MobileBench-OL: 実世界のモバイル環境におけるGUIエージェントのための包括的中国語ベンチマーク
実世界のモバイル環境でGUIエージェントを評価するため、80種類の中国語アプリから1080個のタスクを収録したオンラインベンチマーク「MobileBench-OL」が開発されました。 従来の評価手法が単純な指示への追従に偏っていたのに対し、本手法は20ステップ以上の長期推論、アイコン理解や隠れた機能の探索、さらにポップアップや遅延といった実環境特有のノイズへの耐性を多角的に測定します。 自動評価フレームワークとデバイス状態を復元するリセットメカニズムを導入して12種類の主要エージェントを評価した結果、実世界の要求を満たすには依然として大きな改善の余地があることが明らかになりました。
TL;DR(結論)
実世界のモバイル環境でGUIエージェントを評価するため、80種類の中国語アプリから1080個のタスクを収録したオンラインベンチマーク「MobileBench-OL」が開発されました。 従来の評価手法が単純な指示への追従に偏っていたのに対し、本手法は20ステップ以上の長期推論、アイコン理解や隠れた機能の探索、さらにポップアップや遅延といった実環境特有のノイズへの耐性を多角的に測定します。 自動評価フレームワークとデバイス状態を復元するリセットメカニズムを導入して12種類の主要エージェントを評価した結果、実世界の要求を満たすには依然として大きな改善の余地があることが明らかになりました。
なぜこの問題か
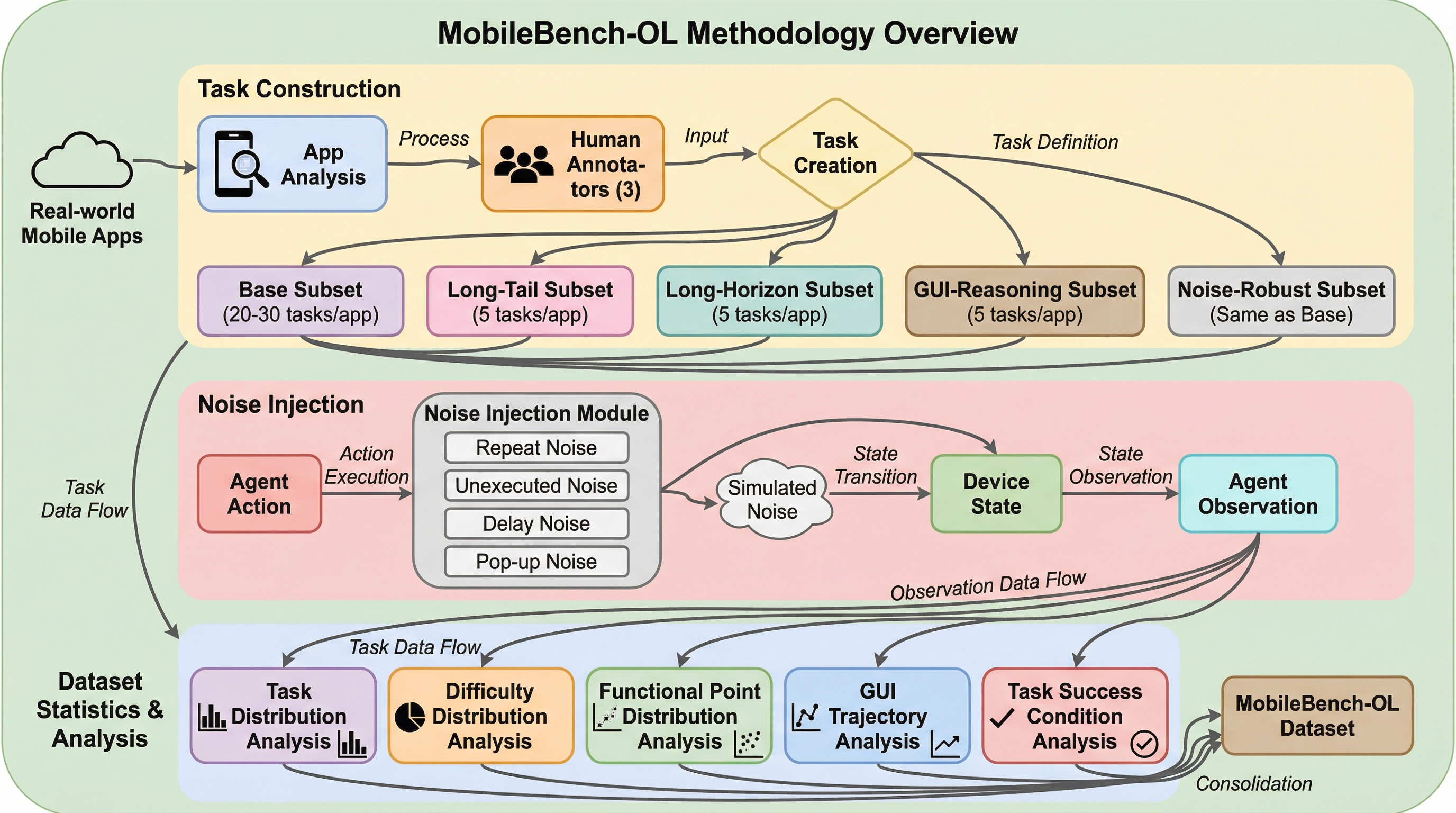
モバイルGUIエージェントの研究が急速に進展する中で、その性能を公平かつ正確に評価するためのベンチマークの重要性がかつてないほど高まっています。しかし、これまでの評価手法にはいくつかの重大な限界が存在していました。まず、従来のオフラインベンチマークは静的なスクリーンショットに基づいているため、実際のデバイス上で発生する動的な変化を捉えることができません。実環境では、一つのタスクに対して複数の有効な操作手順が存在することが一般的ですが、オフラインの手法ではあらかじめ定義された標準的な軌跡との一致のみを評価するため、柔軟な対応力を測定できないという課題がありました。 また、既存のオンラインベンチマークの多くは、非常に単純なアトミックタスクや、一歩ずつの厳格な指示に従う能力の評価に重点を置いています。これでは、エージェントが複雑な目標を自律的に分解し、未知のインターフェースを探索しながら推論する能力を十分に評価できません。…
核心:何を提案したのか
本研究では、これらの課題を解決するために、実世界のモバイルGUI環境に特化した包括的な中国語ベンチマーク「MobileBench-OL」を提案しています。このベンチマークの最大の特徴は、80種類の多様な中国語アプリから抽出された合計1080個のタスクを通じて、エージェントの能力を「基本能力」「複雑な推論」「堅牢性」という3つの核心的な次元から評価する点にあります。評価の客観性を担保するため、タスクは以下の5つのサブセットに戦略的に分類されています。 第一に、一般的な人気アプリでの基本操作を評価する「Base」サブセットと、あまり一般的ではない68種類のアプリでの適応力を試す「Long-Tail」サブセットです。これにより、エージェントが既知のパターンに頼るだけでなく、未知のUIに対しても汎用的なスキルを適用できるかを測定します。第二に、20ステップ以上の連続した操作を要求する「Long-Horizon」サブセットです。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related