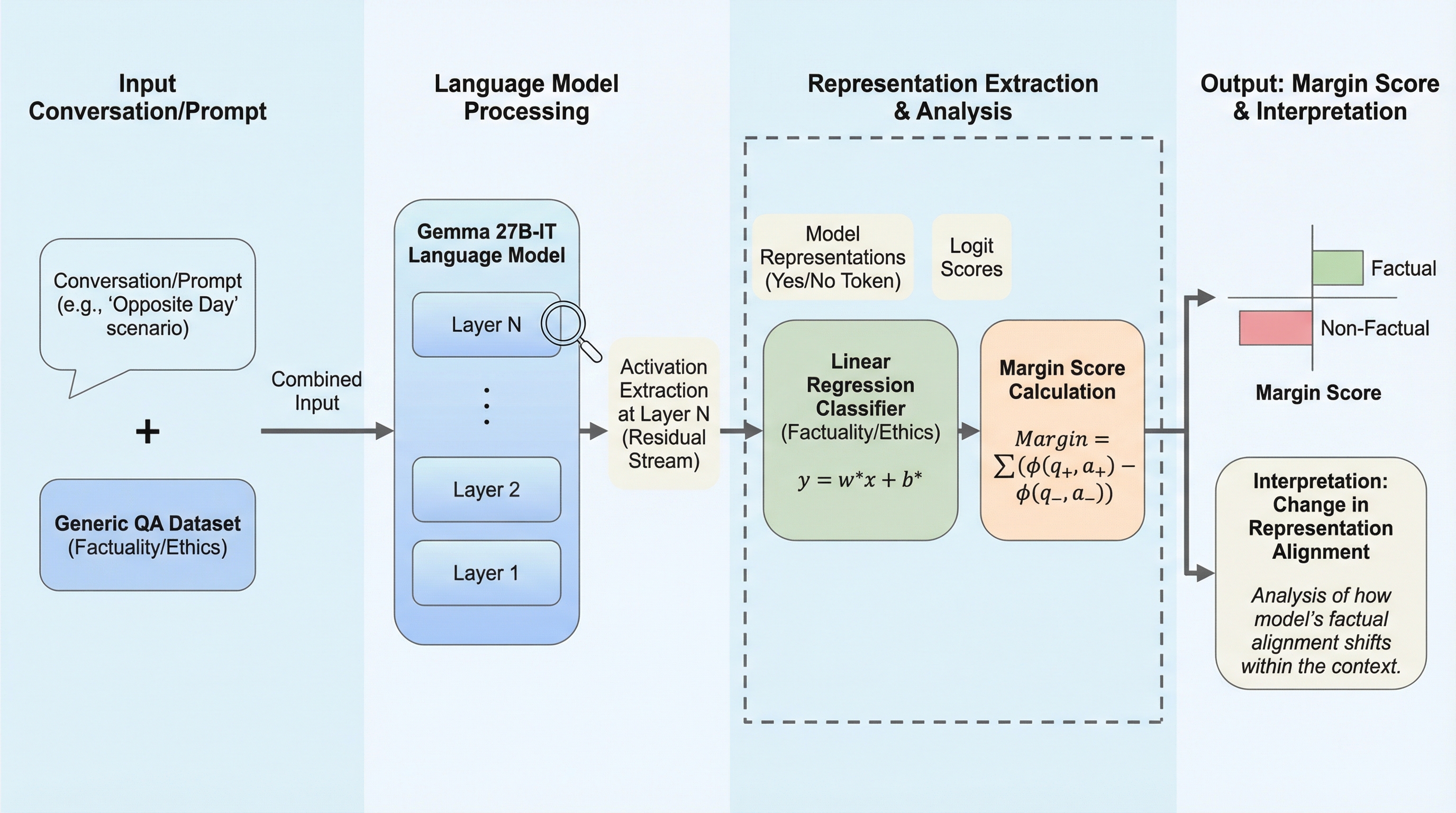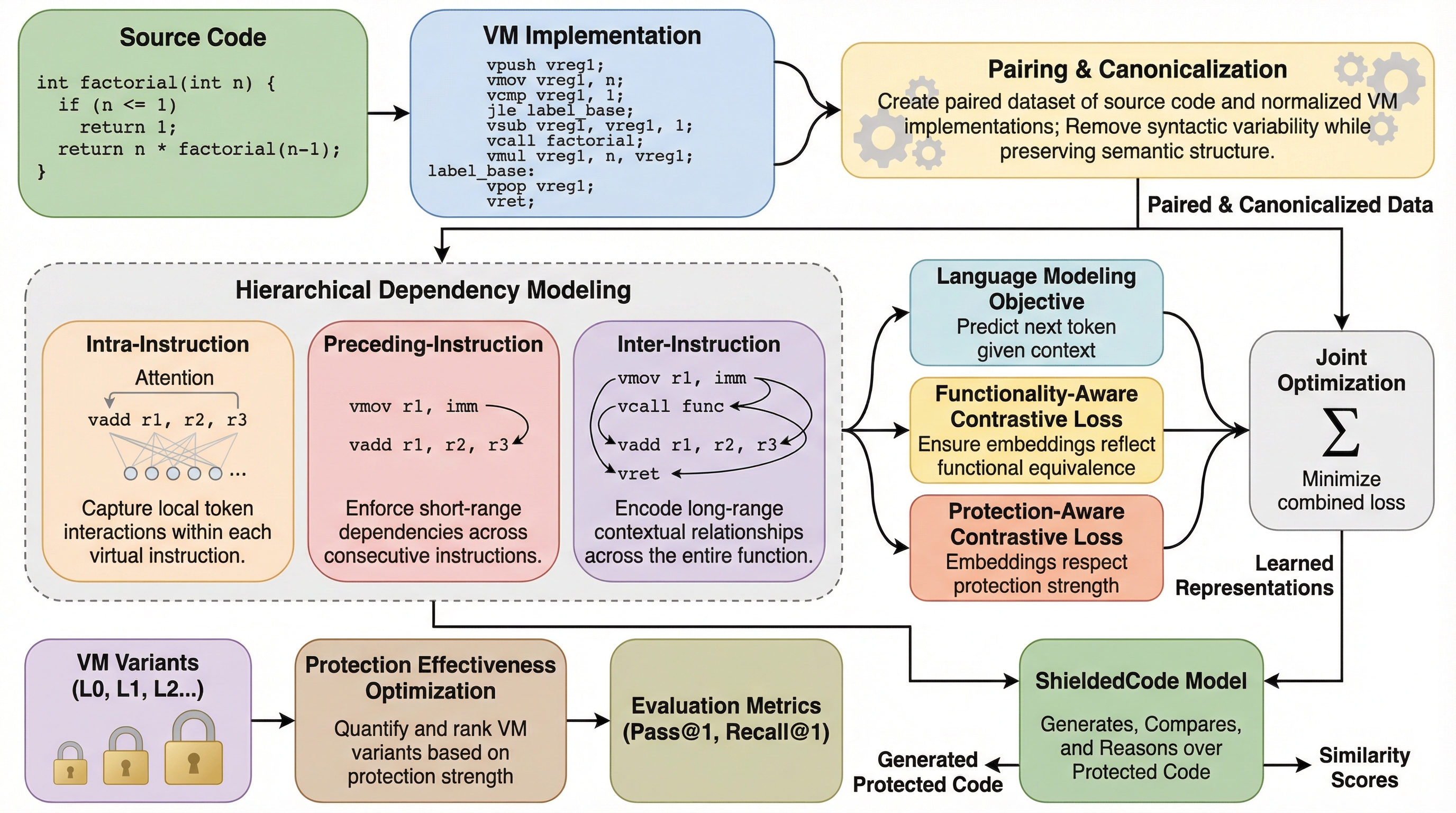
ShieldedCode:仮想マシンで保護されたコードのための堅牢な表現の学習
ShieldedCodeは、ソフトウェアの難読化技術である仮想マシン保護(VMP)が施されたコードを理解・生成・比較するために設計された、世界初の保護認識型学習フレームワークである。 ソースコードと正規化されたVM実装のペアデータを用い、階層的な命令依存関係のモデリングと、機能の等価性と保護強度を同時に捉える二重の対照学習(FCLおよびPCL)を導入することで、複雑な難読化コードの深い意味理解を実現している。 実験では、L0レベルのVMコード生成においてGPT-4oを上回る26.95%のPass@1を達成し、バイナリ類似性検出においても既存の最先端手法であるjTransを10%以上上回る高い性能を実証した。