SpeechMapper: LLMのための音声からテキストへの埋め込みプロジェクター
SpeechMapperは、音声基礎モデルの出力を大規模言語モデル(LLM)の埋め込み空間へ直接写像する、計算コスト効率に優れた2段階の学習手法を提案しており、従来の膨大な計算資源とデータを必要とする音声・LLM統合手法が抱えていた高コストかつ過学習しやすいという深刻な課題を解決する画期的なアプローチである。
TL;DR(結論)
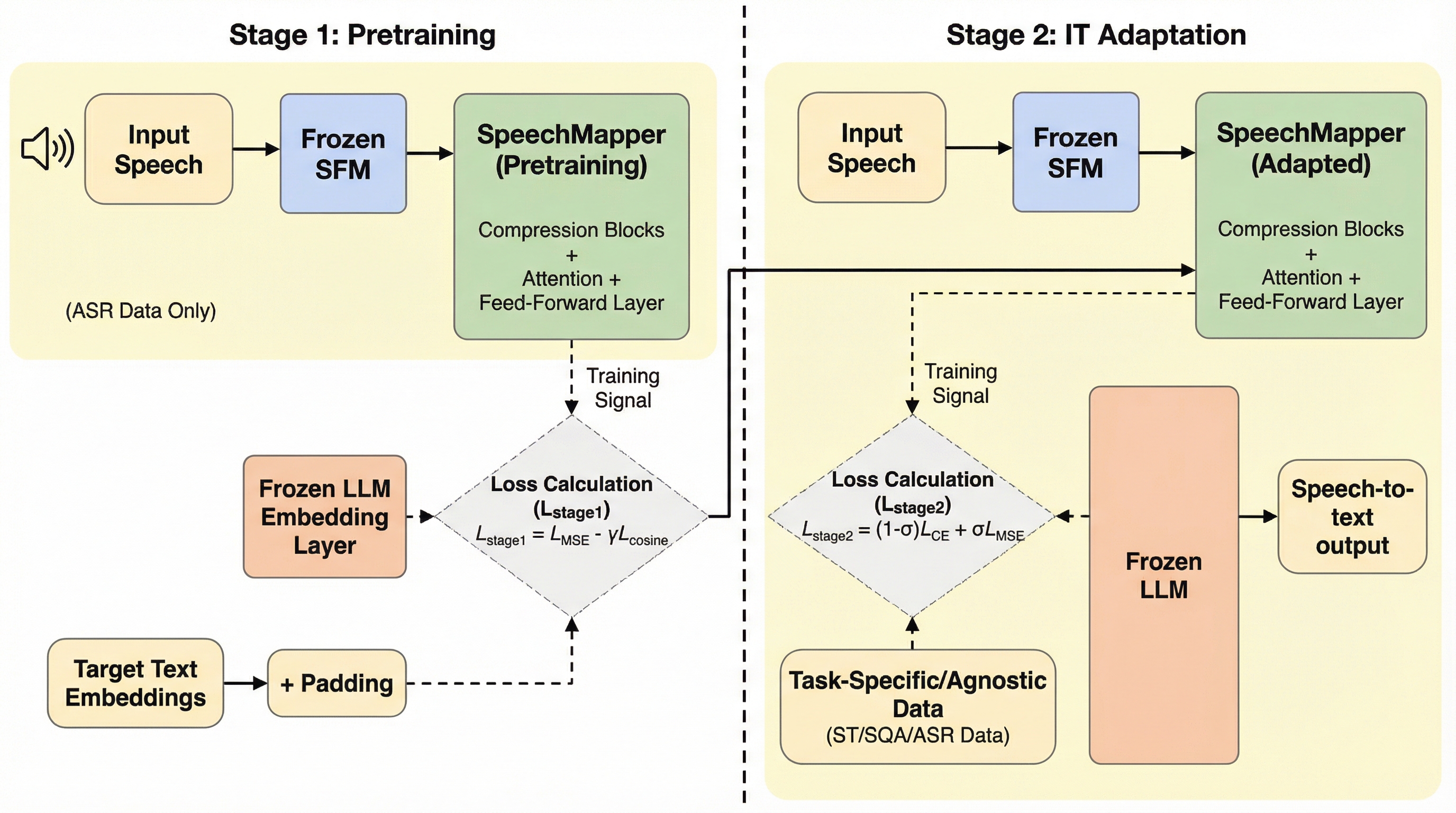
SpeechMapperは、音声基礎モデルの出力を大規模言語モデル(LLM)の埋め込み空間へ直接写像する、計算コスト効率に優れた2段階の学習手法を提案しており、従来の膨大な計算資源とデータを必要とする音声・LLM統合手法が抱えていた高コストかつ過学習しやすいという深刻な課題を解決する画期的なアプローチである。 第1段階でLLMの順伝播計算を完全に排除し、凍結された埋め込み層のみを利用する事前学習を行い、第2段階でわずか1000ステップ(約1.5時間)という極めて短い指示調整を実施することで、未知のタスクやプロンプトに対する過学習を効果的に抑制しながら、多様な音声タスクに適応可能な高い汎用性と頑健性を実現している。 音声翻訳や音声質疑応答の広範な実験において、IWSLT2025の優勝モデルを含む既存の最高水準の専門モデルと同等以上の性能を示しており、特にタスク特化型の設定では、従来手法よりも大幅に少ないデータ量と計算資源でありながら優れた成果を達成し、実用的かつスケーラブルな音声・LLM統合の新たな標準を提示した。
なぜこの問題か
現在の大規模言語モデル(LLM)を音声認識や音声翻訳などの音声タスクに拡張しようとする試みは、主に音声基礎モデル(SFM)とLLMをプロジェクション層で接続し、それらすべてのコンポーネントを音声指示データで学習させる戦略をとっている。しかし、この戦略は計算資源を極めて大量に消費するだけでなく、特定のタスクやプロンプトに対して過学習を起こしやすいという脆弱性を抱えている。既存の研究では、音声認識(ASR)とLLMをカスケード接続する方法も検討されているが、この手法は音響的な手がかりを破棄してしまい、推論時の遅延も増大させるという欠点がある。また、音声を離散的なトークンに変換してLLMに読み込ませる手法も存在するが、これは処理速度が遅く、量子化の品質に敏感であるという課題が指摘されている。 さらに、SFMのエンコーダー出力とLLMを直接統合する複雑なシステムでは、複数のタスクにわたって大規模な指示調整(IT)が必要となり、高性能なGPUや膨大な音声データセットが不可欠となる。このような背景から、計算コストを大幅に抑えつつ、未知のタスクに対しても頑健で汎用性の高い音声・LLM統合手法の確立が急務となっている。…
核心:何を提案したのか
本研究では、過学習を軽減し、より頑健で汎用的なモデル構築を可能にするコスト効率の高い音声・LLM埋め込み学習アプローチとして「SpeechMapper」を提案した。SpeechMapperの最大の特徴は、LLM本体の重みを凍結したまま、SFMの出力をターゲットとなるLLMの埋め込み空間に直接写像するプロジェクターを学習する点にある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related