オフライン嗜好最適化のための潜在的敵対的正則化
大規模言語モデルの嗜好最適化において、従来の単語単位の正則化は表面的な一致に固執し、意味的な類似性や振る舞いの整合性を十分に捉えられないという課題がありました。本研究が提案するGANPOは、モデル内部の潜在表現空間において、学習対象のポリシーと参照モデルの間の乖離を敵対的学習によって抑制する新しい正則化手法です。
TL;DR(結論)
大規模言語モデルの嗜好最適化において、従来の単語単位の正則化は表面的な一致に固執し、意味的な類似性や振る舞いの整合性を十分に捉えられないという課題がありました。本研究が提案するGANPOは、モデル内部の潜在表現空間において、学習対象のポリシーと参照モデルの間の乖離を敵対的学習によって抑制する新しい正則化手法です。 複数のモデルを用いた検証の結果、GANPOは既存の最適化手法に容易に組み込むことが可能であり、回答の冗長性を抑えつつ、ノイズやデータの分布変化に対しても極めて頑健な性能向上を実現することが確認されました。 この手法は、トークンレベルの制約を超えて言語の本質的な構造を維持することを可能にし、計算負荷を最小限に抑えながら、より人間に近い自然で質の高い対話能力をモデルに付与することに成功しています。
なぜこの問題か
大規模言語モデル(LLM)を人間の好みに合わせるための学習、いわゆるアライメントにおいて、現在は「選ばれた回答」と「拒絶された回答」のペアを用いた嗜好最適化が主流となっています。このプロセスでは、学習中のモデル(ポリシー)が元のモデル(参照モデル)から極端に逸脱しないように制約をかけることが、汎化性能の維持や「報酬ハッキング」と呼ばれる不正な最適化を防ぐために不可欠です。従来、この制約は主にトークンレベル、つまり単語の出現確率の分布に基づいたKL正則化などによって行われてきました。しかし、トークン空間における類似性は、必ずしも意味的または行動的な類似性を反映しないという根本的な問題が指摘されています。 例えば、「こんにちは」と「おはようございます」という二つの挨拶は、単語の並びとしては大きく異なりますが、意味的には非常に近い関係にあります。一方で、「こんにちは」と「こんにちわ」のように一文字違うだけで、単語レベルでは近くても、言語的な正確性やニュアンスが損なわれる場合もあります。このように、表面的な文字の並びだけを基準にした正則化は、モデルの振る舞いを真に制御するための指標としては不十分な側面があります。…
核心:何を提案したのか
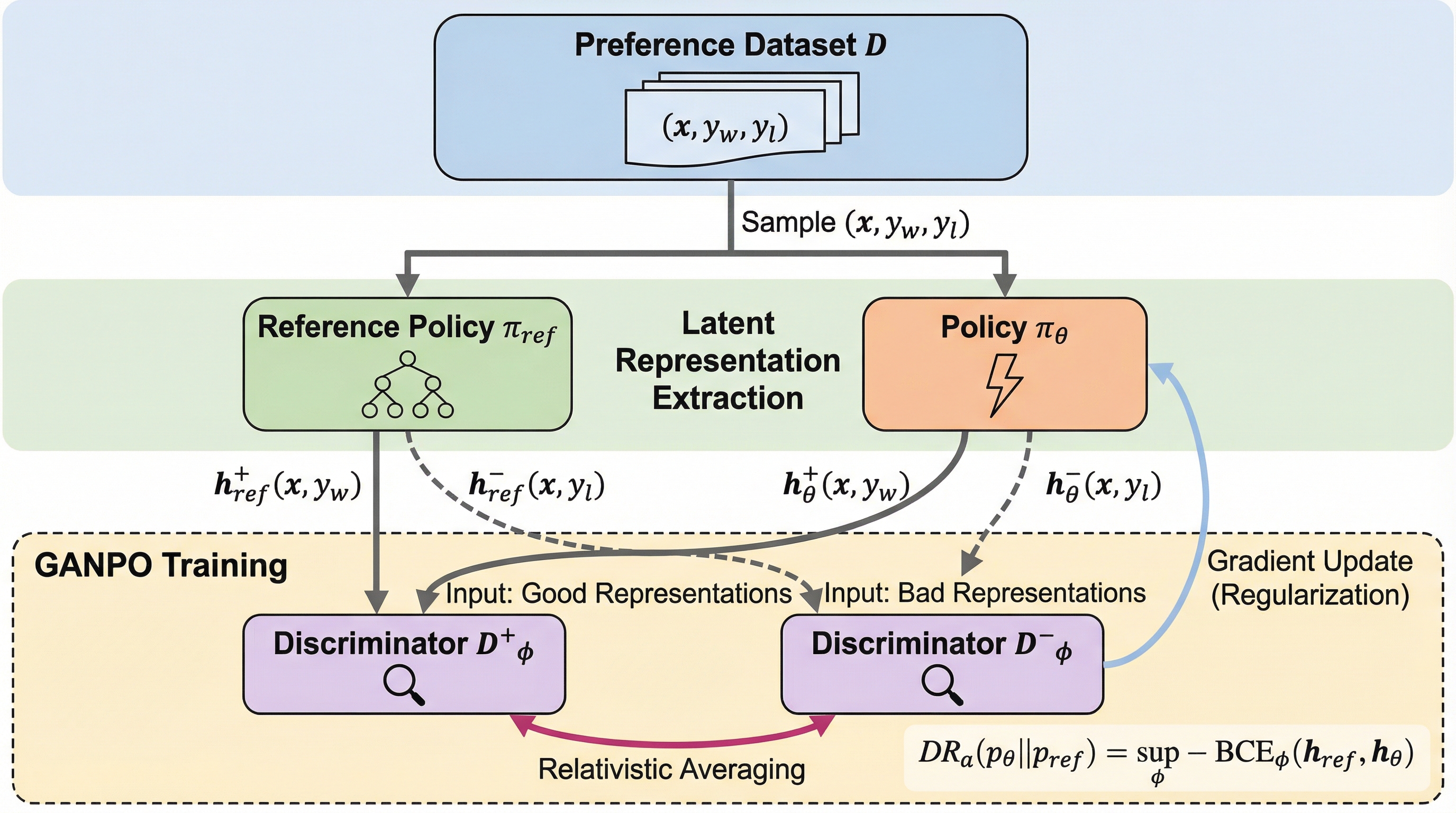
本論文では、言語モデルの嗜好最適化のための新しい潜在空間正則化手法として、GANPO(Generative Adversarial Network Preference Optimization)を提案しています。この手法の核心は、ポリシーモデルと参照モデルの内部表現(具体的には最終層の隠れ状態)の間の乖離を、敵対的学習の枠組みを用いて最小化することにあります。潜在表現は明示的な確率密度関数を持たないため、標準的なKLダイバージェンスなどの尺度を直接計算することが困難ですが、本研究ではGAN(敵対的生成ネットワーク)から着想を得た識別器を導入することで、この計算上の障壁を解決しました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related