モデルが審査員より賢くなるとベンチマークは飽和する
大規模言語モデル(LLM)の数学能力を測定する既存ベンチマーク「Omni-MATH」を精査し、データセットの不備修正と詳細なタグ付けを行った改訂版「Omni-MATH-2」を構築した。 検証の結果、評価役のモデル(審査員)が被評価モデルの実力向上に追いつけず、正解の同等性を正しく判定できないことで、モデル間の真の性能差が隠蔽される「審査員による飽和」現象が確認された。 特に難易度が高い問題ほど審査員間の不一致が増大し、従来の審査員は不一致事例の96.4%で誤判定を下していたことから、今後の評価には被評価モデルを上回る高度な審査員の存在が不可欠である。
TL;DR(結論)
大規模言語モデル(LLM)の数学能力を測定する既存ベンチマーク「Omni-MATH」を精査し、データセットの不備修正と詳細なタグ付けを行った改訂版「Omni-MATH-2」を構築した。 検証の結果、評価役のモデル(審査員)が被評価モデルの実力向上に追いつけず、正解の同等性を正しく判定できないことで、モデル間の真の性能差が隠蔽される「審査員による飽和」現象が確認された。 特に難易度が高い問題ほど審査員間の不一致が増大し、従来の審査員は不一致事例の96.4%で誤判定を下していたことから、今後の評価には被評価モデルを上回る高度な審査員の存在が不可欠である。
なぜこの問題か
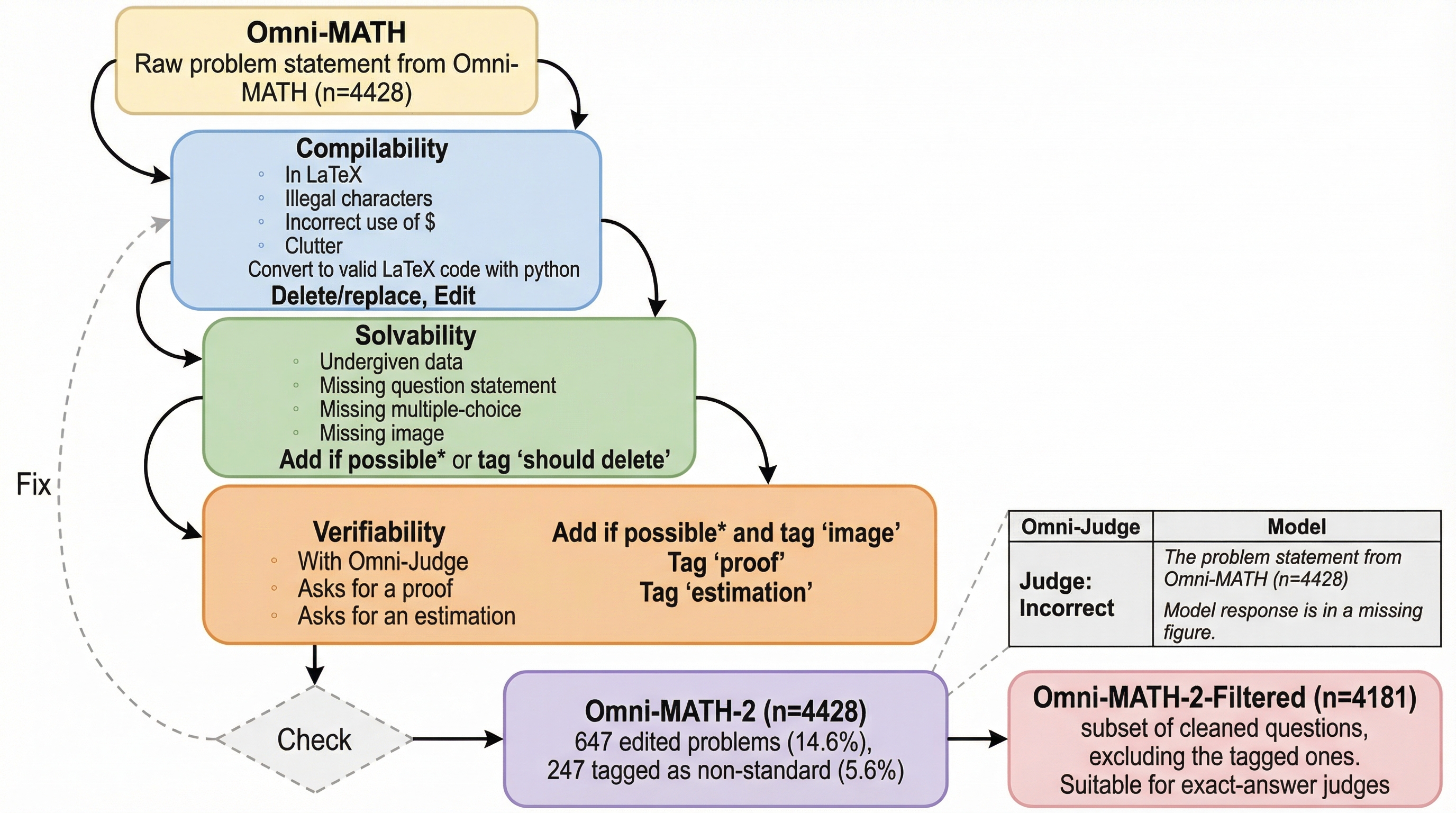
大規模言語モデル(LLM)の急速な進化に伴い、その能力を正確に測定するためのベンチマークの重要性がかつてないほど高まっている。しかし、近年のベンチマークは従来の選択肢形式から自由回答形式へと移行しており、さらにオリンピックレベルの数学のような極めて難易度の高いタスクへとシフトしている。自由回答形式はモデルの深い推論能力を測るのに適している一方で、回答の抽出や、モデルの回答が参照解と数学的に同等であるかを判定するプロセスにおいて、新たなエラーの原因を生み出している。本論文では、現在のLLM評価パイプラインを損なう2つの主要なエラー要因に注目している。 第一に「データセットに起因するエラー」である。これには、問題文の曖昧さや、与えられた情報だけでは解けない問題、図表の欠落などが含まれる。既存の著名なベンチマークであるMMLUやHellaSwagにおいても、無視できない割合で不適切な項目が含まれていることが先行研究で指摘されている。第二に「審査員に起因するエラー」である。…
核心:何を提案したのか
著者らは、広く利用されている数学ベンチマーク「Omni-MATH」を徹底的に手作業で精査し、改訂版である「Omni-MATH-2」を構築した。このプロセスでは、元のデータセットの規模である4,428問を維持しつつ、LaTeXのコンパイル可能性、問題の解決可能性、および検証可能性を大幅に向上させている。具体的には、全体の14.6%にあたる647問の問題文を編集し、さらに5.6%にあたる247問に対して、標準的な自動評価に適さない「非標準的な問題」としてのタグ付けを行った。この改訂により、以下の2つの主要なサブセットが提供されることとなった。 1つ目は「Omni-MATH-2-Filtered (n=4,181)」である。これは精査・クリーンアップされ、厳密な正解判定が可能な問題群である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related