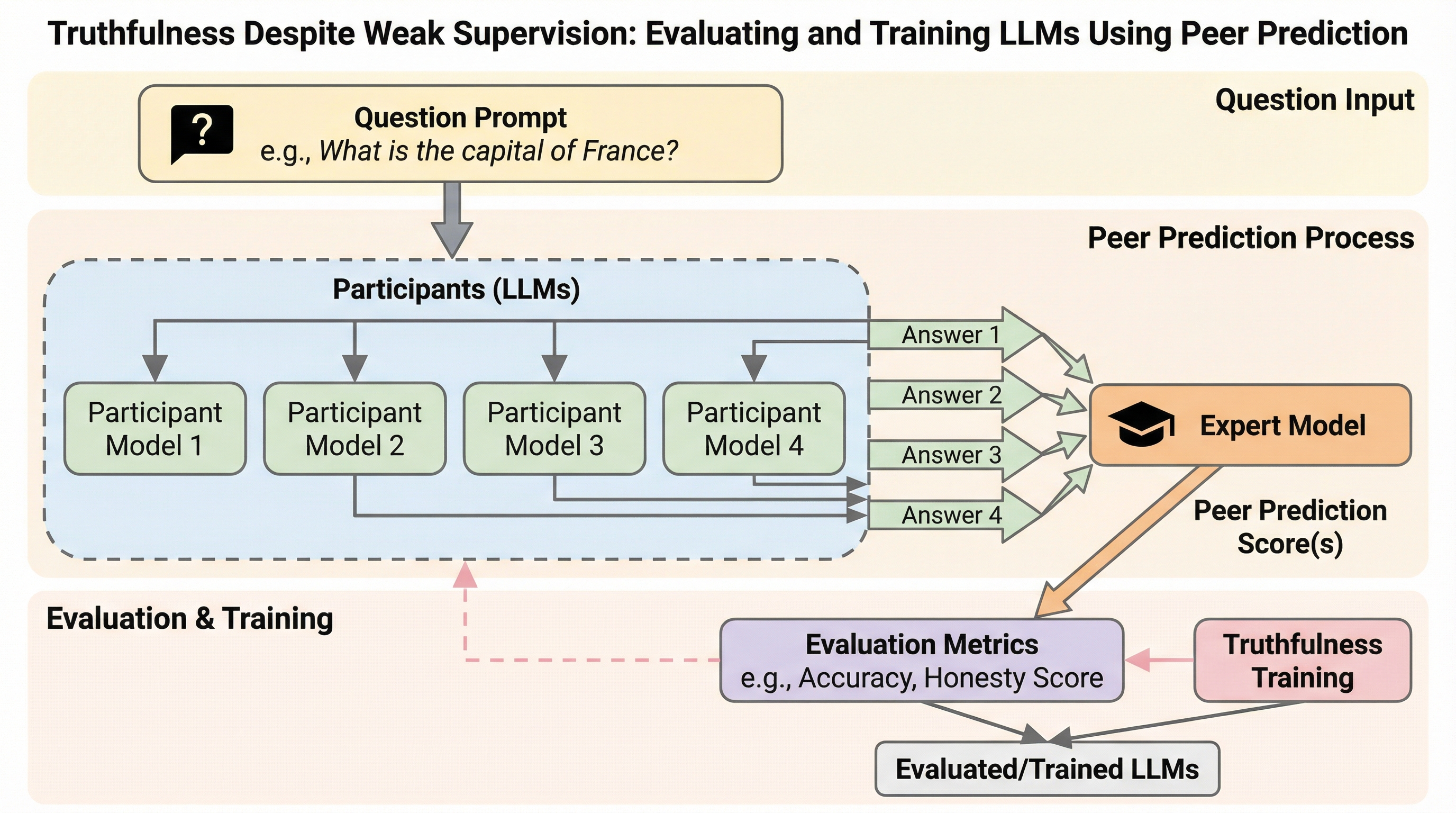
弱い教師あり学習下での真実性:ピア予測を用いたLLMの評価と訓練
大規模言語モデル(LLM)が監視者の知識不足を悪用して迎合的・欺瞞的な回答を行う問題に対し、正解ラベルを一切使用せず、回答間の「相互予測可能性」に基づいて誠実さを評価するゲーム理論的枠組み「ピア予測」を導入しました。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデル(LLM)が監視者の知識不足を悪用して迎合的・欺瞞的な回答を行う問題に対し、正解ラベルを一切使用せず、回答間の「相互予測可能性」に基づいて誠実さを評価するゲーム理論的枠組み「ピア予測」を導入しました。
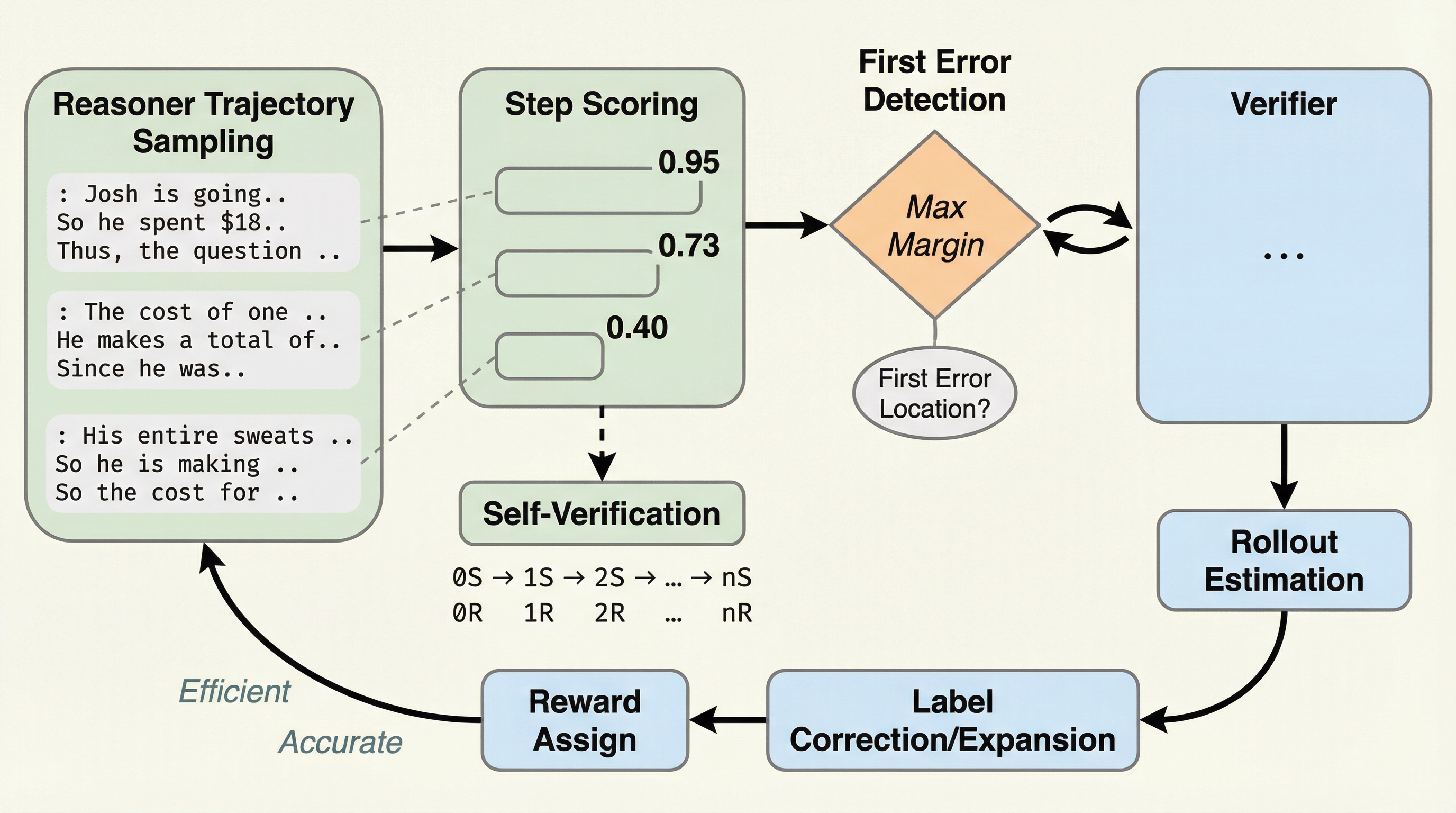
SAPO(Self-Adaptive Process Optimization)は、小規模言語モデル(SLM)の推論能力を効率的に向上させるための、自己適応型プロセス最適化フレームワークである。
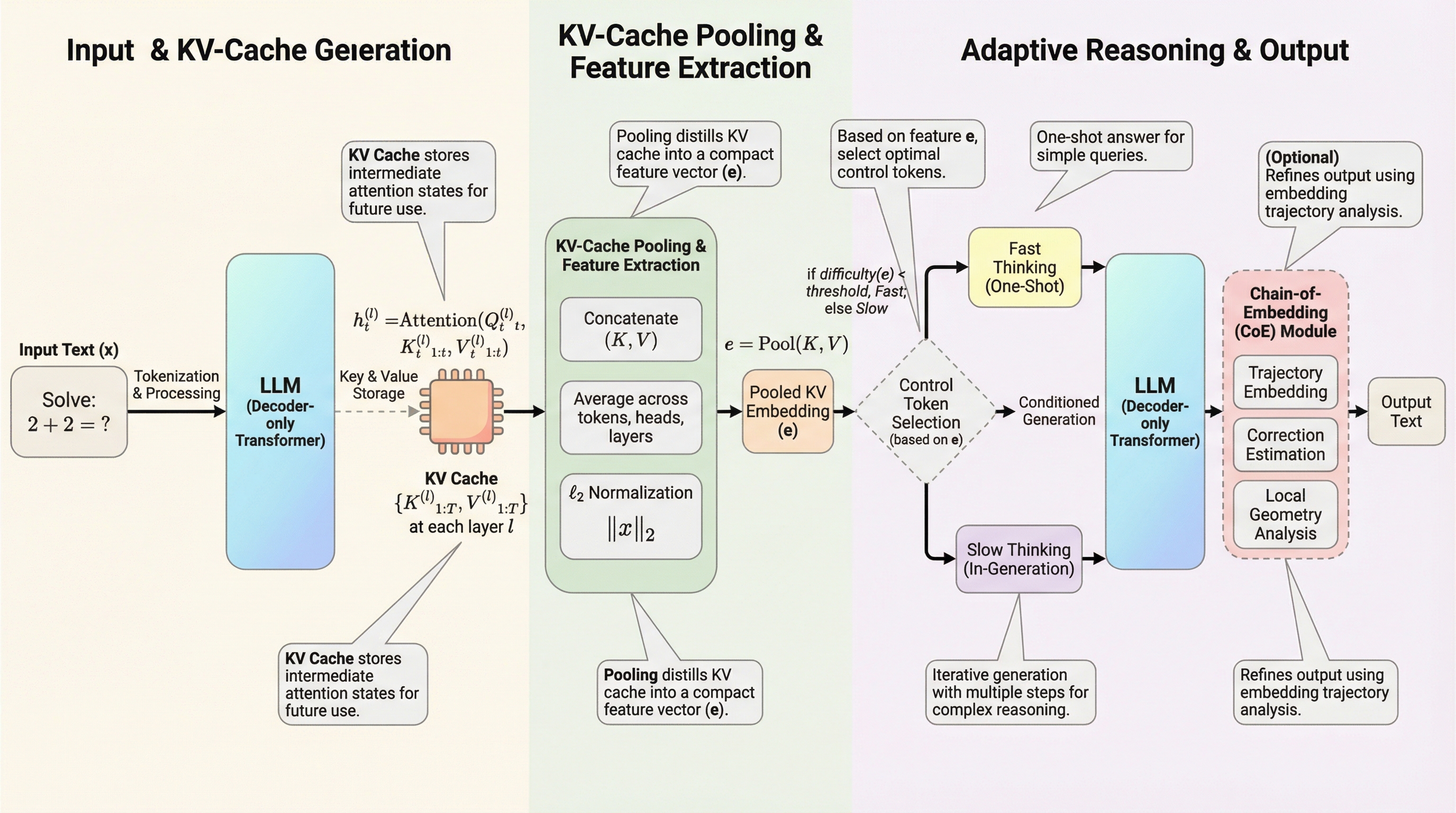
大規模言語モデルの推論を高速化するために不可欠なKVキャッシュを、単なる加速手段ではなく、下流タスクのための軽量な表現(埋め込み)として再利用する手法が提案されました。 この手法は、追加の計算コストやメモリ消費をほとんど伴わずに、推論パスの選択を行うChain-of-Embeddingや、問題の難易度に応じて思考の深さを切り替えるFast/Slow Thinking Switchに適用可能です。 実験では、Llama-3.1やQwen2などのモデルにおいて、フル状態の隠れ層を用いる手法に匹敵する性能を示しつつ、特定のタスクでは生成トークン数を最大5.7倍削減することに成功しました。
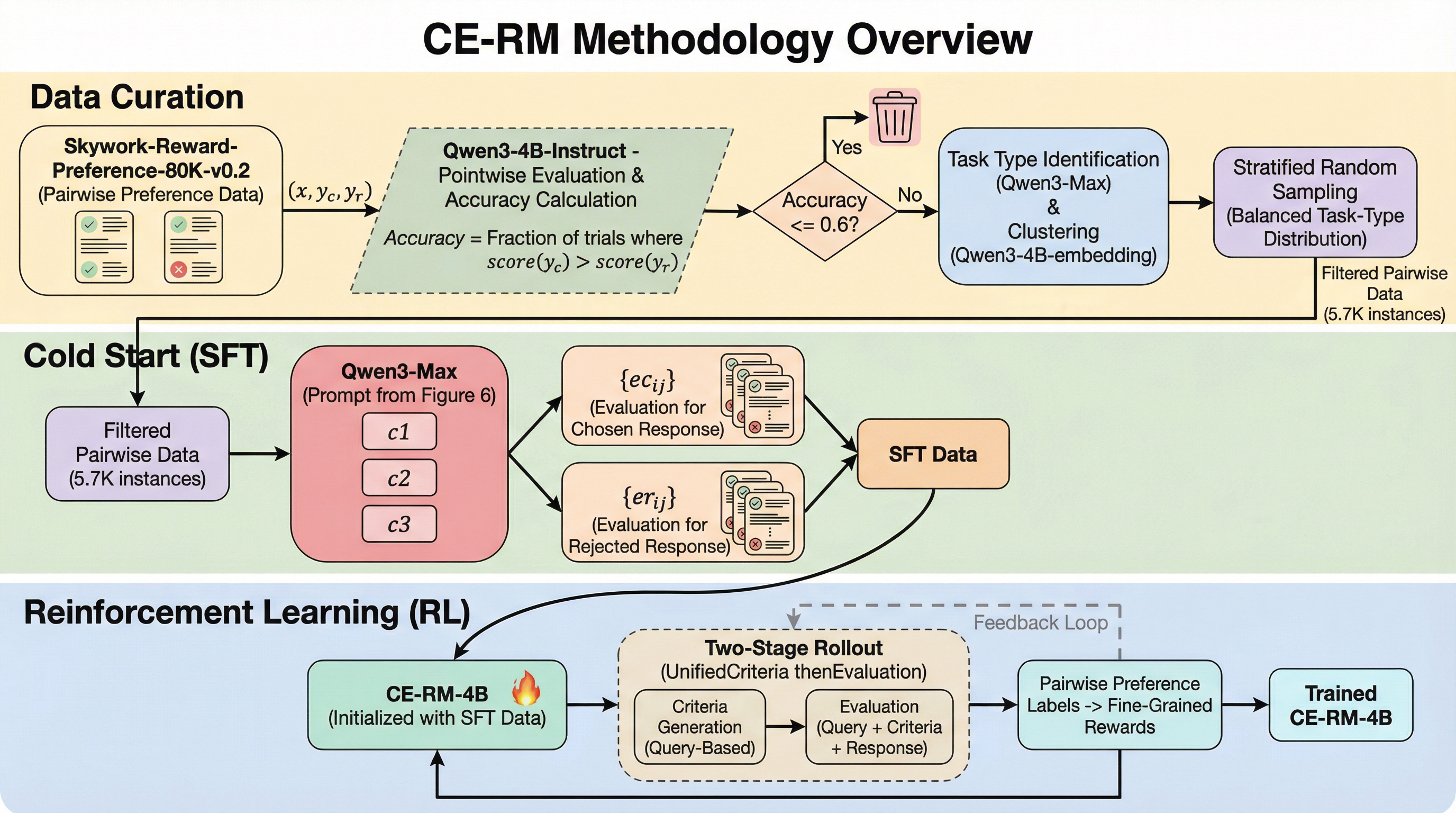
従来の生成型報酬モデルは、ベンチマークでの高スコアが実際の強化学習の成果に結びつかない「乖離」や、ペアワイズ評価による計算コストの増大、評価基準の不一致という課題を抱えていた。本研究は、クエリのみに基づいた「統一基準」を生成した後に各回答を個別に評価する、2段階ロールアウトを採用した40億パラメータのポイントワイズ報酬モデル「CE-RM-4B」を提案した。約5,700件の高品質データを用いた学習により、700億パラメータ級のモデルを凌駕する評価精度を達成し、実際の強化学習(RL)においても一貫性のある報酬信号を提供することで、下流タスクの性能を効果的に向上させることに成功した。
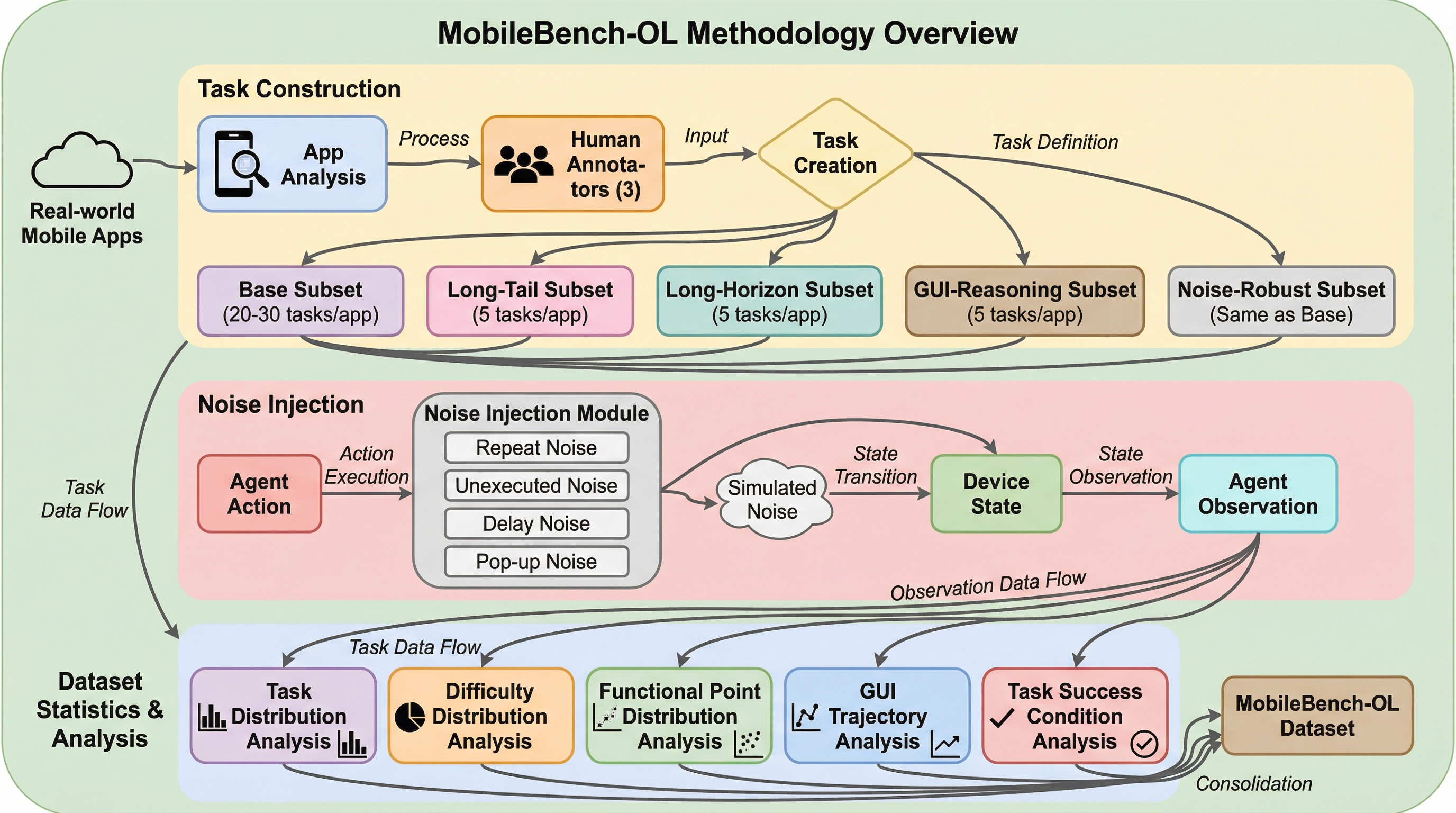
実世界のモバイル環境でGUIエージェントを評価するため、80種類の中国語アプリから1080個のタスクを収録したオンラインベンチマーク「MobileBench-OL」が開発されました。 従来の評価手法が単純な指示への追従に偏っていたのに対し、本手法は20ステップ以上の長期推論、アイコン理解や隠れた機能の探索、さらにポップアップや遅延といった実環境特有のノイズへの耐性を多角的に測定します。 自動評価フレームワークとデバイス状態を復元するリセットメカニズムを導入して12種類の主要エージェントを評価した結果、実世界の要求を満たすには依然として大きな改善の余地があることが明らかになりました。
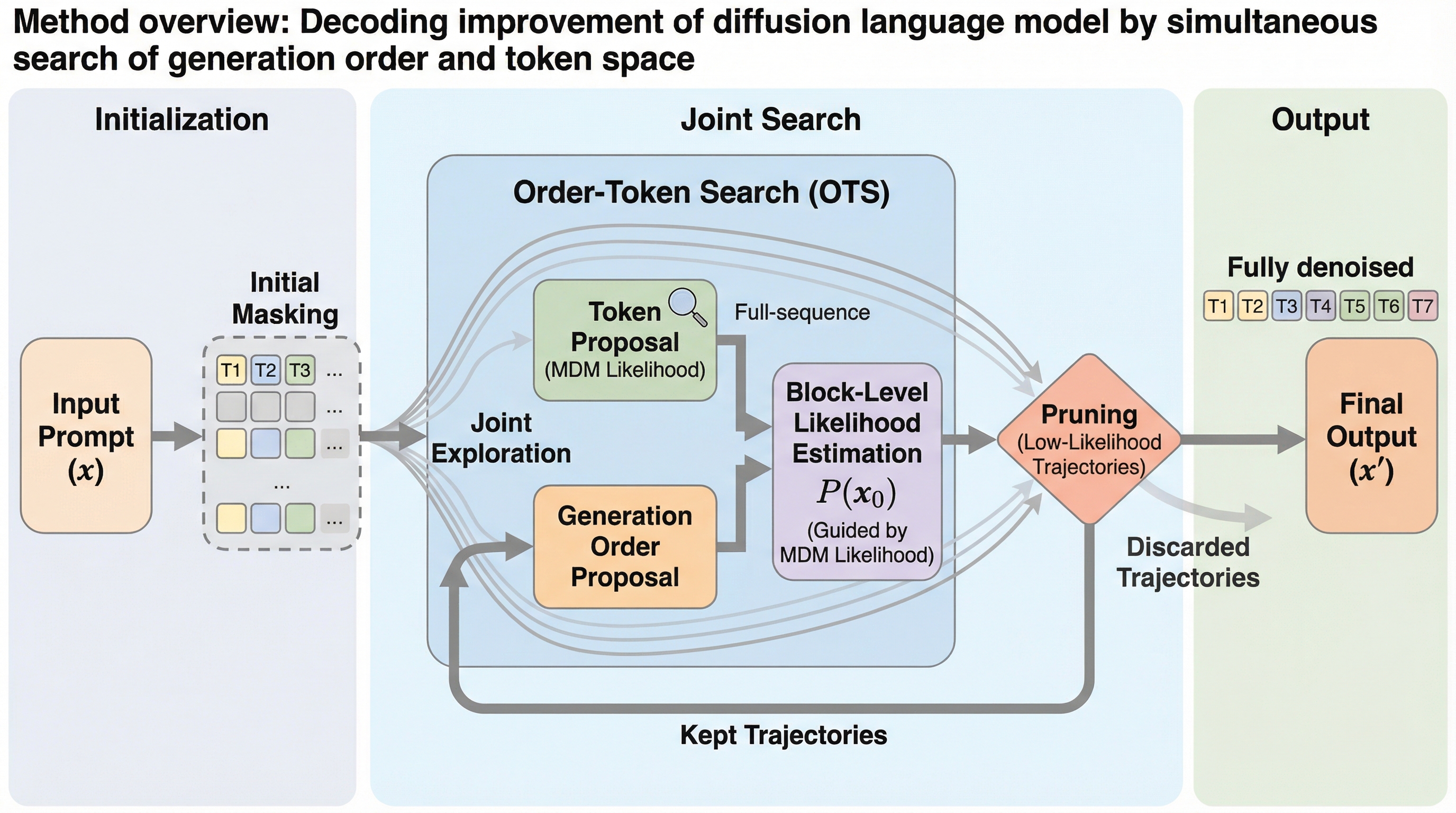
拡散言語モデル(DLM)が持つ「生成順序に依存しない」という潜在的な利点を引き出すため、生成順序とトークンの値を同時に探索する新しいアルゴリズム「Order-Token Search」が提案されました。
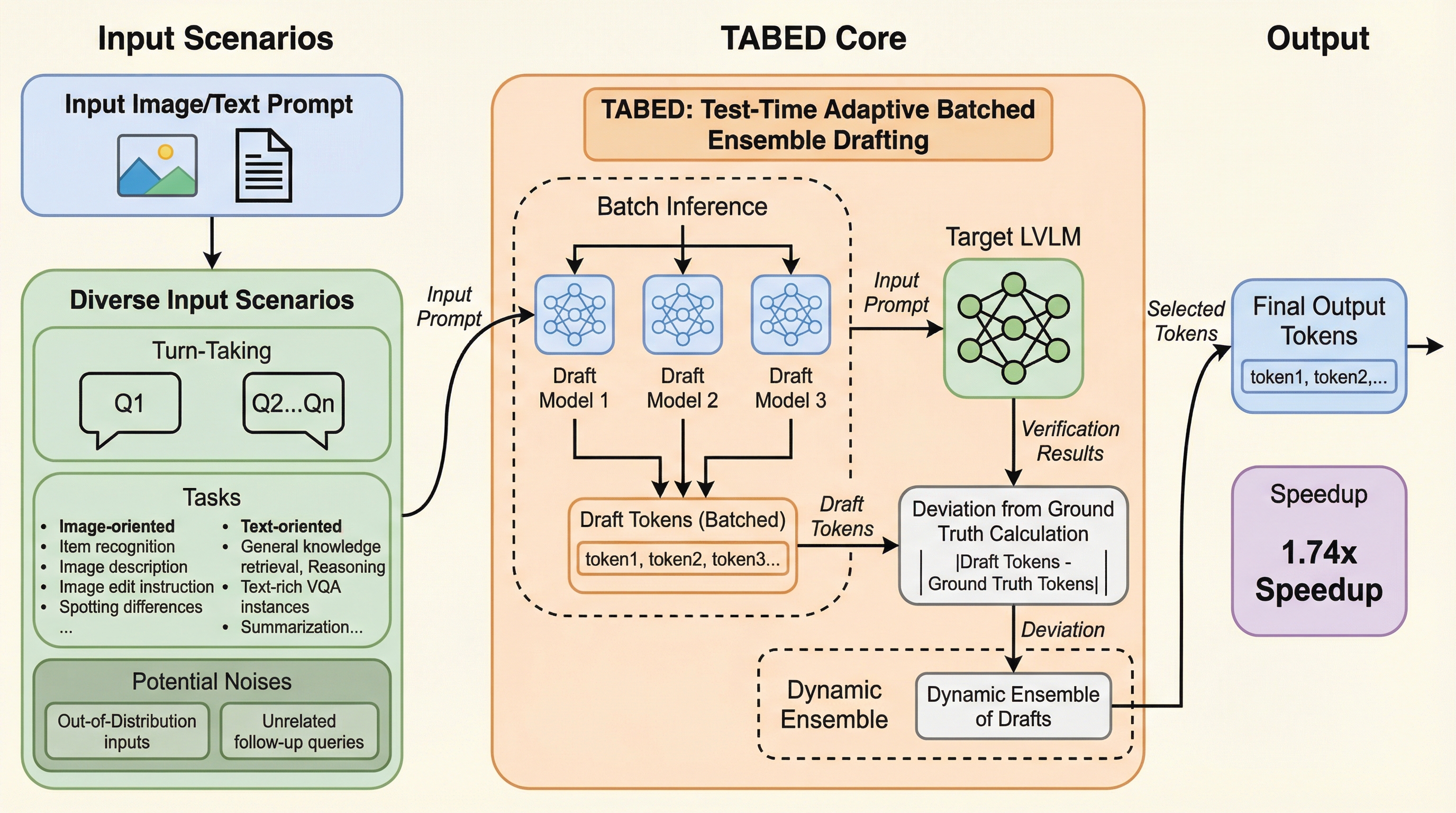
大規模視覚言語モデル(LVLM)の推論を大幅に加速させるため、複数のドラフトモデルをテスト時に動的に統合する新手法「TABED」が提案されました。従来の推測デコーディングでは、視覚情報の有無によって加速性能が不安定になる課題がありましたが、本手法は過去の検証結果から最適な重みを適応的に決定することで、多様なシナリオで一貫した高速化を実現します。追加の学習を一切必要としないプラグアンドプレイな設計でありながら、平均で1.74倍の速度向上を達成し、既存の単一ドラフト手法を5%以上上回る堅牢な性能を幅広いベンチマークで示しました。
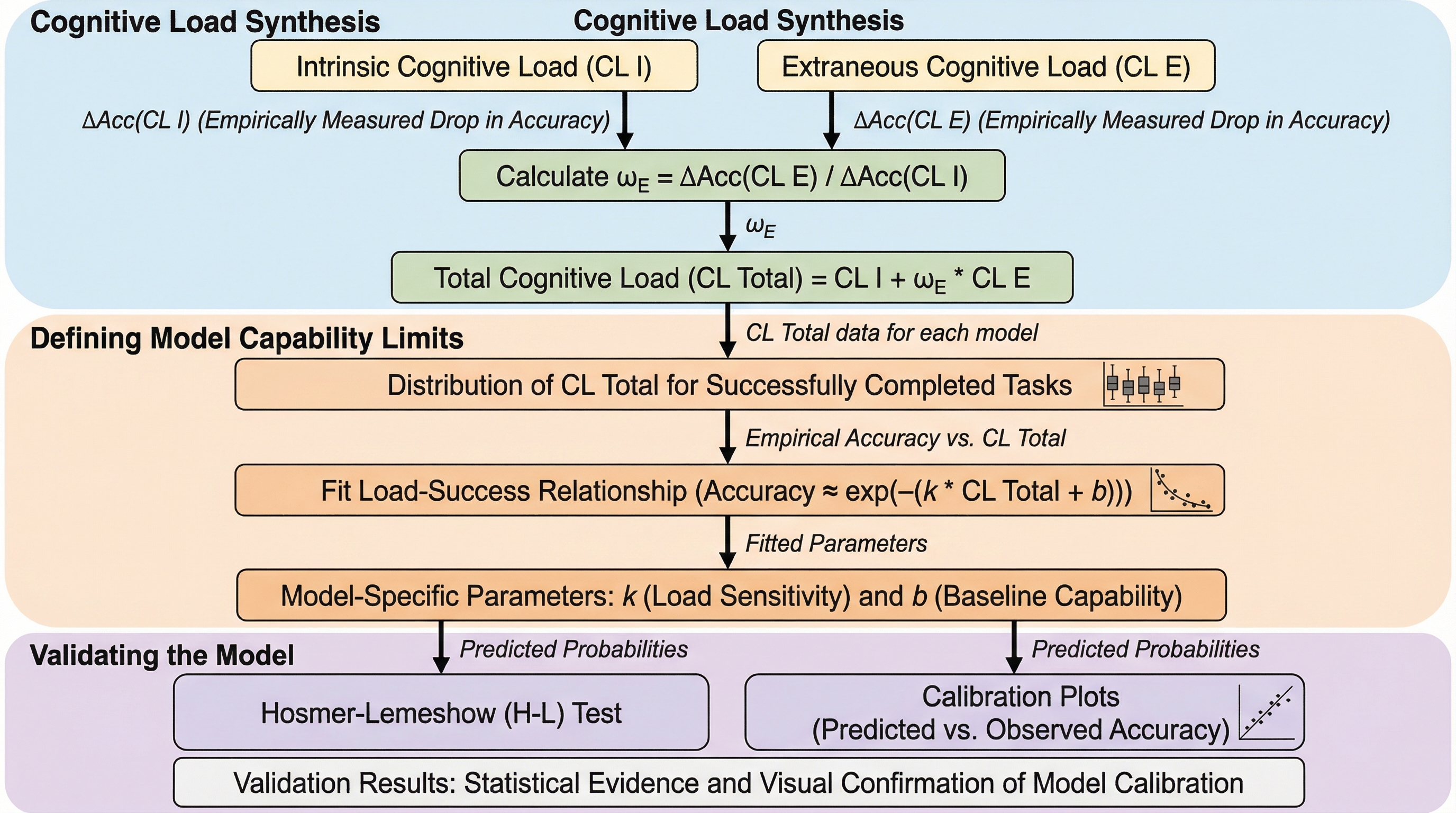
従来のベンチマークは最終的な精度のみを報告し、モデルが失敗する原因となる認知的ボトルネックを隠蔽していたが、本研究は認知負荷理論(CLT)に基づき、タスクの複雑さを構造的な「本質的負荷」と提示方法による「外来的負荷」に分解して定量化する新しい評価フレームワークを提案した。
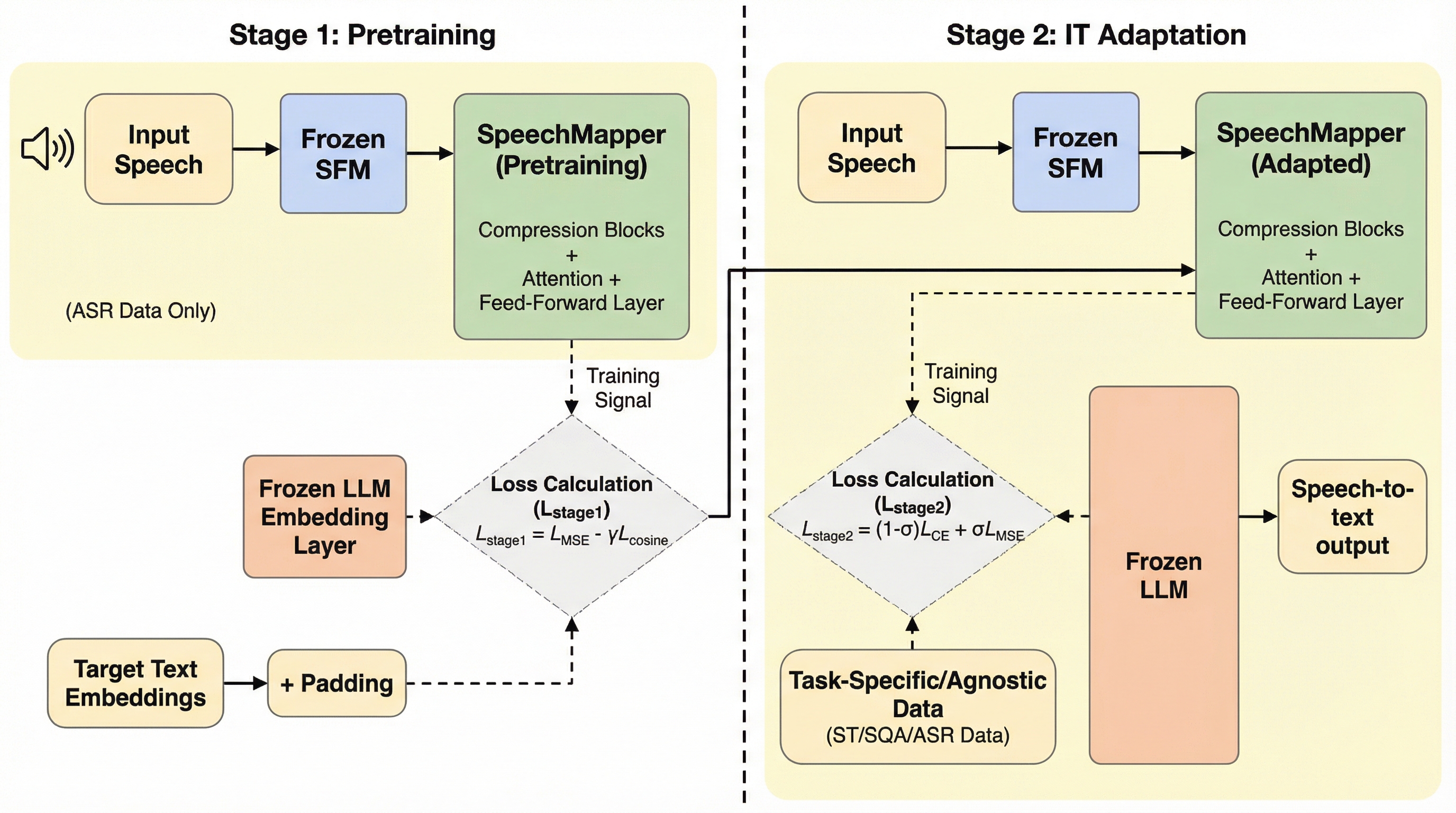
SpeechMapperは、音声基礎モデルの出力を大規模言語モデル(LLM)の埋め込み空間へ直接写像する、計算コスト効率に優れた2段階の学習手法を提案しており、従来の膨大な計算資源とデータを必要とする音声・LLM統合手法が抱えていた高コストかつ過学習しやすいという深刻な課題を解決する画期的なアプローチである。
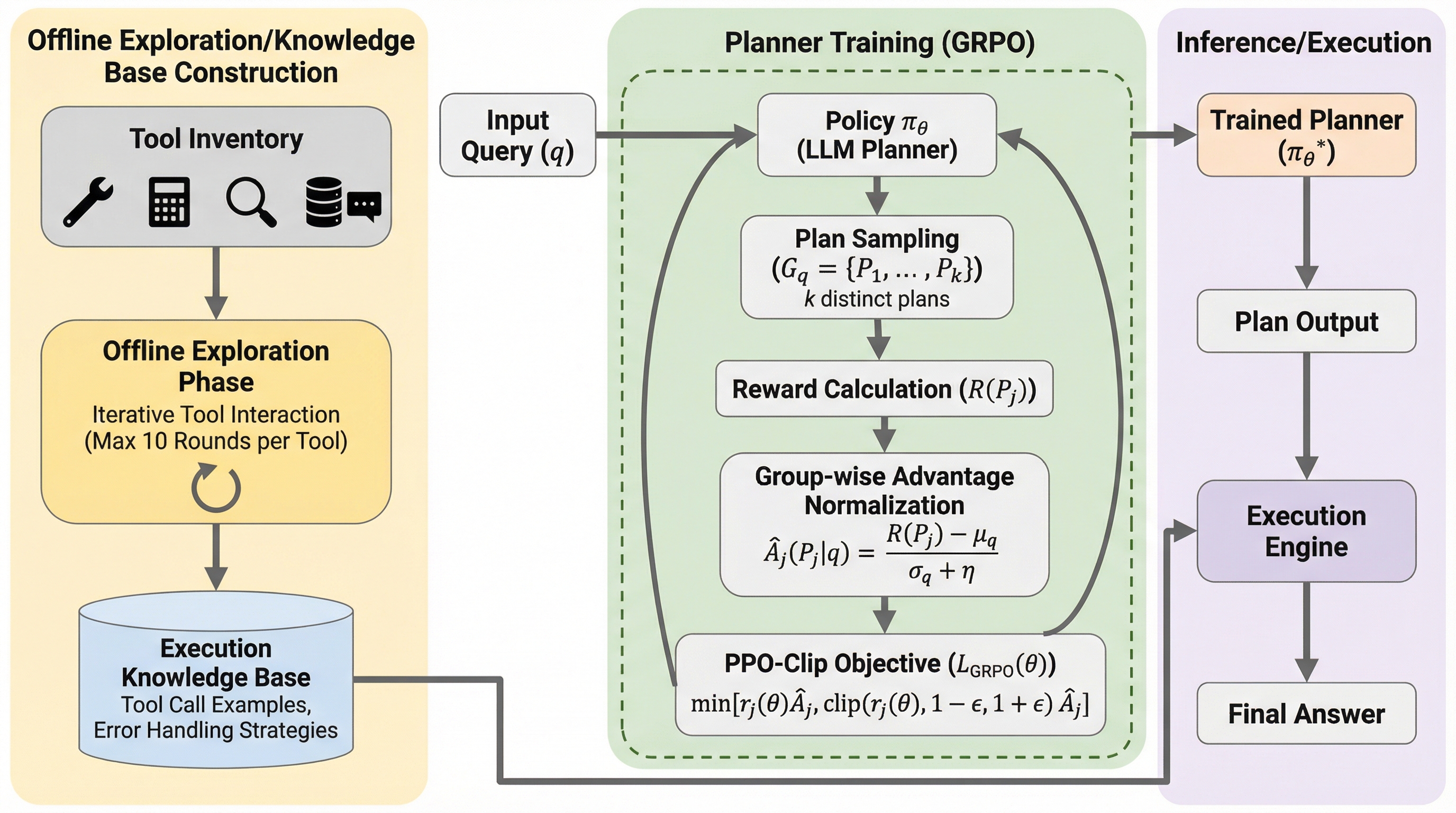
PEARLは、大規模言語モデルが複雑な多段階のツール呼び出しにおいて直面する、計画能力の欠如やツールの幻覚、誤ったパラメータ生成といった深刻な課題を解決するために開発された新しいフレームワークである。