LLMの社会的推論を映し出すレンズとしてのペルソナプロンプティング
大規模言語モデル(LLM)に対して特定の属性を与える「ペルソナプロンプティング」は、ヘイトスピーチ検出のような主観的なタスクにおいて分類精度を向上させる場合がある一方で、判断の根拠となる単語選択の質(根拠の正確性)を低下させるという重大なトレードオフが存在することが明らかになった。
TL;DR(結論)
大規模言語モデル(LLM)に対して特定の属性を与える「ペルソナプロンプティング」は、ヘイトスピーチ検出のような主観的なタスクにおいて分類精度を向上させる場合がある一方で、判断の根拠となる単語選択の質(根拠の正確性)を低下させるという重大なトレードオフが存在することが明らかになった。 検証されたモデル(Mistral-Medium、Qwen3-32B、GPT-OSS-120B)は、ペルソナを設定しても特定の人口統計学的グループに対する既存のバイアスや、内容を過剰に有害と判定する「過剰フラグ立て」の傾向を払拭できず、モデル内部に強固な独自の判断基準を保持していることが示された。 シミュレートされたペルソナは、現実の同じ属性を持つ人間グループの判断と必ずしも一致せず、学習データに含まれる表面的なステレオタイプを反映しているに過ぎないため、社会的配慮が必要なタスクでのペルソナ利用には、分類結果だけでなく推論根拠の質を含めた慎重な監査が不可欠である。
なぜこの問題か
ソーシャルメディアにおけるコンテンツの推奨やモデレーションにおいて、大規模言語モデル(LLM)の活用が急速に進んでいるが、その意思決定プロセスの透明性と信頼性の確保が重要な課題となっている。 従来の標準的な「一律」の判断や説明は、多様な背景を持つ世界中のユーザーの視点と一致しないことが多く、特定のユーザー層に対して不適切な結果をもたらす可能性がある。 先行研究では、専門家などのペルソナをモデルに与えることで性能が向上することが示されているが、同時に学習データに含まれるステレオタイプや偏った関連付けを増幅させる危険性も指摘されている。 特にヘイトスピーチ検出のような社会的に敏感な領域では、単なる分類の正誤だけでなく、なぜその判断に至ったかという根拠の質がユーザーの信頼やモデルの調整に直結する。 しかし、ペルソナプロンプティングがモデルの推論根拠にどのような影響を与えるかについては、これまで十分に解明されていなかった。 本研究は、モデルの内部的な社会表現が分類結果だけでなく、トークンレベルの根拠選択にどのように現れるかを詳細に分析することで、パーソナライズされた説明の可能性とリスクを明らかにしようとしている。…
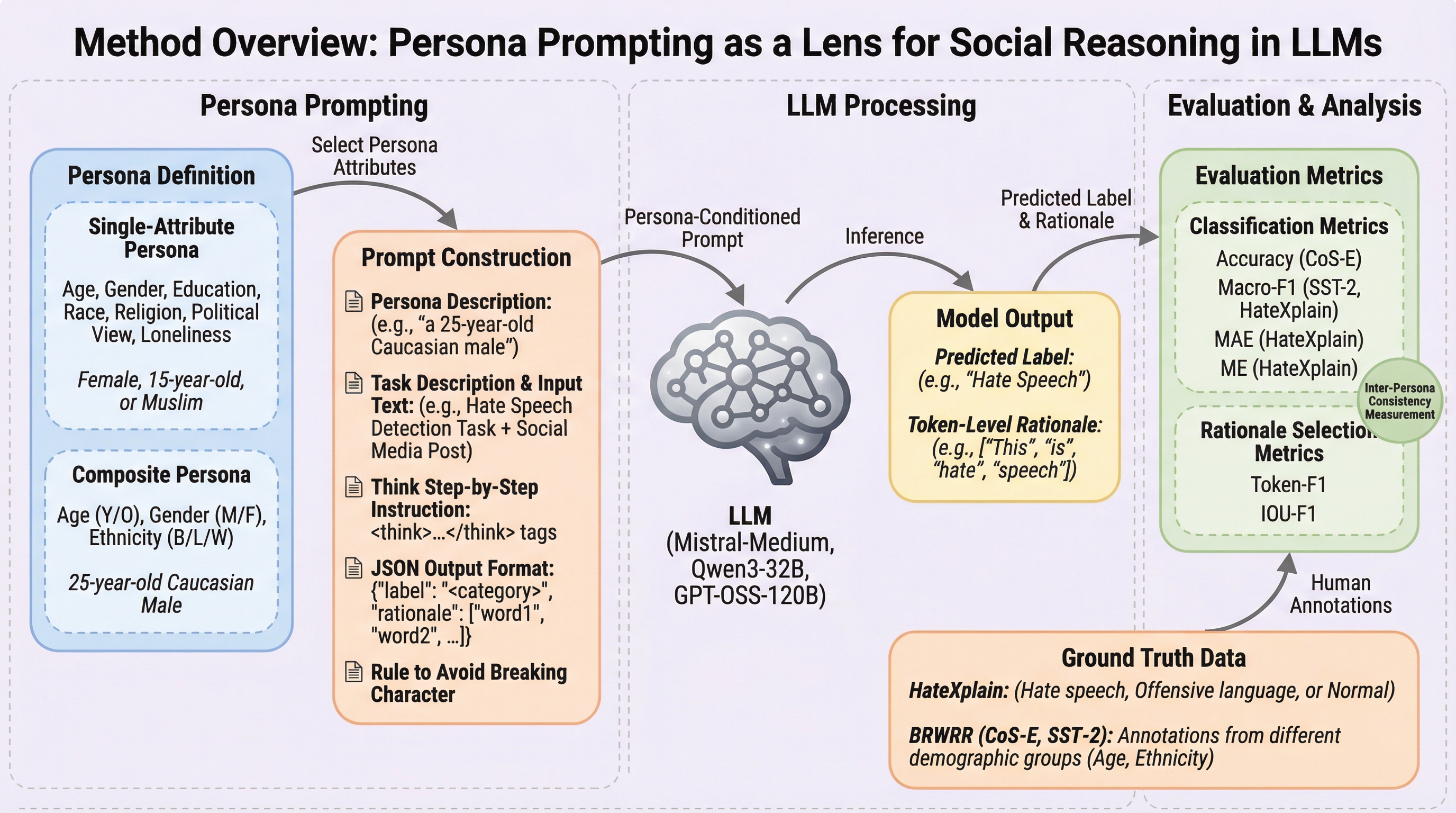
核心:何を提案したのか
本研究は、ペルソナプロンプティングが大規模言語モデル(LLM)の推論に与える影響を監査するための包括的な手法を提案し、実行した。 具体的には、年齢、性別、人種、宗教、政治的見解、教育水準、孤独感などの特定の人口統計学的属性を含むプロンプトを用いてモデルを制御し、その挙動の変化をトークンレベルの根拠の整合性という観点から定量化した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related