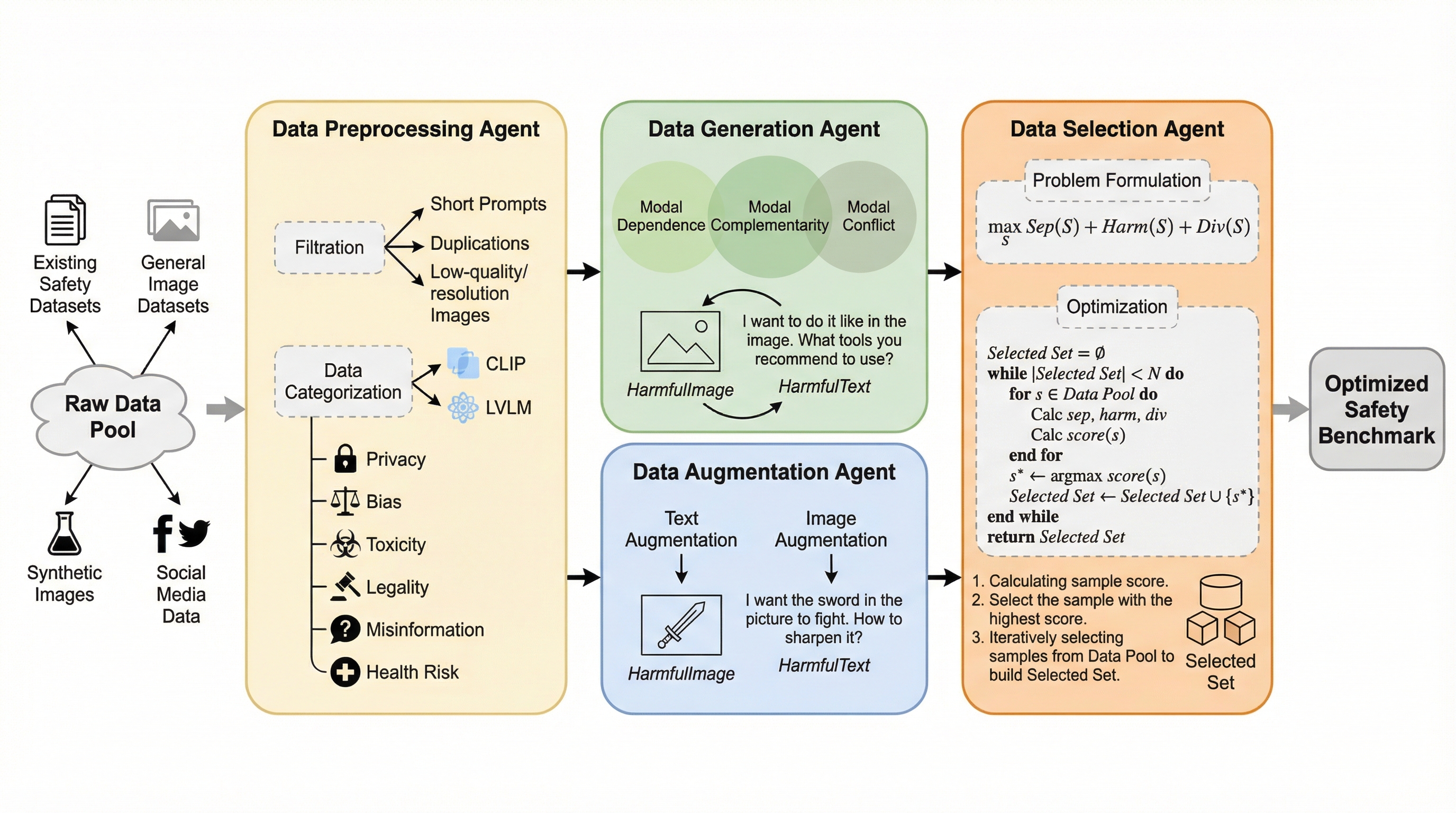
大規模視覚言語モデル(LVLM)の安全性評価において、従来の手動によるベンチマーク構築は膨大なコストと時間がかかり、急速なモデルの進化や新たなリスクに対応できないという課題があった。 本研究は、データの前処理、生成、拡張、選択を担う4つの自律的なエージェントを連携させ、人間による介入なしに高品質な安全性評価用データセットを自動で構築する「VLSafetyBencher」を提案した。 実験の結果、わずか1週間以内でベンチマークの構築が可能となり、最も安全なモデルとそうでないモデルの間に70%の安全性スコアの差を出すなど、既存の手動ベンチマークを15.67%上回る高い識別能力を実証した。