AgentLongBench: 長文脈エージェントのための制御可能なベンチマーク
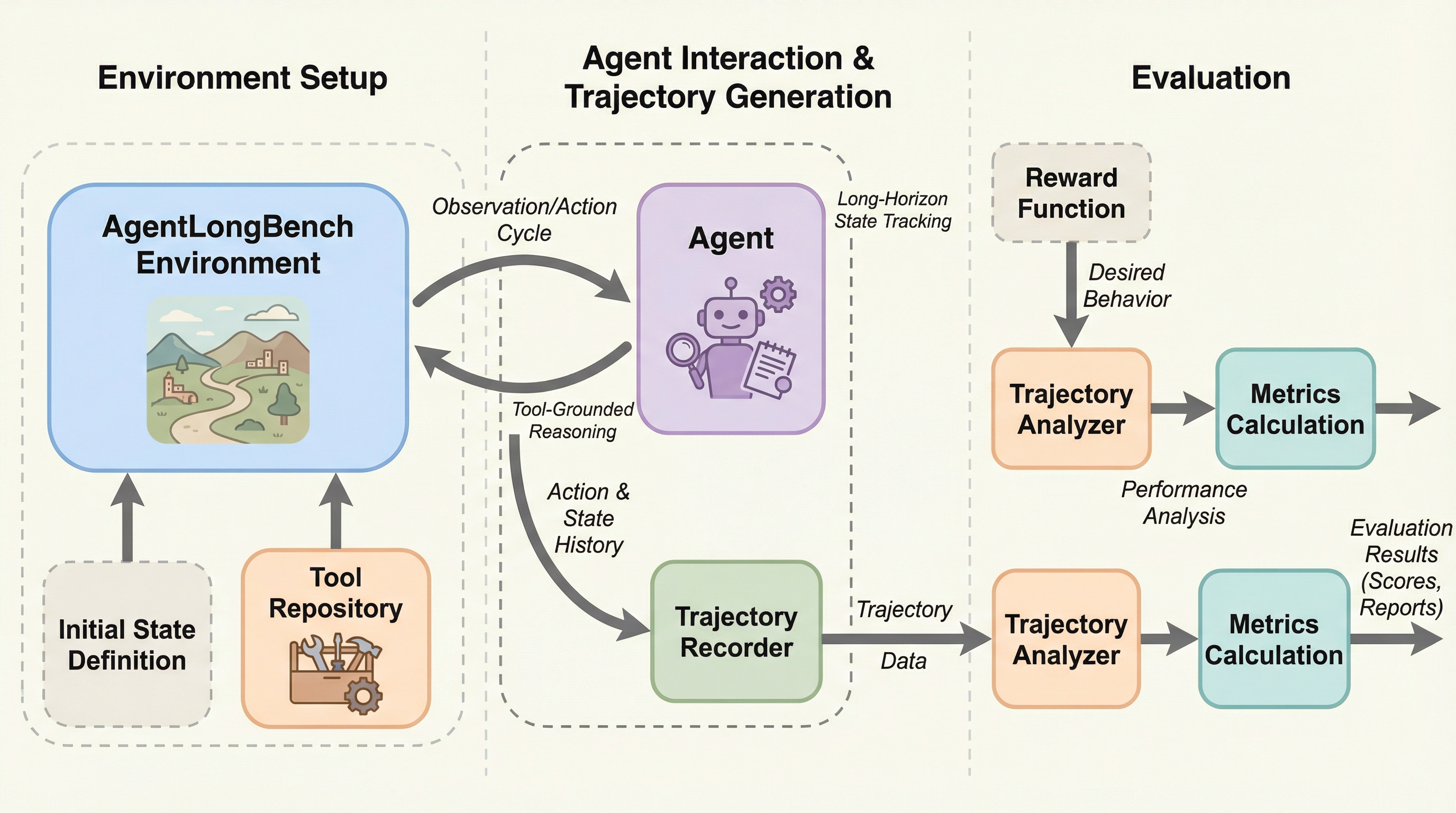
AgentLongBenchは、大規模言語モデルが自律的なエージェントとして機能するために必要な、動的で複雑な長文脈の管理能力を評価するための新しいベンチマークである。従来の静的な文書検索タスクとは異なり、水平思考パズルを用いた環境シミュレーションを通じて、エージェントと環境の相互作用や非線形な推論、反復的なフィードバックを伴うプロセスを再現している。最新のモデルやメモリシステムを最大400万トークンの文脈長で検証した結果、静的な検索には長けていても、ワークフローに不可欠な動的な情報の統合や高密度のツール応答の処理において、多くのモデルが深刻な課題を抱えていることが明らかになった。
TL;DR(結論)
AgentLongBenchは、大規模言語モデルが自律的なエージェントとして機能するために必要な、動的で複雑な長文脈の管理能力を評価するための新しいベンチマークである。従来の静的な文書検索タスクとは異なり、水平思考パズルを用いた環境シミュレーションを通じて、エージェントと環境の相互作用や非線形な推論、反復的なフィードバックを伴うプロセスを再現している。最新のモデルやメモリシステムを最大400万トークンの文脈長で検証した結果、静的な検索には長けていても、ワークフローに不可欠な動的な情報の統合や高密度のツール応答の処理において、多くのモデルが深刻な課題を抱えていることが明らかになった。
なぜこの問題か
大規模言語モデル(LLM)は、単なるチャットボットから自律的なエージェントへと急速に進化しており、複雑なワークフローを実行するために膨大な履歴情報を統合する能力が求められている。しかし、既存の評価フレームワークの多くは、依然として受動的な読解力や静的な情報の検索に偏っており、エージェントが直面する現実世界の複雑さを十分に反映できていない。現実の課題解決には、動的なツールの使用や非線形な推論が含まれ、エージェント自身の決定に基づいて文脈が刻々と変化していく。現在のデータセットに見られるような固定された人間による記述とは異なり、自律的な運用ではAIと環境の間の相互作用によって独自の軌跡が生成されるため、反復的なフィードバックループを通じた能動的な状態追跡が必要となる。 従来のベンチマークでは、人工的に連結された文書の中から孤立した事実を見つけ出すようなタスクが主流であったが、これはエージェントの核心的な行動を捉えきれていない。エージェントは、過去のツール使用ログや環境からのフィードバックを正確に追跡し、それらを統合して次の行動を計画しなければならない。…
核心:何を提案したのか
本研究では、環境ロールアウトのシミュレーションを通じてエージェントを評価する「AgentLongBench」を提案している。このベンチマークは、現実世界のワークフローにおける因果関係を反映した進化する文脈の中で、エージェントの真の能力を測定することを目指している。具体的には、水平思考パズル(Lateral Thinking Puzzles)を基盤とした環境を採用しており、エージェントは一連の論理的な制約を満たしながら隠された状態を再構築することが求められる。このパズルは、反復的な問い合わせと論理的な演繹を必要とするため、自律的なエージェントが行う複雑な調査ワークフローの厳格な代理指標として機能する。 AgentLongBenchは、エージェントが仮説を立て、フィードバックを受け取るにつれて、環境の決定論的なルールに基づいて文脈が手続き的に拡張される仕組みを持っている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related