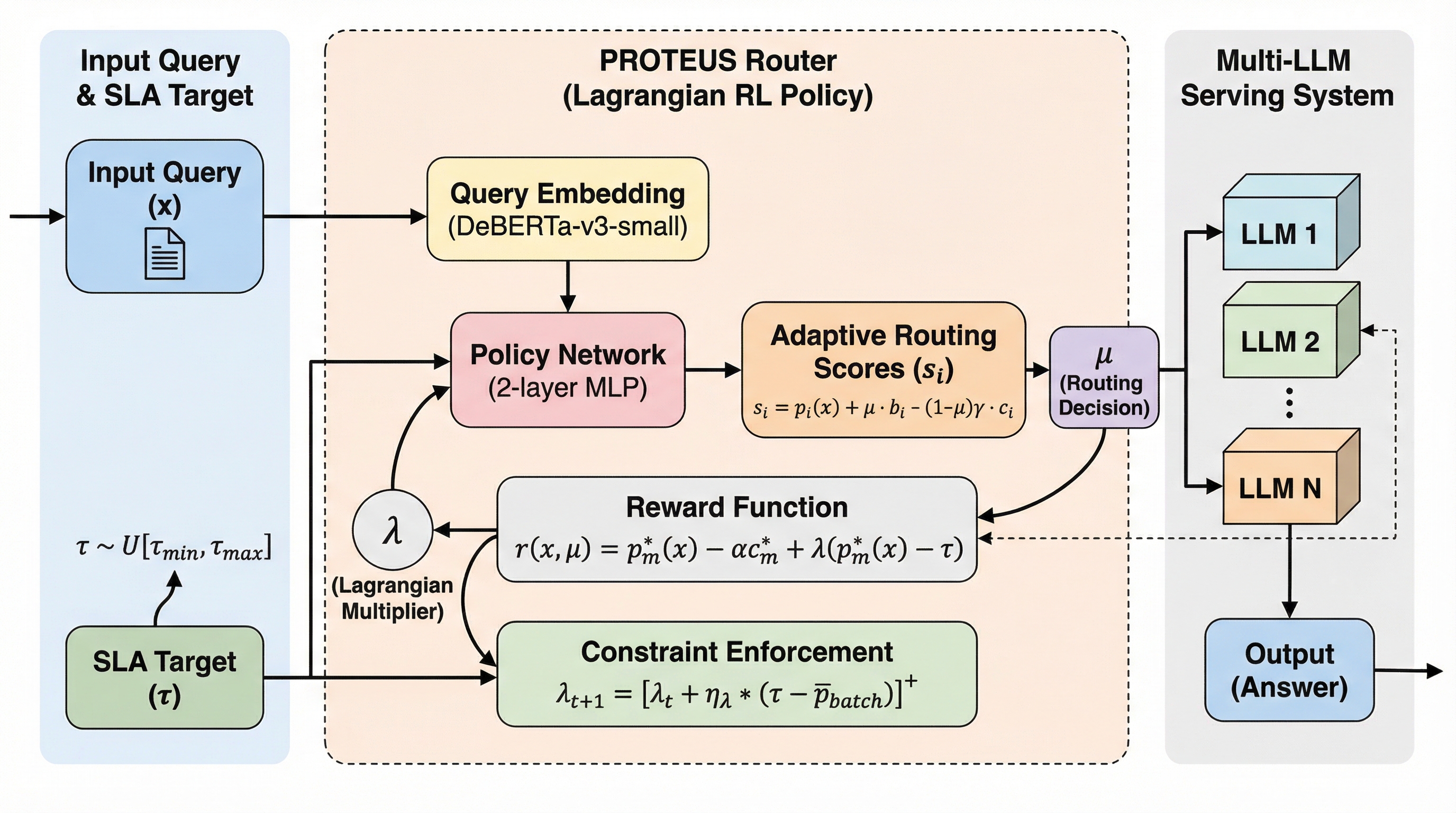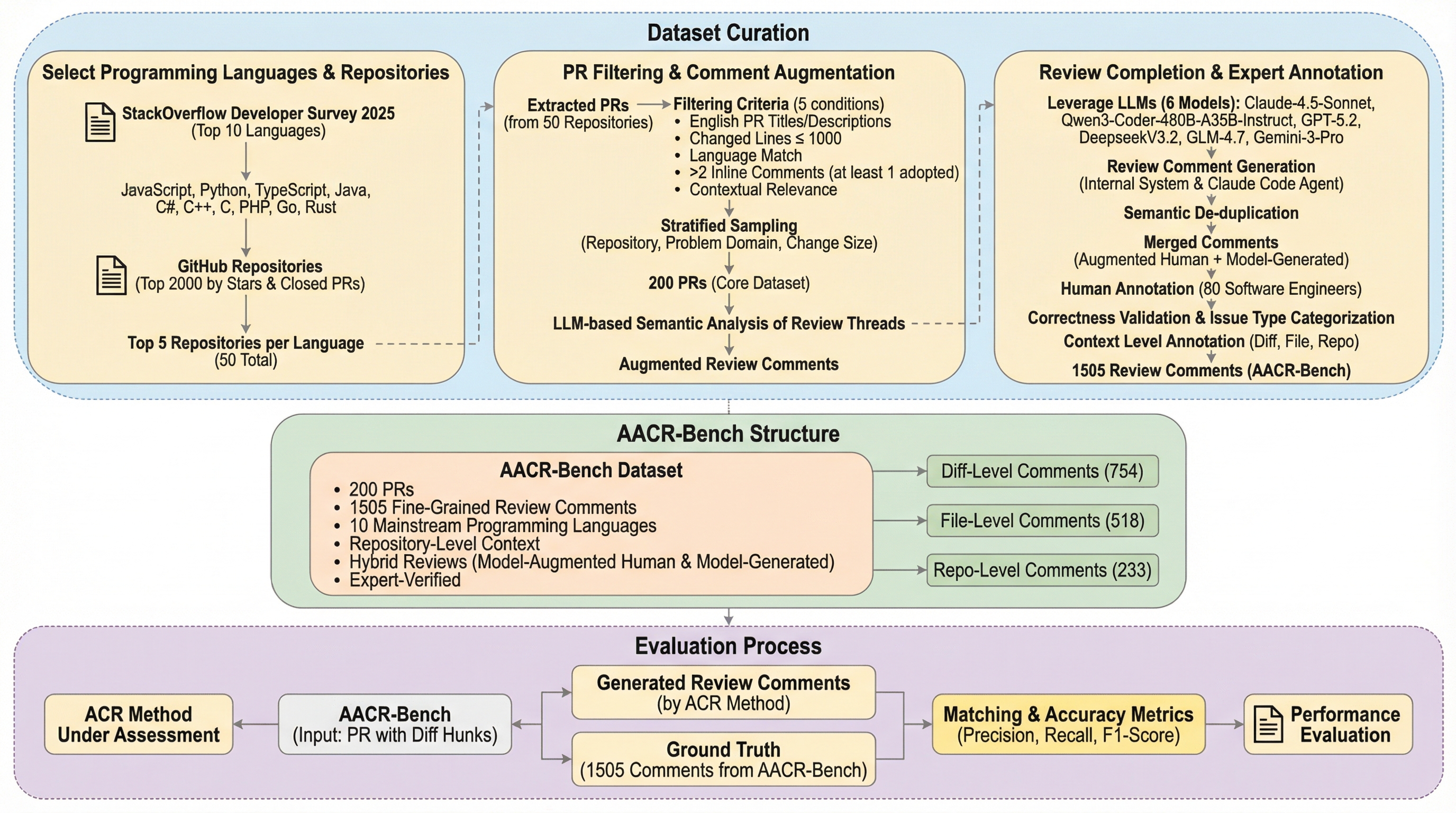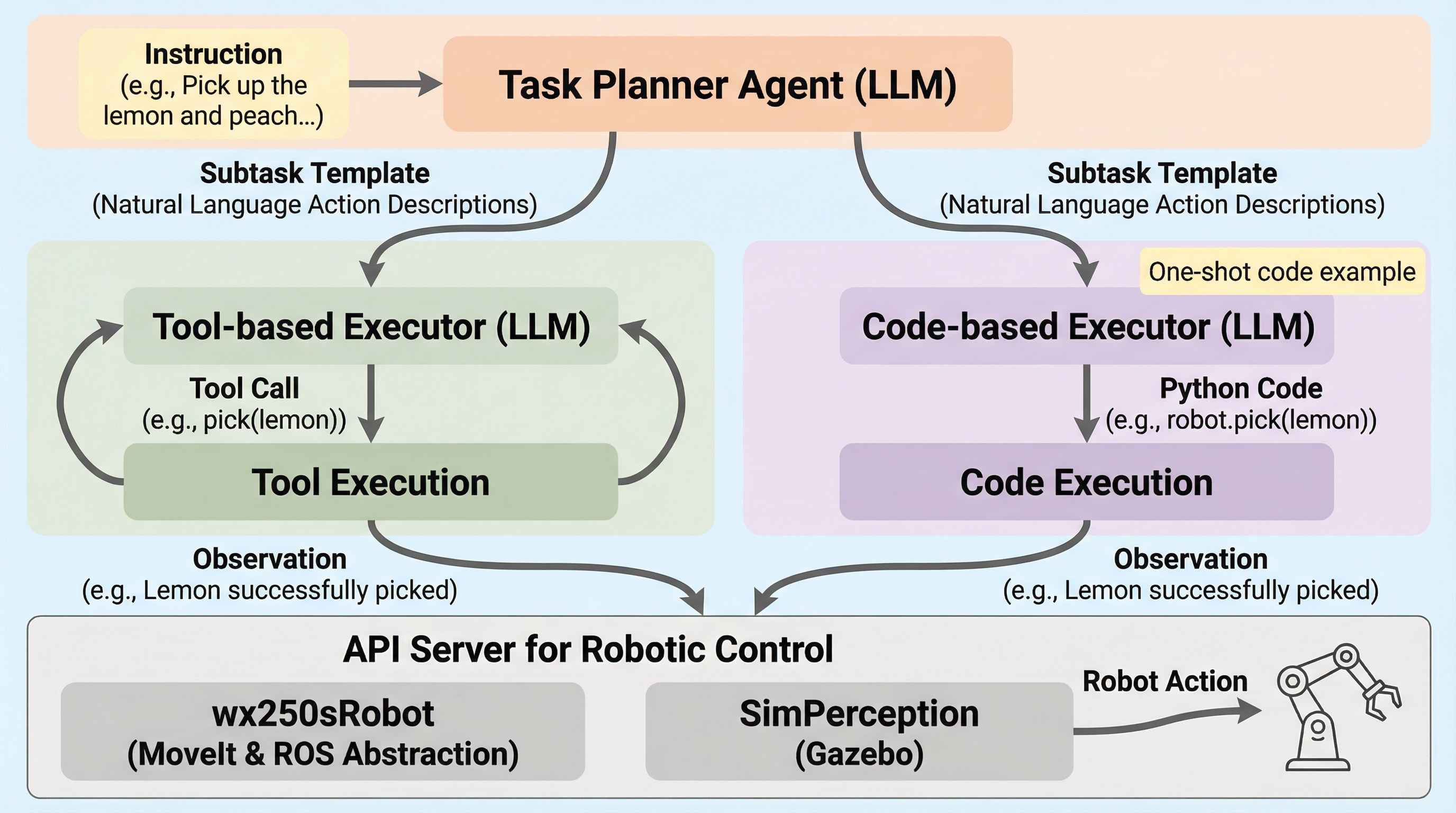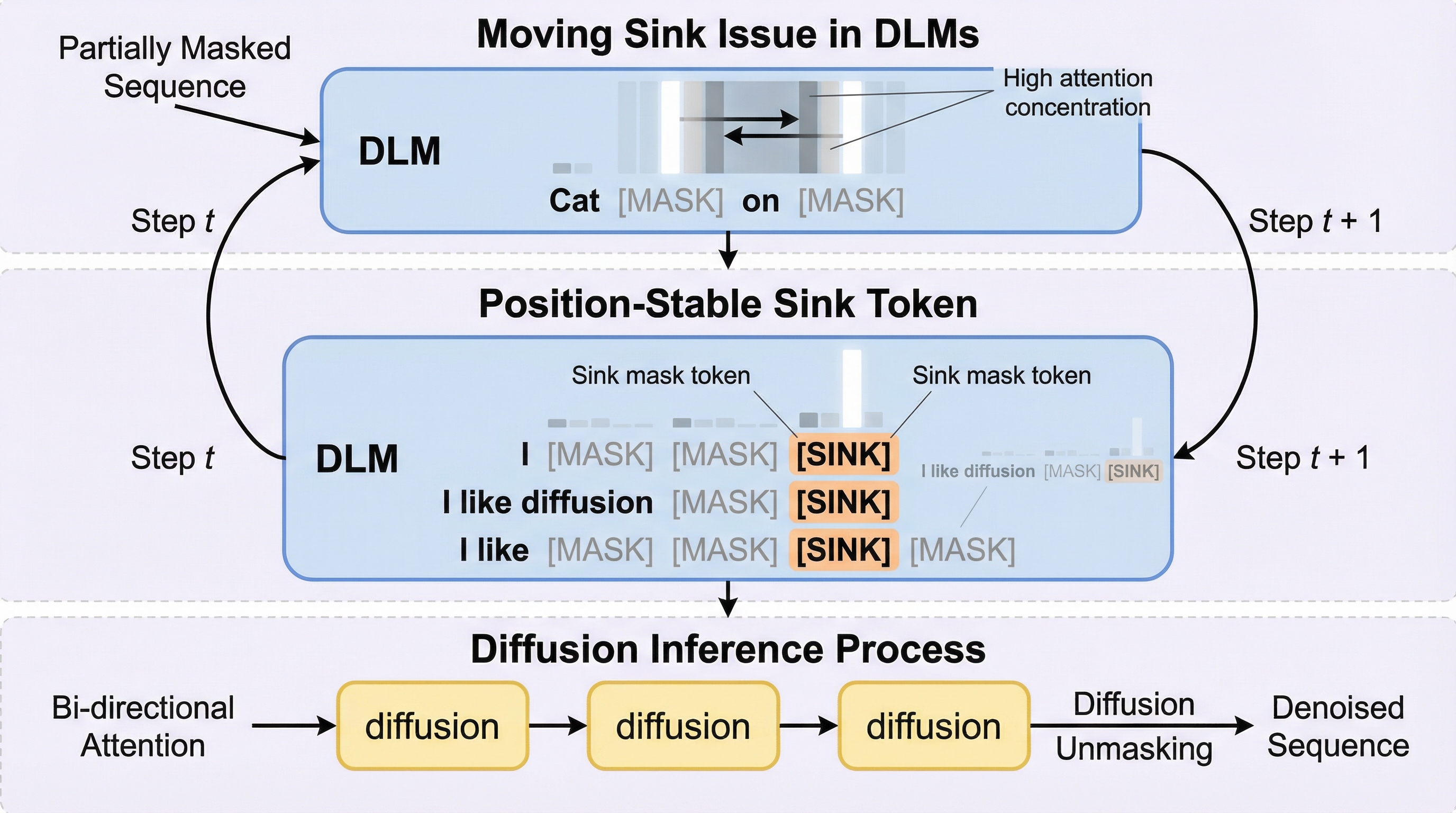
TinyTorch:第一原理からの機械学習システムの構築
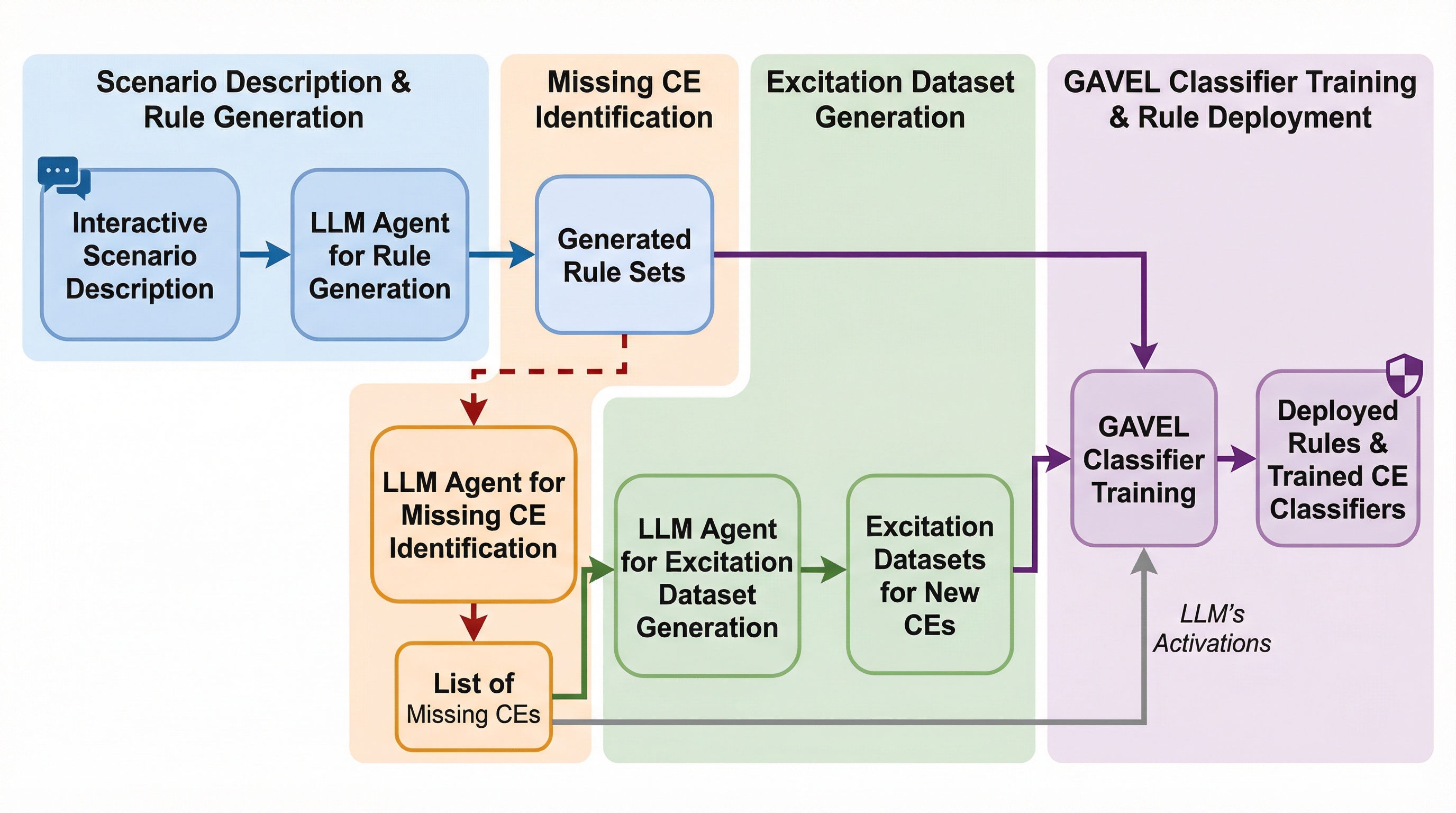
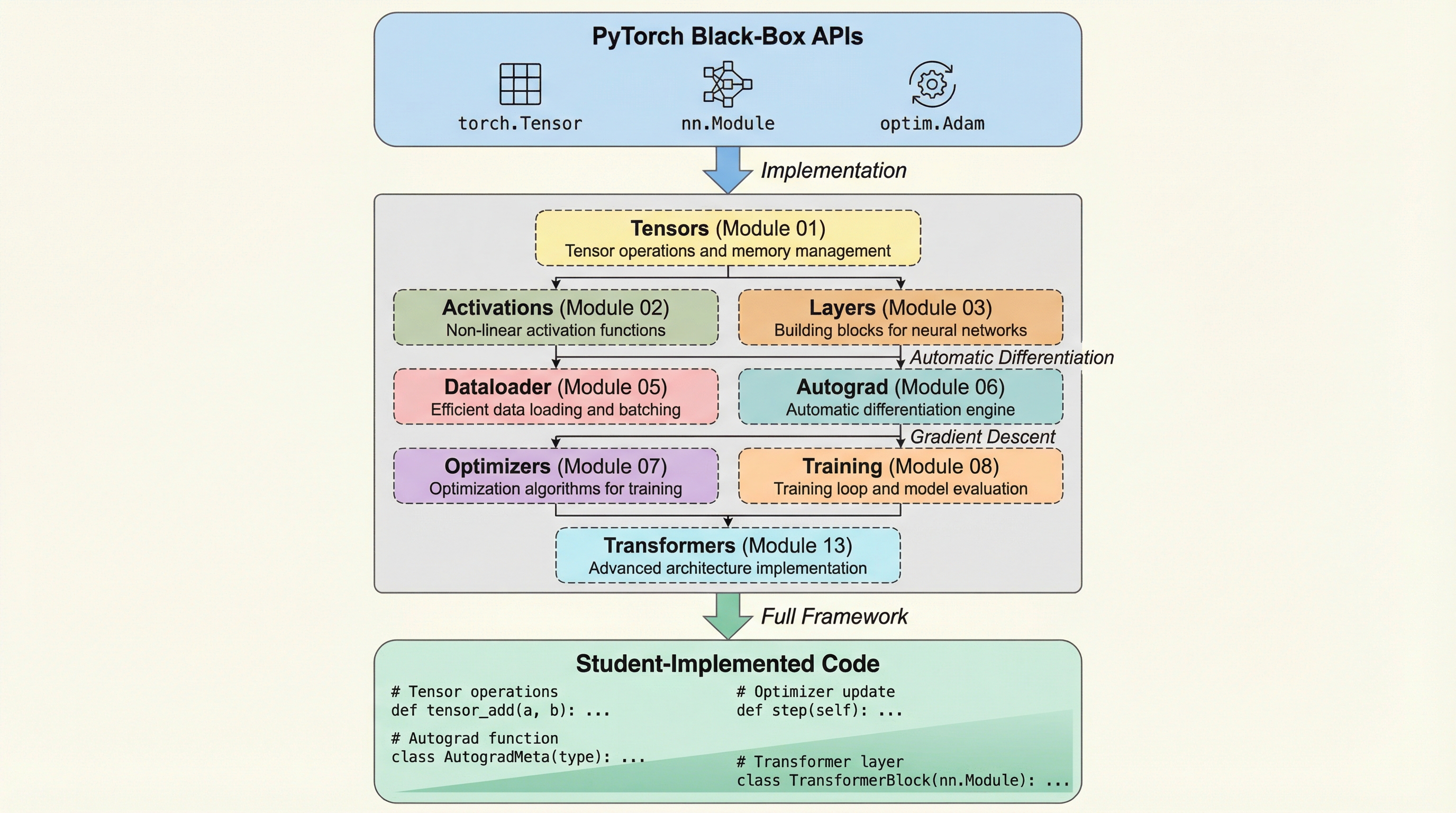
機械学習教育におけるアルゴリズム理論とシステム実行の深刻な乖離を解消するため、20のモジュールで構成される教育カリキュラム「TinyTorch」が提案されました。学生は純粋なPythonのみを用いて、テンソル演算、自動微分、オプティマイザ、トランスフォーマーといったPyTorch互換のコンポーネントをゼロから構築し、全ての操作が自作コードで完結する透明性の高いフレームワークを完成させます。この「構築による検証」アプローチにより、4GBのRAMという最小限のハードウェア環境で、メモリ効率や計算の複雑性、デプロイ時のトレードオフを深く理解する、産業界が求める機械学習システムエンジニアの育成を目指しています。