TABED: LVLMにおける堅牢な推測デコーディングのためのテスト時適応アンサンブルドラフト
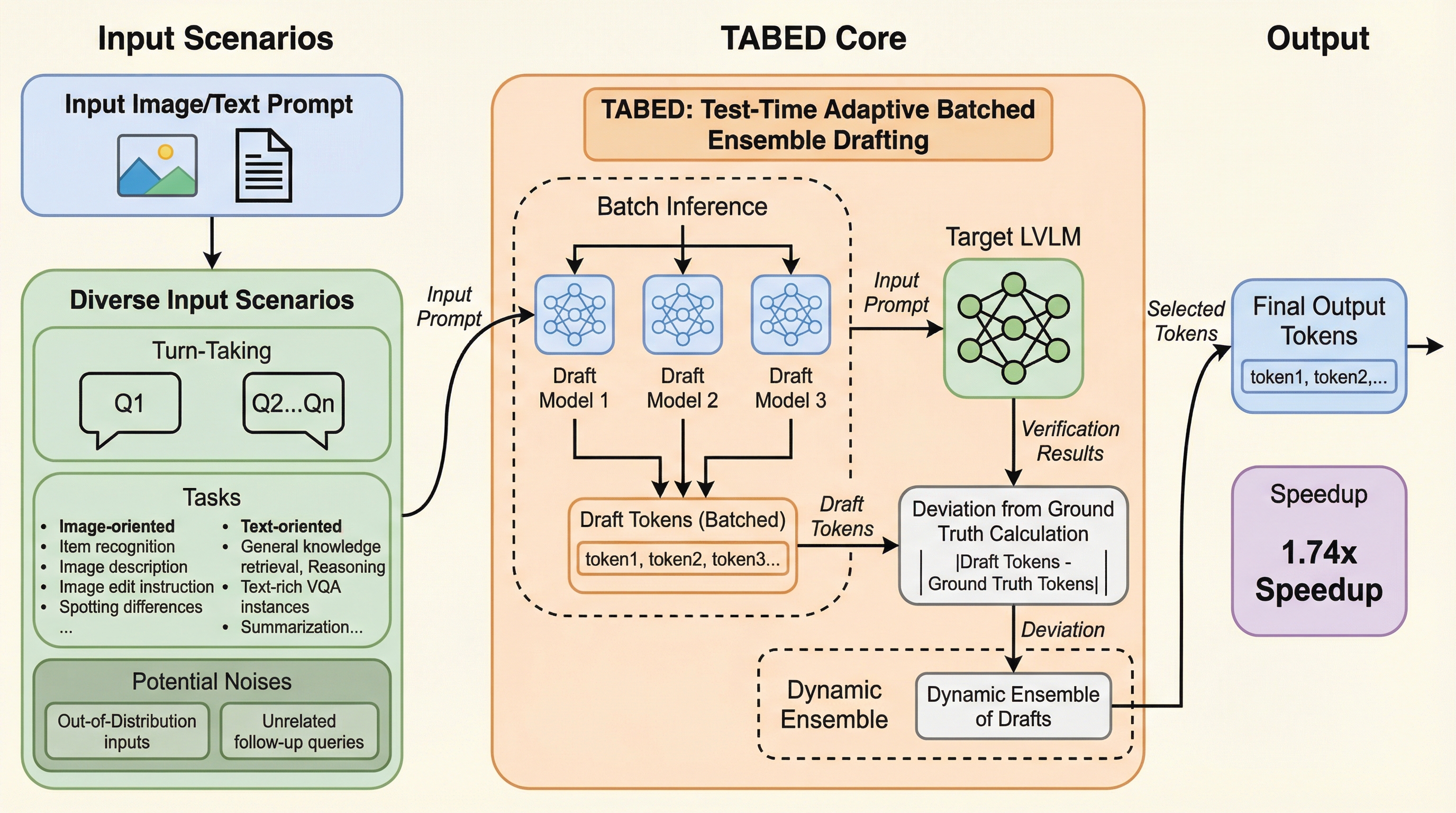
大規模視覚言語モデル(LVLM)の推論を大幅に加速させるため、複数のドラフトモデルをテスト時に動的に統合する新手法「TABED」が提案されました。従来の推測デコーディングでは、視覚情報の有無によって加速性能が不安定になる課題がありましたが、本手法は過去の検証結果から最適な重みを適応的に決定することで、多様なシナリオで一貫した高速化を実現します。追加の学習を一切必要としないプラグアンドプレイな設計でありながら、平均で1.74倍の速度向上を達成し、既存の単一ドラフト手法を5%以上上回る堅牢な性能を幅広いベンチマークで示しました。
TL;DR(結論)
大規模視覚言語モデル(LVLM)の推論を大幅に加速させるため、複数のドラフトモデルをテスト時に動的に統合する新手法「TABED」が提案されました。従来の推測デコーディングでは、視覚情報の有無によって加速性能が不安定になる課題がありましたが、本手法は過去の検証結果から最適な重みを適応的に決定することで、多様なシナリオで一貫した高速化を実現します。追加の学習を一切必要としないプラグアンドプレイな設計でありながら、平均で1.74倍の速度向上を達成し、既存の単一ドラフト手法を5%以上上回る堅牢な性能を幅広いベンチマークで示しました。
なぜこの問題か
大規模視覚言語モデル(LVLM)は、画像とテキストの両方を高度に処理できる能力を持ち、チャットボットや視覚的質問応答など多岐にわたる分野で活用されています。しかし、その推論プロセスには膨大な計算コストがかかり、実行速度の遅延が実用化における大きな障壁となっています。LVLMの推論では、まず入力された画像を数百もの視覚トークンに変換するプリフィリング段階があり、その後に自己回帰的なデコーディング段階が続きます。このデコーディング段階は、トークンを一つずつ順番に生成するため、モデルの規模が大きくなるほど処理時間が飛躍的に増大します。 これまで、この遅延を解消するためにトークンの削減やレイヤーの省略、キー・バリュー(KV)キャッシュの圧縮といった近似的な手法が提案されてきました。これらの手法は計算負荷を軽減する上では一定の効果がありますが、モデル本来の出力分布を完全に維持することができず、回答の質が低下するリスクを孕んでいます。また、これらの多くは入力処理の効率化に特化しており、実際の生成プロセスであるデコーディング段階の加速効果は限定的でした。…
核心:何を提案したのか
本論文では、テスト時に適応的なアンサンブルを行うことで、LVLMの推論を堅牢かつ効率的に加速させる新手法「TABED(Test-time Adaptive Batched Ensemble Drafting)」を提案しています。この手法の核心は、複数の異なる特性を持つドラフト手法をバッチ推論によって同時に実行し、それぞれの予測結果を過去のパフォーマンスに基づいてリアルタイムで統合する点にあります。これにより、特定のタスクやデータの性質に左右されることなく、常に最適なドラフト戦略を維持することが可能になりました。 TABEDの大きな利点の一つは、事前の追加学習やパラメータの微調整を一切必要としない「トレーニングフリー」な設計であることです。従来の高性能な推測デコーディング手法の多くは、ドラフトモデルをターゲットモデルの出力に合わせるための蒸留や微調整が必要であり、新しいモデルを導入するたびに再学習の手間が発生していました。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related