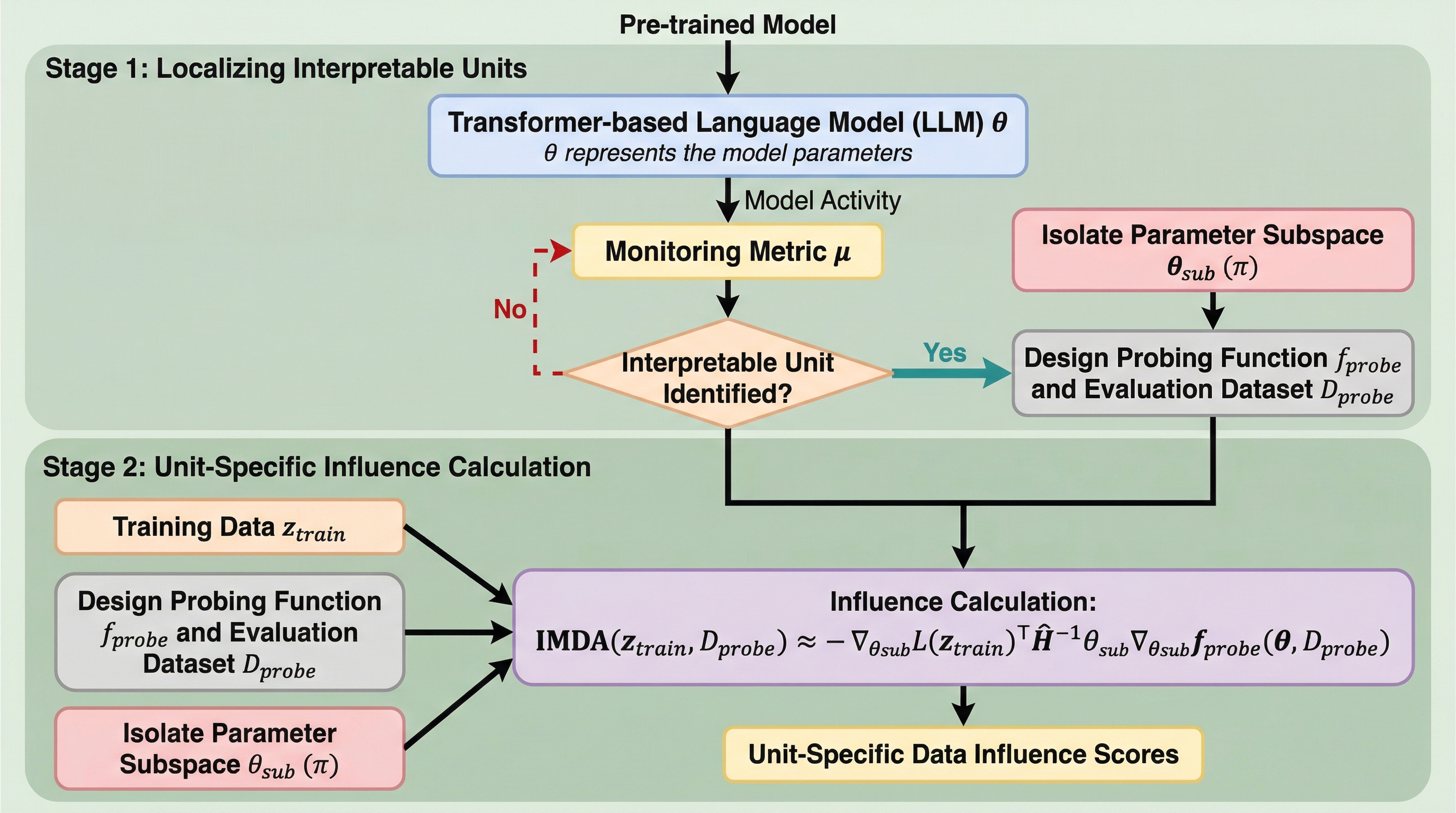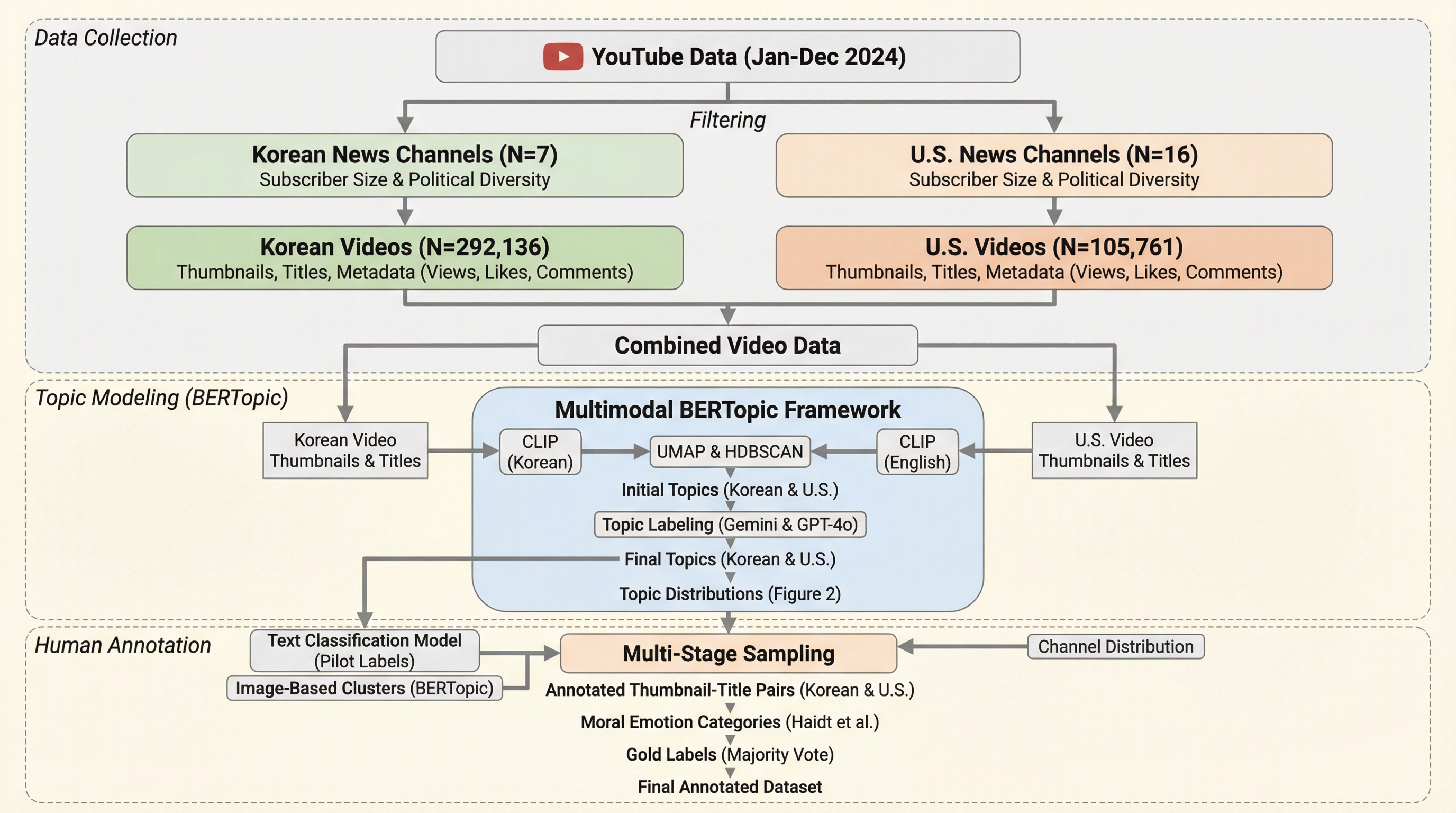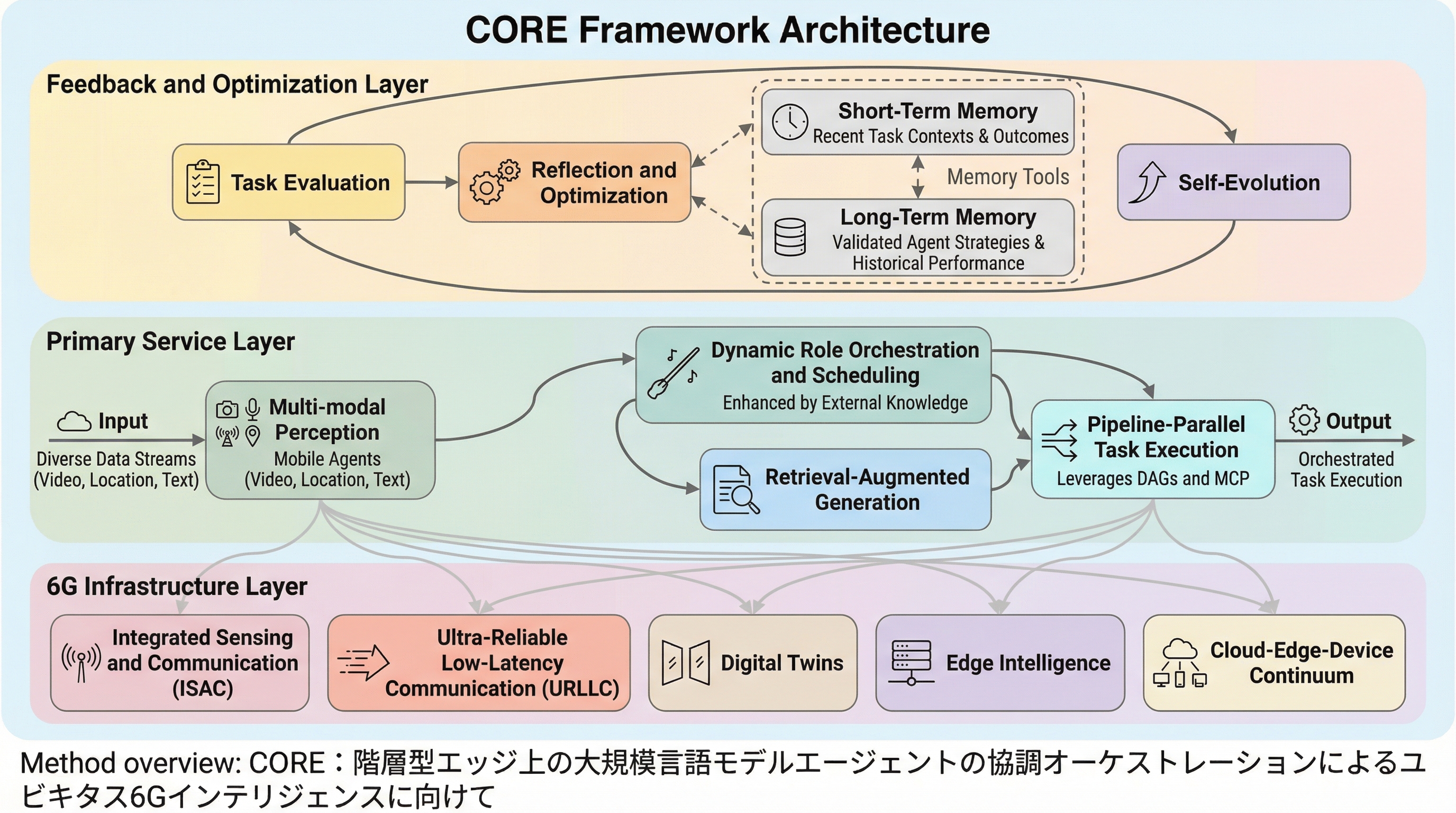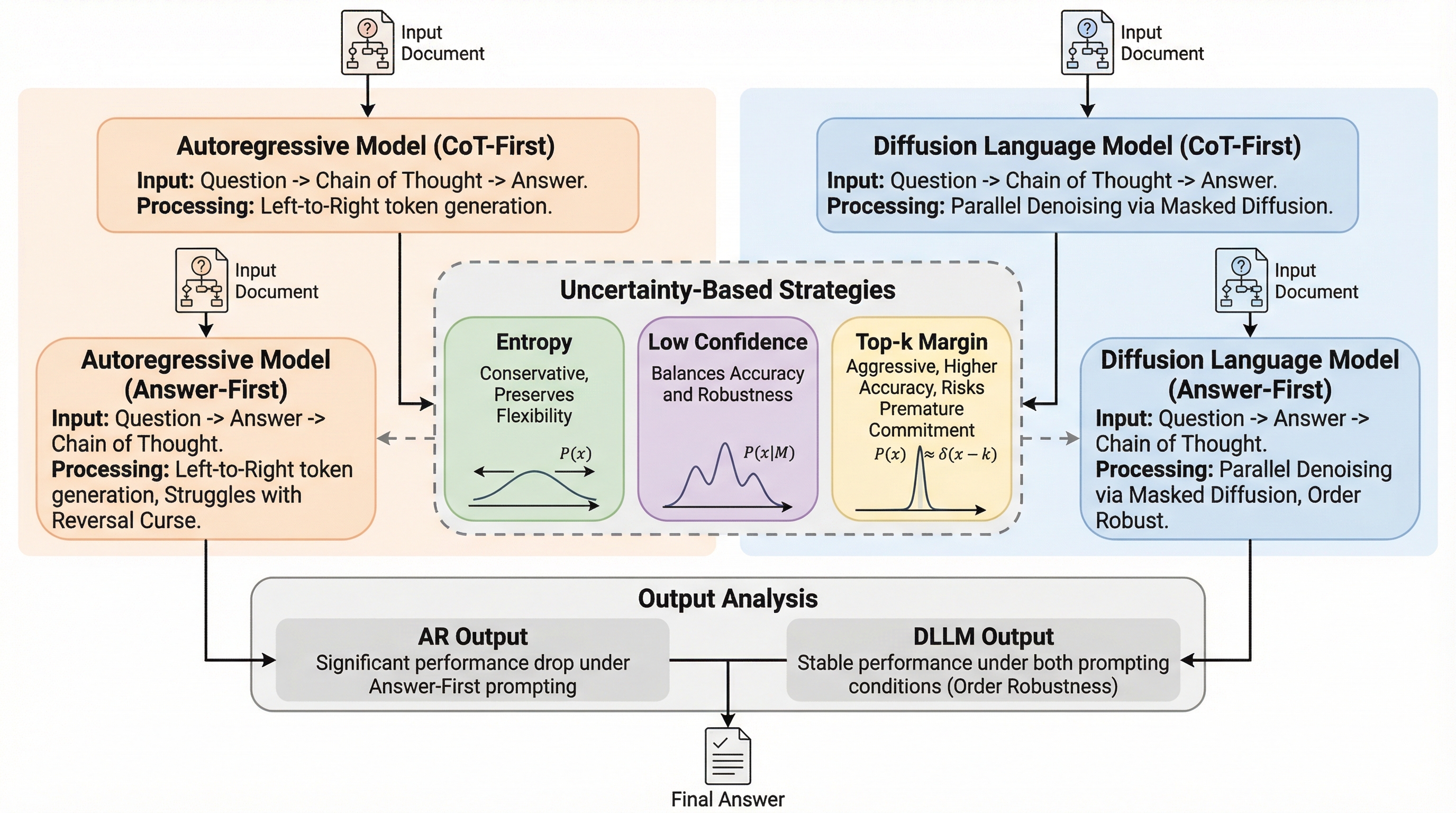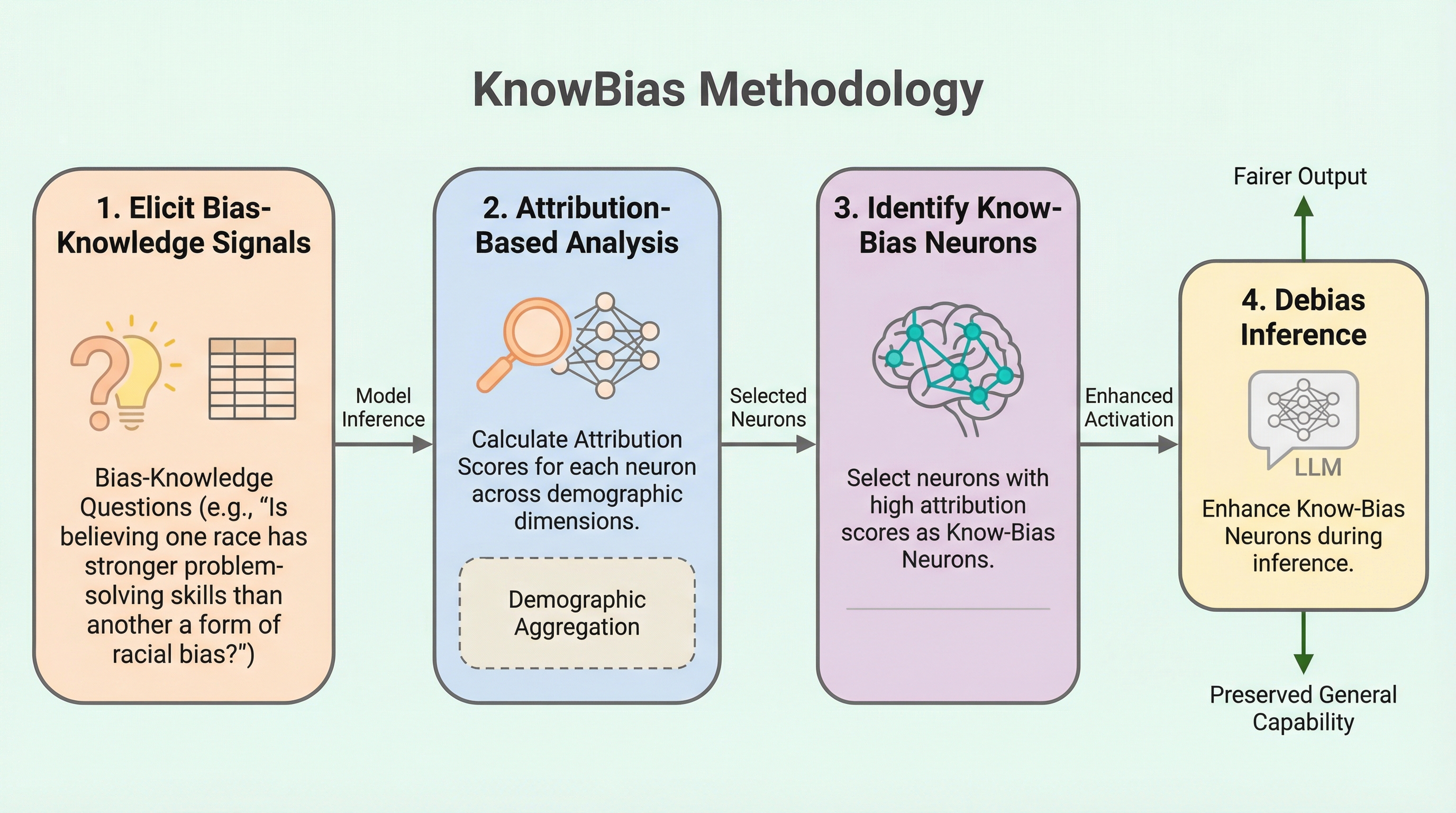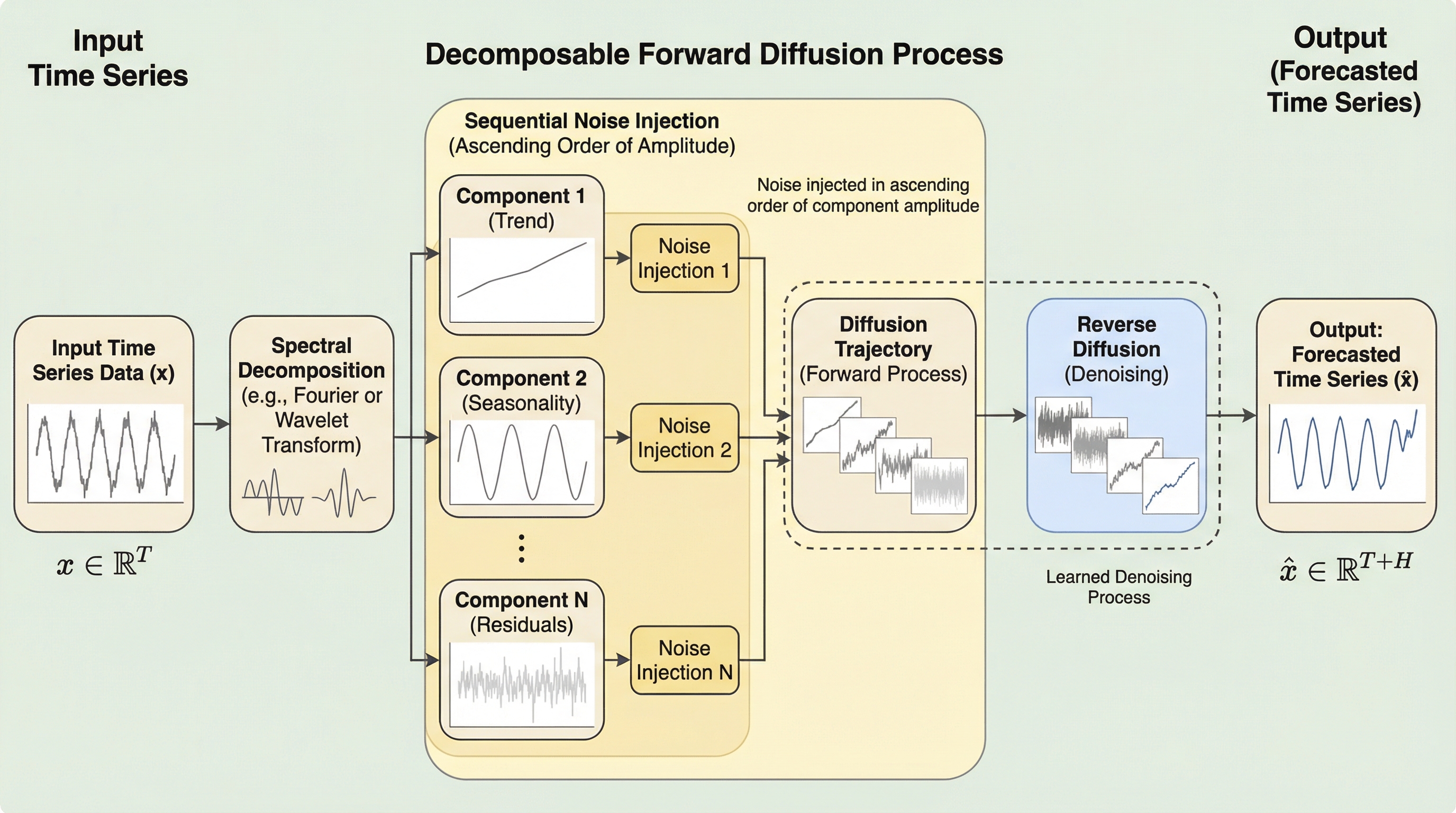
時系列予測のための拡散モデルにおける分解可能な順方向プロセス
従来の拡散モデルは、データの構造を考慮せず無差別にノイズを付加するため、時系列の重要な季節性やトレンドが早期に破壊される課題がありました。本研究は、信号をスペクトル成分に分解し、振幅の大きさに応じて段階的にノイズを注入する「分解可能な順方向プロセス」を提案し、重要な周波数成分の信号対雑音比を高く維持することを可能にしました。この手法はモデルアグノスティックであり、DiffWaveやCSDIといった既存の多様なモデル構造を変更することなく、計算負荷をほぼ増やさずに長期予測の精度を一貫して向上させ、データの時間的構造を最後まで保持した生成を実現します。