生成順序とトークン空間の同時探索による拡散言語モデルのデコーディング改善
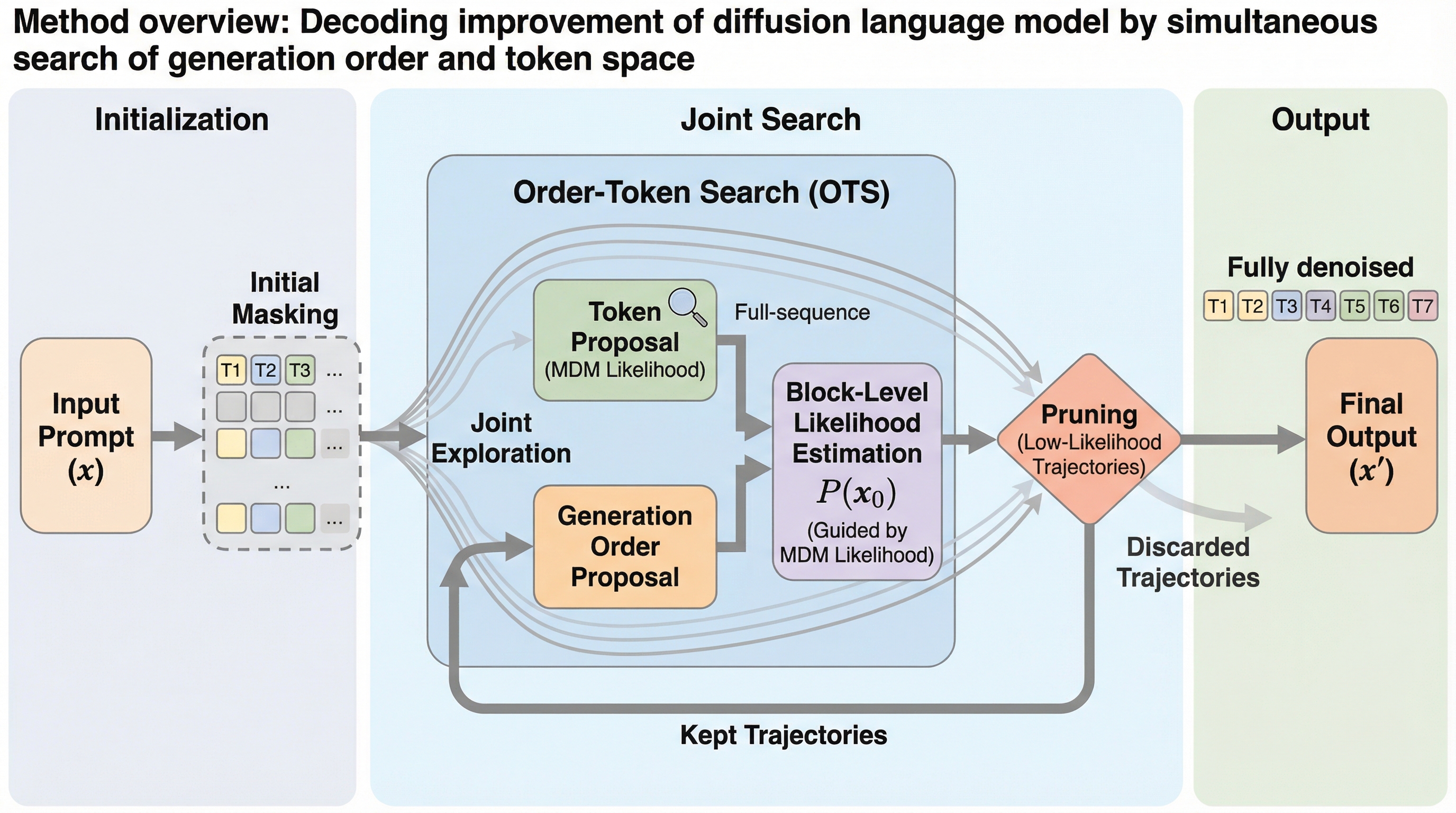
拡散言語モデル(DLM)が持つ「生成順序に依存しない」という潜在的な利点を引き出すため、生成順序とトークンの値を同時に探索する新しいアルゴリズム「Order-Token Search」が提案されました。
TL;DR(結論)
拡散言語モデル(DLM)が持つ「生成順序に依存しない」という潜在的な利点を引き出すため、生成順序とトークンの値を同時に探索する新しいアルゴリズム「Order-Token Search」が提案されました。 この手法は、デノイジングの過程で複数の候補(ビーム)を保持し、独自の尤度推定器を用いて有望な軌跡を効率的に絞り込むことで、従来の単一の軌跡に依存するデコーディング手法の限界を打破しています。 数学的推論やコード生成のベンチマークにおいて、追加学習なしで従来の最高水準を大幅に上回る精度を達成し、事後学習(diffu-GRPO)を行ったモデルに匹敵、あるいはそれを超える性能を示しました。
なぜこの問題か
拡散言語モデル(DLM)は、従来の自己回帰型モデルとは異なり、テキストを左から右へと順番に生成する制約がなく、並列的かつ柔軟な順序でデノイジングを行うことができるという独自の強みを持っています。しかし、これまでのデコーディング手法はこの「順序の柔軟性」という特性を十分に活用できておらず、一度の生成プロセスにおいて単一の軌跡(トラジェクトリ)のみを選択するという制約に縛られていました。具体的には、モデルが確信を持っているトークンを早期に固定する「低信頼度リマスキング」のような手法は、局所的な最適解に陥りやすく、一度誤った選択をするとその後の修正が困難になるという「過度な活用(exploitation)」の問題を抱えています。一方で、学習時のノイズ付加を模倣する「ランダムリマスキング」は、多様な生成順序を探索できるものの、どの軌跡が正解に近いかを判断する客観的な基準が欠けているため、単一サンプルでの精度が低くなる「盲目的な探索(exploration)」の状態にありました。…
核心:何を提案したのか
本研究では、生成順序とトークン空間の同時探索を可能にする新しいデコーディングアルゴリズム「Order-Token Search」を提案しています。この手法の核心は、デノイジングの過程で複数の「ビーム(候補)」を保持し、各ステップにおいて「どの位置を更新するか(順序)」と「どのトークンを書き込むか(値)」の両方の選択肢を動的に広げながら探索を進める点にあります。従来のヒューリスティックな手法が単一の経路を突き進むのに対し、提案手法は複数の有望な中間状態を維持し、モデル自身の尤度予測に基づいてそれらを評価・選別します。これにより、局所的な最適解に囚われることなく、より広範な解決策の空間を探索することが可能になります。 この手法の大きな特徴は、モデルの追加学習や微調整を一切必要とせず、推論時のアルゴリズムを変更するだけで性能を劇的に向上させることができる点にあります。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related