PEARL: マルチホップツール使用のための計画探索と適応型強化学習
PEARLは、大規模言語モデルが複雑な多段階のツール呼び出しにおいて直面する、計画能力の欠如やツールの幻覚、誤ったパラメータ生成といった深刻な課題を解決するために開発された新しいフレームワークである。
TL;DR(結論)
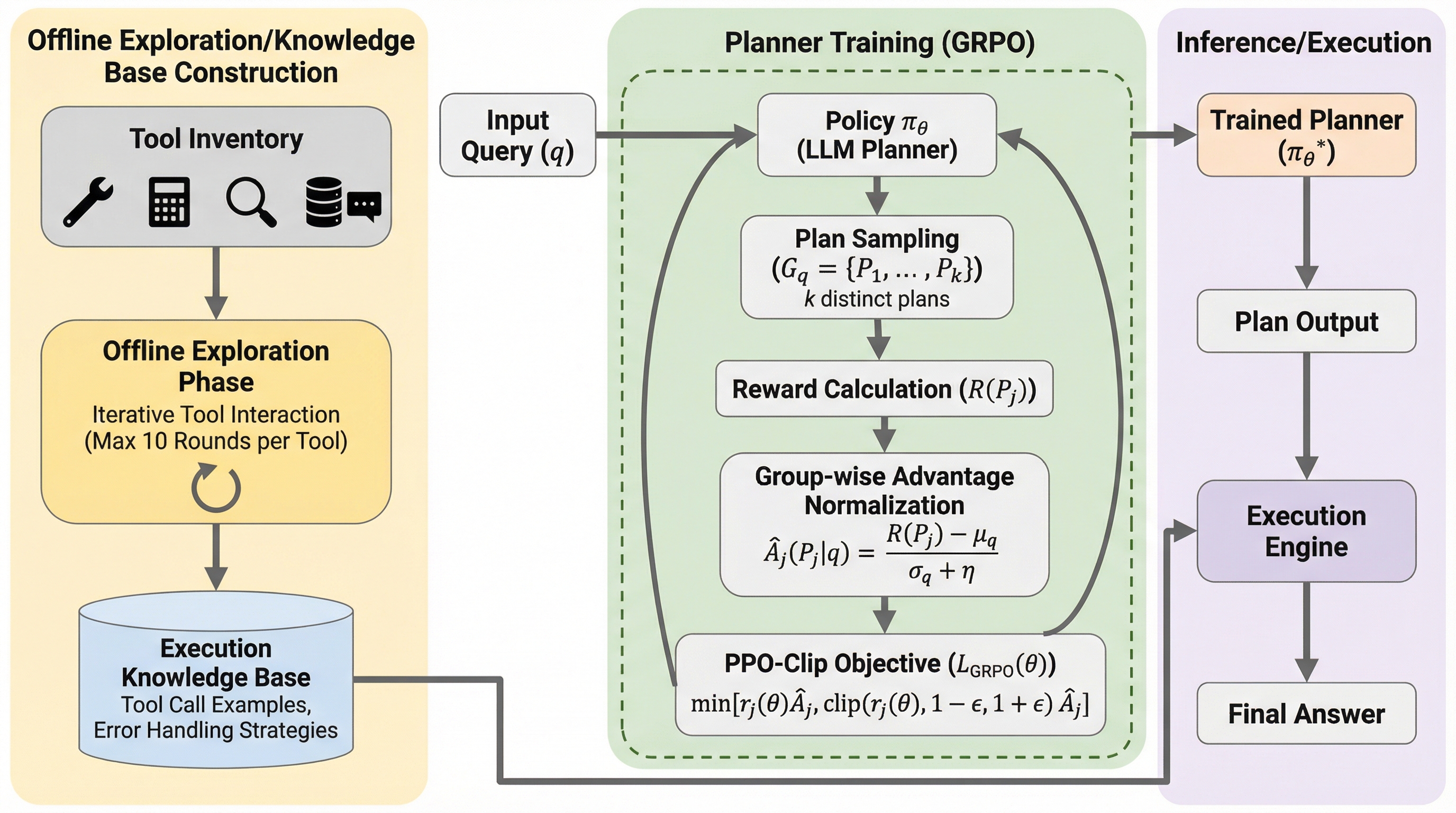
PEARLは、大規模言語モデルが複雑な多段階のツール呼び出しにおいて直面する、計画能力の欠如やツールの幻覚、誤ったパラメータ生成といった深刻な課題を解決するために開発された新しいフレームワークである。本手法は、オフラインでツールを試行錯誤して使用パターンや失敗条件を事前に学習する段階と、グループ相対方策最適化(GRPO)と独自の計画中心の報酬関数を用いて戦略的な計画立案を訓練するオンライン強化学習段階の二段階で構成される。実験の結果、ToolHopベンチマークにおいて56.5%という過去最高の成功率を達成し、既存のオープンソースモデルや商用モデルを凌駕しただけでなく、低い呼び出しエラー率を維持しながら未知のタスクに対しても優れた汎用性と信頼性を示した。
なぜこの問題か
大規模言語モデルは自然言語の理解と生成において顕著な能力を示しているが、その知識は静的であり、訓練データに限定されているため、現実世界との相互作用や最新情報へのアクセス、複雑な計算の実行には限界がある。この制限を克服するために外部ツールを導入するツール学習が登場したが、初期の成功は単純な単一ステップのAPI呼び出しに留まっていた。現在の課題は、複数のツールを戦略的に順序立てて使用する必要がある複雑な多段階の問題解決へと移行している。しかし、この複雑性の飛躍により、エージェントの長期的な計画立案と堅牢な実行能力における重大なボトルネックが露呈している。 既存のアプローチの多くは、一歩先しか見ない近視眼的な戦略を採用しており、長期的な計画を策定したり遵守したりすることが困難である。このような先見性の欠如は、存在しないツールを捏造するツールの幻覚や、誤ったパラメータの生成、連続するツール呼び出し間の依存関係の管理失敗といった、脆弱で信頼性の低い実行につながる。さらに、実行エラーに直面した際の適応能力も乏しく、失敗を診断して計画を反映させ、戦略を動的に調整することができず、同じ失敗を繰り返すループに陥ることが多い。…
核心:何を提案したのか
本研究では、戦略的な計画立案と信頼性の高い実行という相互に関連する課題を解決するために、PEARL(Plan Exploration and Adaptive Reinforcement Learning)と呼ばれる新しいフレームワークを提案した。PEARLは、オフラインでのツール探索と適応型強化学習を統合した二段階のアプローチを採用している。第一段階では、強化学習によって最適化された専用のプランナーが、実行を開始する前に完全で高度な計画を生成することを学習する。この訓練の核となるのは、計画の質に対して直接的かつ密なフィードバックを提供する、革新的な計画中心の報酬関数である。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related