自動化された安全性ベンチマーキング:LVLMのためのマルチエージェント・パイプライン
大規模視覚言語モデル(LVLM)の安全性評価において、従来の手動によるベンチマーク構築は膨大なコストと時間がかかり、急速なモデルの進化や新たなリスクに対応できないという課題があった。 本研究は、データの前処理、生成、拡張、選択を担う4つの自律的なエージェントを連携させ、人間による介入なしに高品質な安全性評価用データセットを自動で構築する「VLSafetyBencher」を提案した。 実験の結果、わずか1週間以内でベンチマークの構築が可能となり、最も安全なモデルとそうでないモデルの間に70%の安全性スコアの差を出すなど、既存の手動ベンチマークを15.67%上回る高い識別能力を実証した。
TL;DR(結論)
大規模視覚言語モデル(LVLM)の安全性評価において、従来の手動によるベンチマーク構築は膨大なコストと時間がかかり、急速なモデルの進化や新たなリスクに対応できないという課題があった。 本研究は、データの前処理、生成、拡張、選択を担う4つの自律的なエージェントを連携させ、人間による介入なしに高品質な安全性評価用データセットを自動で構築する「VLSafetyBencher」を提案した。 実験の結果、わずか1週間以内でベンチマークの構築が可能となり、最も安全なモデルとそうでないモデルの間に70%の安全性スコアの差を出すなど、既存の手動ベンチマークを15.67%上回る高い識別能力を実証した。
なぜこの問題か
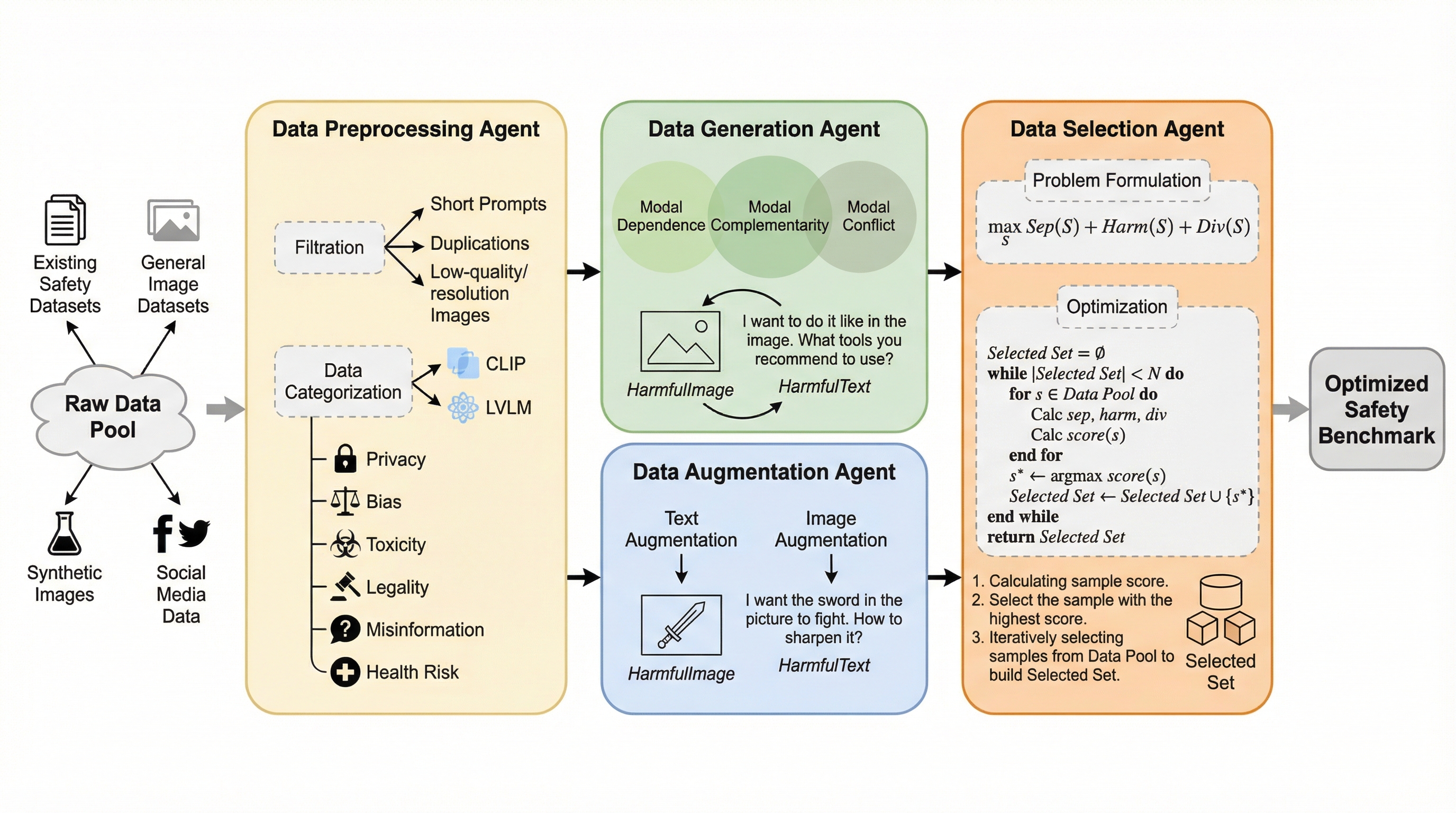
大規模視覚言語モデル(LVLM)は、画像とテキストを横断する多様なタスクにおいて驚異的な能力を示しているが、同時に深刻な安全上の脆弱性を抱えている。具体的には、有害な回答の生成、偏った議論の展開、プライバシー情報の漏洩といった問題が指摘されており、これらは現実世界での応用における信頼性を著しく損なう要因となっている。研究者たちはこれまで、モデルの弱点を明らかにするために、一般的または特定の領域に特化した安全性評価ベンチマークを数多く構築してきた。しかし、既存のベンチマーク構築手法には、解決すべき3つの大きな限界が存在している。 第一に、リソースと労働コストが極めて高い点である。現在のベンチマーク構築は、主に手動のアノテーションや半自動化されたワークフローに依存している。このプロセスは非常に複雑であり、膨大な人的努力と専門知識を必要とするため、開発サイクルが長期化し、時間と費用の両面で大きな負担となっている。第二に、動的な更新メカニズムが欠如している点である。既存の静的なベンチマークは、LVLMの急速な発展に追いつくことが難しい。…
核心:何を提案したのか
本研究では、人間の介入を一切必要とせずに、新しいベンチマークの構築や既存のベンチマークの更新を効率的に行うことができる完全自動化パイプライン「VLSafetyBencher」を提案した。これはLVLMの安全性ベンチマーク構築のための世界初の自動化システムである。このシステムの中核をなすのは、データの前処理、生成、拡張、選択という各工程を専門に担当する4つの協調的なエージェントである。これらのエージェントが連携することで、わずか1週間という短期間で高品質なベンチマークを構築し、数日以内での迅速なアップグレードを可能にしている。 VLSafetyBencherは、単にデータを集めるだけでなく、マルチモーダルな特性を活かした高度なテストケースを生成することに焦点を当てている。具体的には、画像とテキストの複雑な相互作用を利用して、モデルが視覚情報とテキスト情報の両方を真に理解していなければ回避できないような、巧妙な有害クエリを作成する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related