SAPO: 自己適応的なプロセス最適化が小規模推論モデルを強力にする
SAPO(Self-Adaptive Process Optimization)は、小規模言語モデル(SLM)の推論能力を効率的に向上させるための、自己適応型プロセス最適化フレームワークである。
TL;DR(結論)
SAPO(Self-Adaptive Process Optimization)は、小規模言語モデル(SLM)の推論能力を効率的に向上させるための、自己適応型プロセス最適化フレームワークである。人間が誤りを即座に検知して修正する認知メカニズム(ERN)に着想を得て、推論過程における「最初のエラー位置」を特定し、そこを集中的に検証・修正することで、従来のモンテカルロ法に比べて計算コストを大幅に削減しながら高品質なプロセス報酬信号を生成する。数学(GSM8K)やコード生成(MBPP)のベンチマークにおいて、既存のGRPOやRFTといった主要な自己進化手法を上回る性能を達成し、反復的な学習を通じて推論器と検証器の間の性能乖離を効果的に解消することに成功した。
なぜこの問題か
現在の大型言語モデル(LLM)は、思考の連鎖(CoT)を用いることで複雑な多段階の計画や推論において優れた性能を発揮しているが、その膨大な計算コストやストレージコストが実用上の大きな障壁となっている。そのため、モバイルデバイスなどのリソースが限られた環境でも動作可能な、効率的で強力な小規模言語モデル(SLM)の開発が強く望まれている。これまでの研究では、モデルを自己進化させる手法が提案されてきたが、20億パラメータ以下の小規模モデルは指示に従う能力や推論能力が根本的に低いため、大規模モデルで一般的に使われる報酬評価手法をそのまま適用するのが難しいという問題があった。特に、既存の自己進化手法の多くは、推論の最終的な結果のみに報酬を与える「結果報酬」に依存しており、推論の途中の細かいステップに対するフィードバックを軽視する傾向がある。これにより、モデルが誤った推論過程を経て偶然正しい答えに辿り着く「報酬ハッキング」が発生しやすくなり、真の推論能力の向上が妨げられる。…
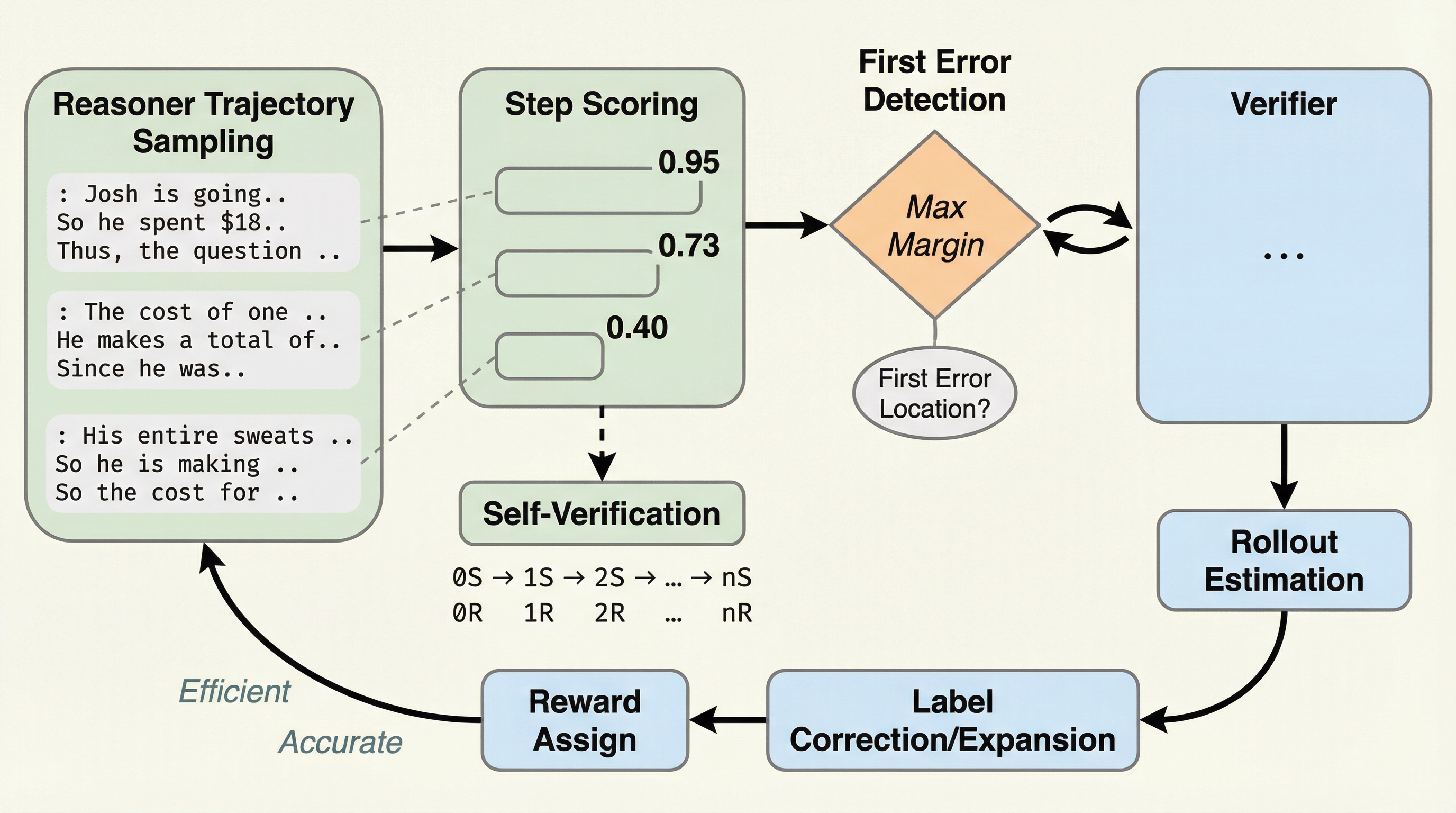
核心:何を提案したのか
本研究では、この課題を解決するために「自己適応的なプロセス最適化(SAPO)」という新しい手法を提案している。この手法の最大の特徴は、人間が誤った判断を下した直後にそれを自発的に検知し、修正を行う「エラー関連陰性電位(ERN)」という認知心理学的なメカニズムをAIの学習に取り入れた点にある。SAPOは、すべての推論ステップを一律に検証するのではなく、エラーが発生した可能性が最も高い箇所を特定し、そこを集中的に修正することで、プロセス監視の効率を劇的に高めている。具体的には、検証器が推論ステップごとにスコアを割り当て、スコアの変化が最も大きい箇所を「最初のエラー位置」として予測する。その後、推論器自身がその特定の箇所に対してのみ少数のロールアウト(事後推定)を行い、検証器の予測が正しかったかどうかを確認する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related