CE-RM:2段階ロールアウトと統一基準で最適化された4Bパラメータの生成型報酬モデル
従来の生成型報酬モデルは、ベンチマークでの高スコアが実際の強化学習の成果に結びつかない「乖離」や、ペアワイズ評価による計算コストの増大、評価基準の不一致という課題を抱えていた。本研究は、クエリのみに基づいた「統一基準」を生成した後に各回答を個別に評価する、2段階ロールアウトを採用した40億パラメータのポイントワイズ報酬モデル「CE-RM-4B」を提案した。約5,700件の高品質データを用いた学習により、700億パラメータ級のモデルを凌駕する評価精度を達成し、実際の強化学習(RL)においても一貫性のある報酬信号を提供することで、下流タスクの性能を効果的に向上させることに成功した。
TL;DR(結論)
従来の生成型報酬モデルは、ベンチマークでの高スコアが実際の強化学習の成果に結びつかない「乖離」や、ペアワイズ評価による計算コストの増大、評価基準の不一致という課題を抱えていた。本研究は、クエリのみに基づいた「統一基準」を生成した後に各回答を個別に評価する、2段階ロールアウトを採用した40億パラメータのポイントワイズ報酬モデル「CE-RM-4B」を提案した。約5,700件の高品質データを用いた学習により、700億パラメータ級のモデルを凌駕する評価精度を達成し、実際の強化学習(RL)においても一貫性のある報酬信号を提供することで、下流タスクの性能を効果的に向上させることに成功した。
なぜこの問題か
自然言語生成の自動評価は、長年解決が困難な課題として認識されてきた。数学やプログラミングのような検証可能なタスクであればルールベースの指標が機能するが、オープンエンドな対話やクリエイティブな執筆、複雑な指示に従うタスクでは、正解が一つではないため評価が極めて難しい。従来のBLEUやROUGEといった文字列一致に基づく指標は、高品質な参照情報を必要とする上に、意味的な変化に対する頑健性が低いという弱点があった。近年の大規模言語モデル(LLM)の発展により、モデル自身に評価を行わせる「LLM-as-a-Judge」という手法が登場し、人間のような柔軟な評価が可能になりつつある。しかし、既存の生成型報酬モデル(GRM)には、ベンチマークでの高いスコアが実際の強化学習(RL)での性能向上に必ずしも結びつかないという「乖離」の問題が指摘されている。 この問題の主な原因の一つは、多くのモデルが2つの回答を比較するペアワイズ評価に依存していることにある。…
核心:何を提案したのか
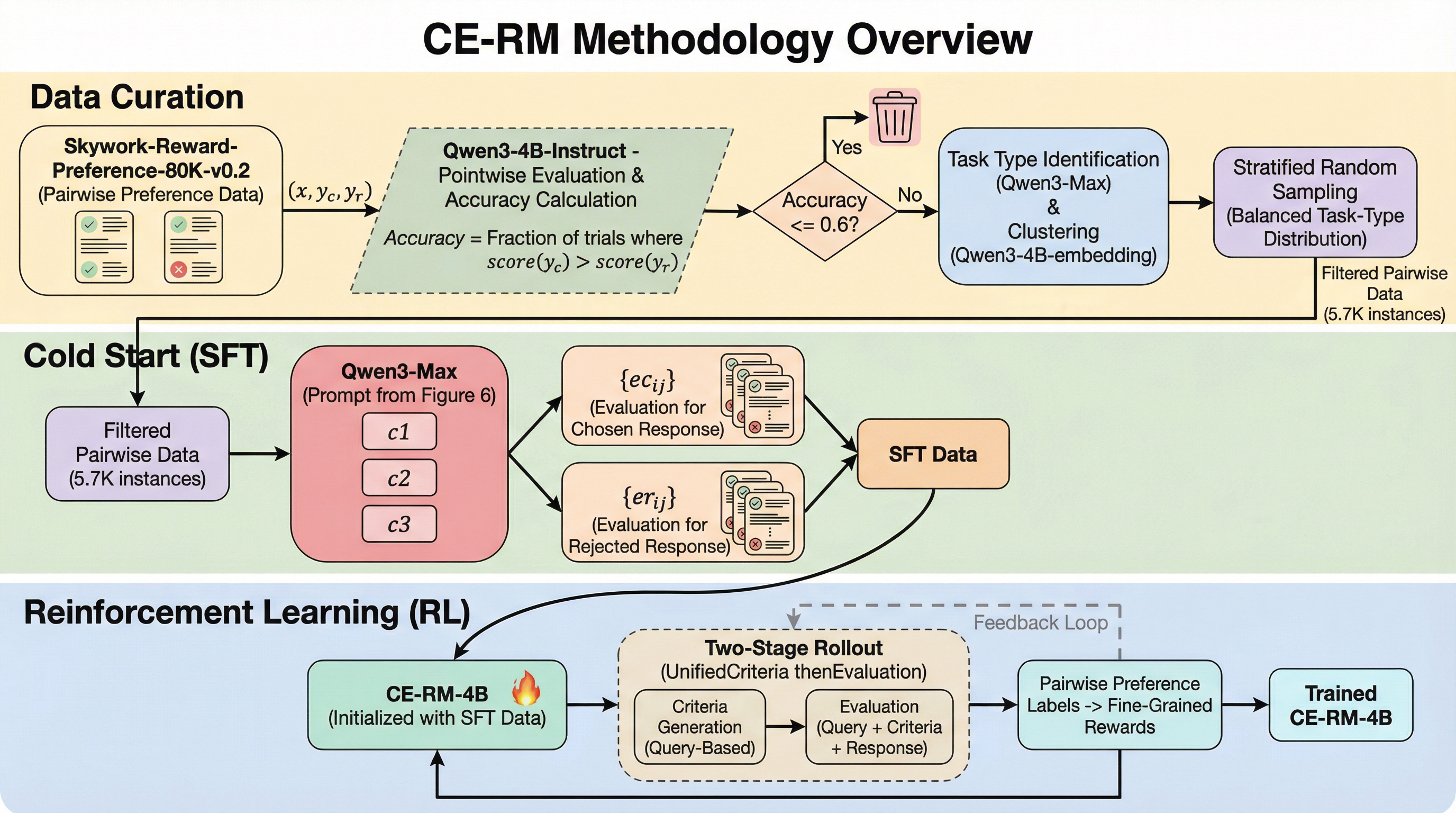
本研究では、評価プロセスを「基準生成」と「評価実行」の2つの段階に明確に分離した、40億パラメータのポイントワイズ生成型報酬モデル「CE-RM-4B」を提案した。このモデルの核心的なアイデアは、まずクエリのみを参照して「統一的な評価基準」を生成し、その後にその基準を用いて各回答を個別に分析・スコアリングするという2段階のロールアウト手法である。これにより、同じクエリに対する複数の回答を比較する際、全く同じ基準で公平に評価することが可能になり、評価の客観性と一貫性が大幅に向上する。このアプローチは、回答の内容に左右されずに「何が求められているか」をまず定義するため、スタイルバイアスの抑制に極めて有効である。 学習データの構築においては、量よりも質を徹底的に追求する戦略を採用した。一般に公開されている大規模な優先順位データセット「Skywork-Reward-Preference-80K-v0.…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related