RobustExplain:推薦のためのLLMベースの説明エージェントの堅牢性評価
推薦システムにおいてLLMを用いた説明エージェントは、ユーザーの行動履歴から自然言語で推薦理由を生成するが、誤クリックやデータの欠落といった現実的なノイズに対する堅牢性はこれまで十分に検証されていなかった。
TL;DR(結論)
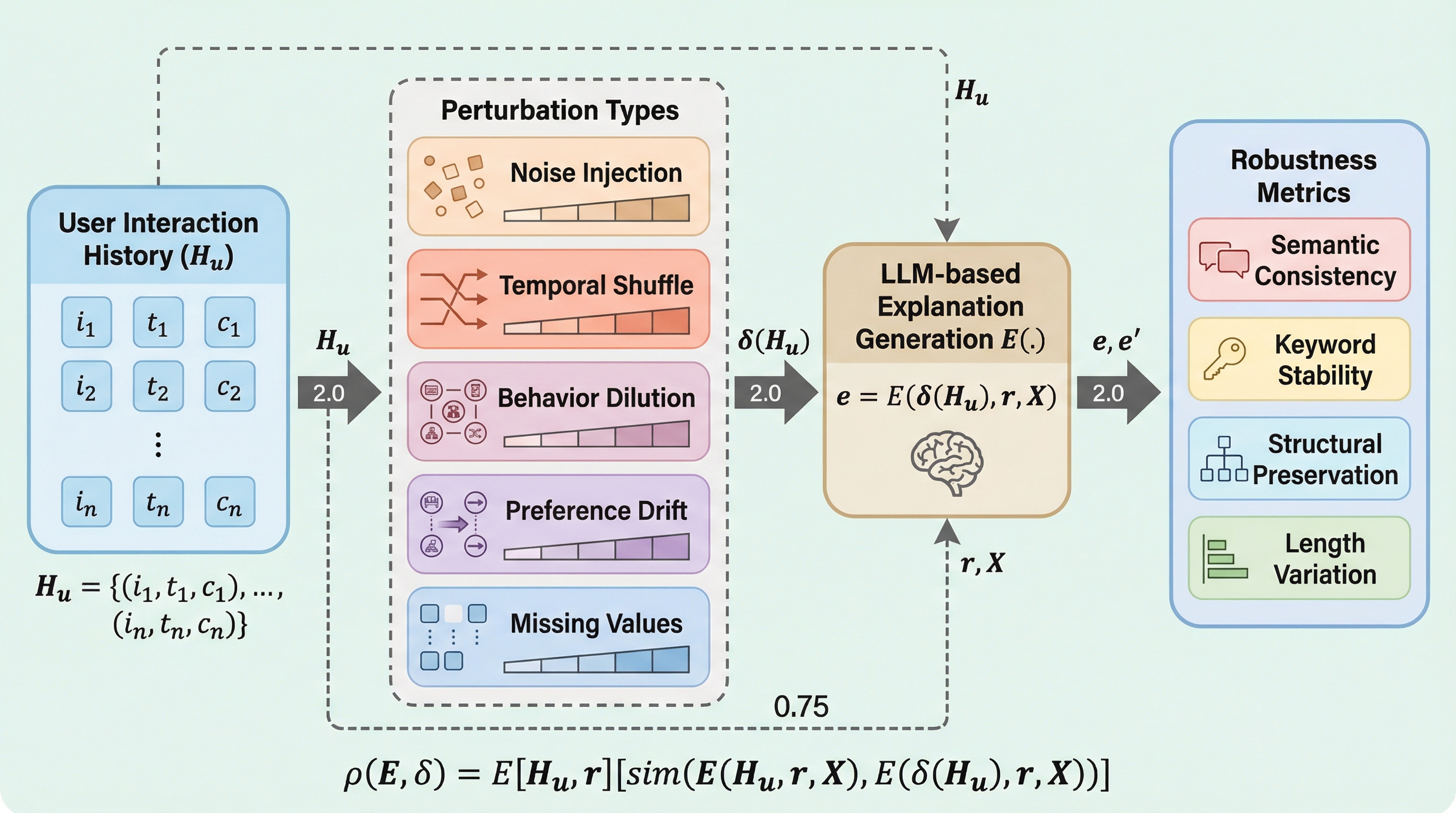
推薦システムにおいてLLMを用いた説明エージェントは、ユーザーの行動履歴から自然言語で推薦理由を生成するが、誤クリックやデータの欠落といった現実的なノイズに対する堅牢性はこれまで十分に検証されていなかった。 本研究では、5種類の現実的な行動摂動と4つの多角的な評価指標を導入した初の体系的な評価フレームワーク「RobustExplain」を提案し、7Bから70Bのパラメータを持つ主要なLLMを用いて、入力の変化が説明の安定性に与える影響を測定した。 実験の結果、現在のLLMは平均スコア約0.50という中程度の堅牢性しか持たず、モデルサイズが大きいほど安定性が向上することや、説明の構造的な一貫性が最も維持しにくい課題であることが明らかになり、信頼性の高いエージェント構築に向けた基準が示された。
なぜこの問題か
現代の推薦システムでは、ユーザーの行動履歴に基づいて推薦の正当性を説明するために、大規模言語モデル(LLM)が説明エージェントとして統合されるケースが急速に増えている。従来の手法であるテンプレートベースや特徴量レベルの説明と比較して、LLMが生成する説明は流暢であり、パーソナライズされた文脈に即した正当化が可能であるため、人間のような対話的な体験を提供できるという大きな利点がある。しかし、現実のウェブプラットフォームにおけるユーザーのインタラクションデータは、本質的に多くのノイズを含んでいるのが実情である。例えば、意図しない誤ったクリック、時間的な記録の不整合、メタデータの欠落、家族などによるアカウントの共有、あるいは時間の経過に伴う好みの変化などが挙げられる。 これまでのLLMベースの推薦説明に関する研究は、主に固定されたクリーンな入力設定の下での説明の流暢さ、関連性、ユーザーの満足度といった「生成の質」に焦点を当ててきた。一方で、現実的なユーザー行動のノイズに対する説明の堅牢性については、ほとんど調査が行われてこなかった。…
核心:何を提案したのか
本研究では、ユーザー行動の摂動下におけるLLM生成の説明の堅牢性を分析するための、初の体系的な評価フレームワーク「RobustExplain」を提案した。このフレームワークは、現実の運用環境で遭遇する可能性が高いノイズシナリオを構造化された摂動の分類法としてモデル化し、ユーザー履歴が制御された方法で変更された際に、説明の内容がどのように変化するかを評価するものである。具体的には、5種類の現実的な摂動タイプを定義し、それぞれに対して5段階の深刻度を設定することで、詳細な堅牢性分析を可能にしている。これにより、軽微なノイズから致命的なデータの欠落まで、幅広いシナリオを網羅している。 さらに、ユーザーの視点から説明の安定性を捉えるために、多次元的な堅牢性指標を導入した。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related