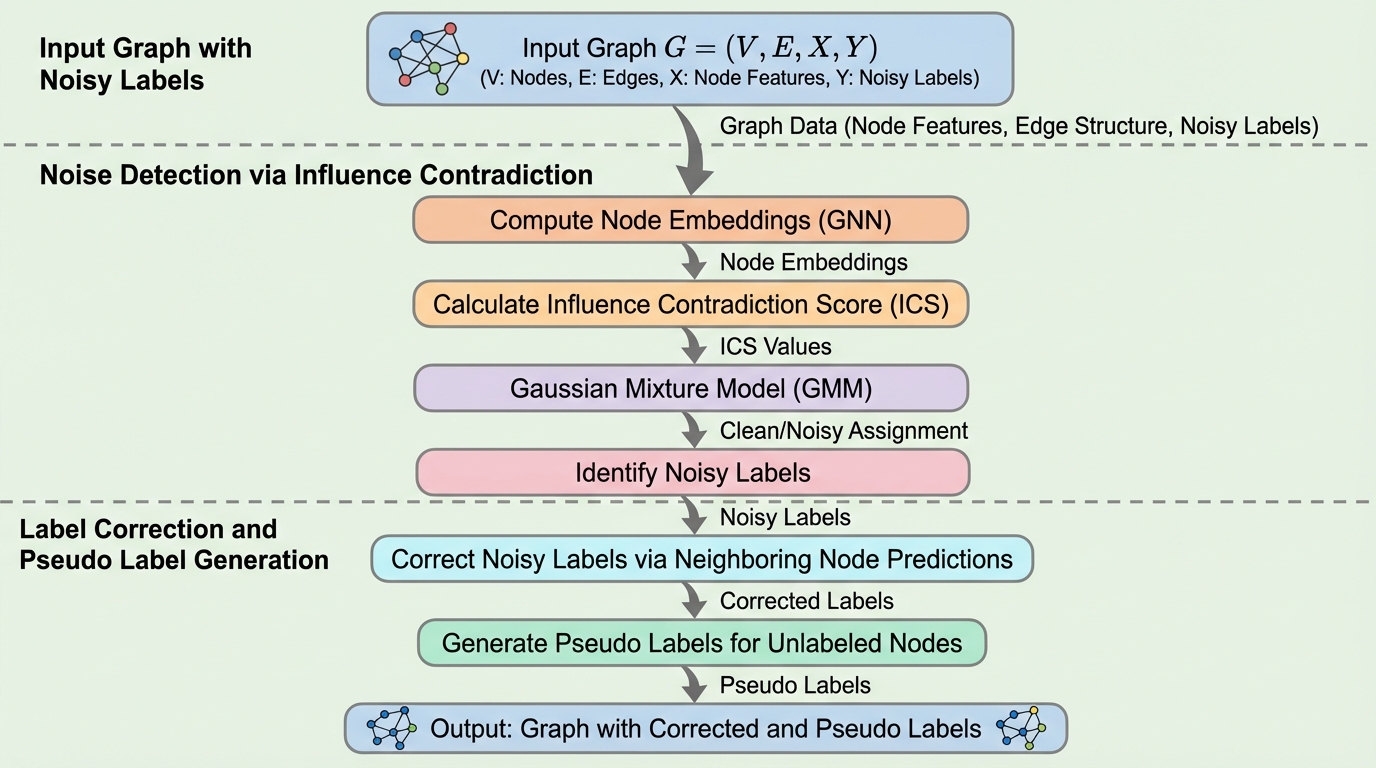
影響の矛盾を用いた頑健なGNNのためのラベルノイズの特定と修正
グラフニューラルネットワーク(GNN)は社会分析や生物情報学などの多様な分野で活用されているが、現実のデータには注釈ミスや不整合に起因するラベルノイズが含まれることが多く、これがモデルの堅牢性と汎用性を著しく低下させるという課題がある。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
グラフニューラルネットワーク(GNN)は社会分析や生物情報学などの多様な分野で活用されているが、現実のデータには注釈ミスや不整合に起因するラベルノイズが含まれることが多く、これがモデルの堅牢性と汎用性を著しく低下させるという課題がある。
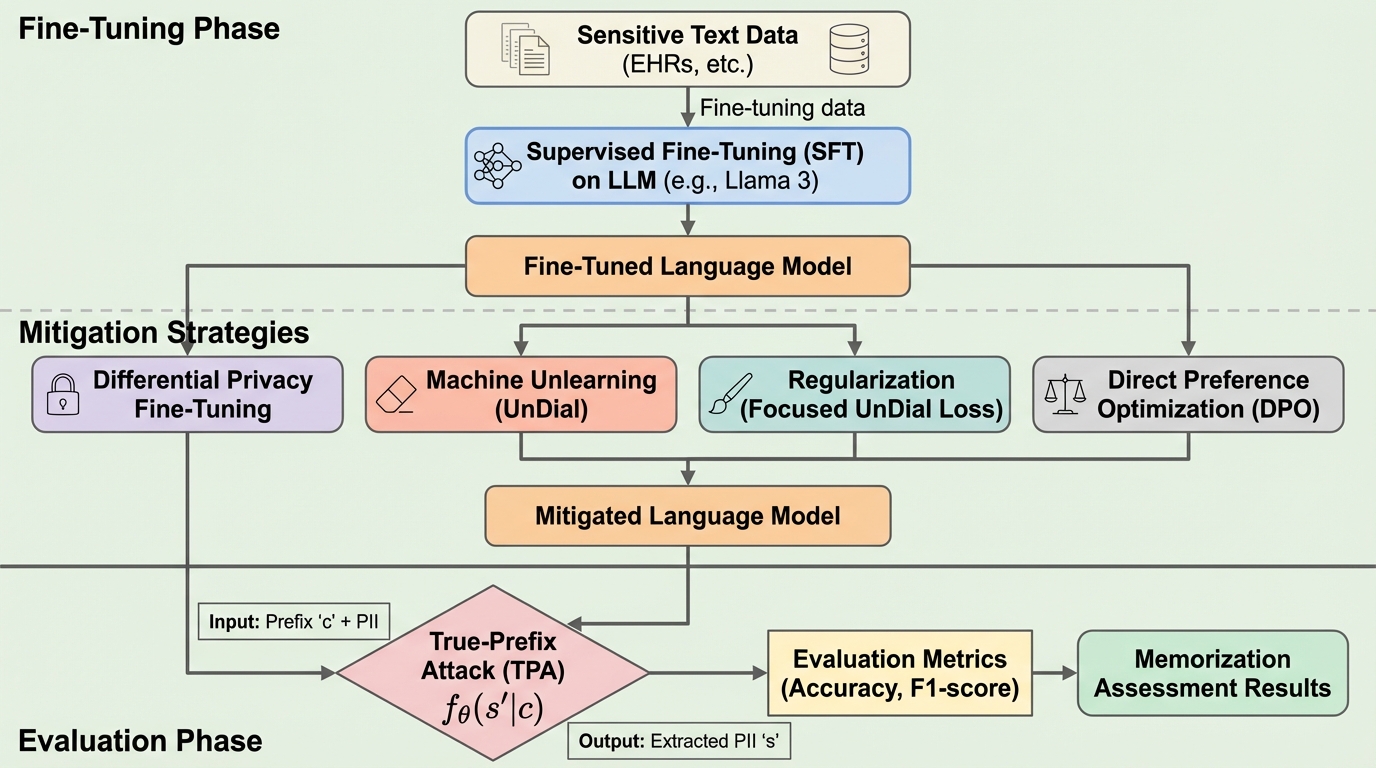
大規模言語モデル(LLM)を特定のデータセットで微調整する際、学習の目的(ターゲット)には含まれず、入力データにのみ存在する個人識別情報(PII)が意図せず記憶され、外部からの攻撃によって抽出可能になるリスクを、合成データと実世界の医療データを用いて体系的に明らかにした。
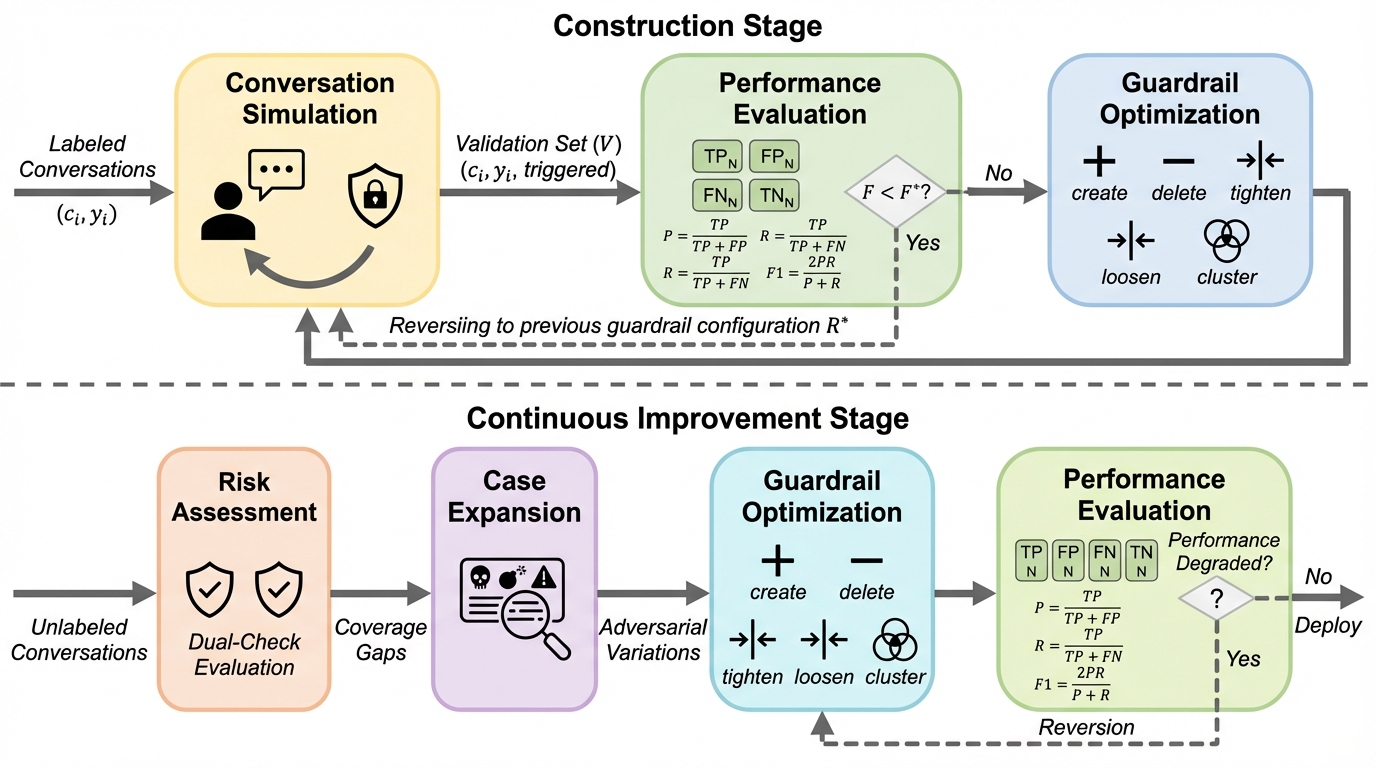
従来の対話型AIにおけるガードレールは、あらかじめ定義された静的なルールに依存しているため、運用中に発生する新しい脅威や多様な展開コンテキストに柔軟に適応できないという深刻な課題を抱えていたが、本研究ではガードレールの自己構築と継続的な自動改善を実現する革新的なフレームワーク「Lattice」を提案した。
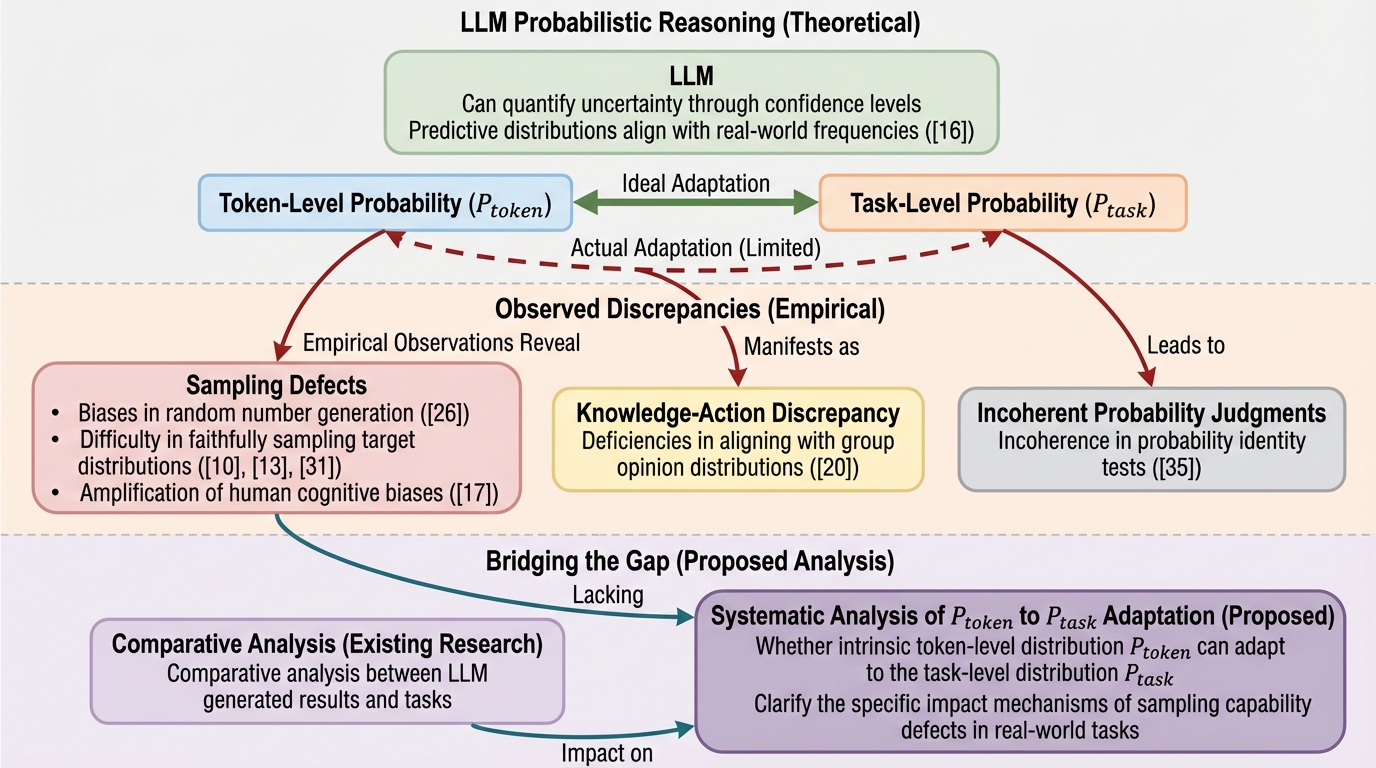
大規模言語モデル(LLM)の次トークン予測確率($P{token}$)とタスク目標分布($P{task}$)の整合性を分析した結果、挙動の異なる2つのモデル群(D-ModelsとE-Models)の存在が明らかになりました。 Qwen-2.5やLlama-3.
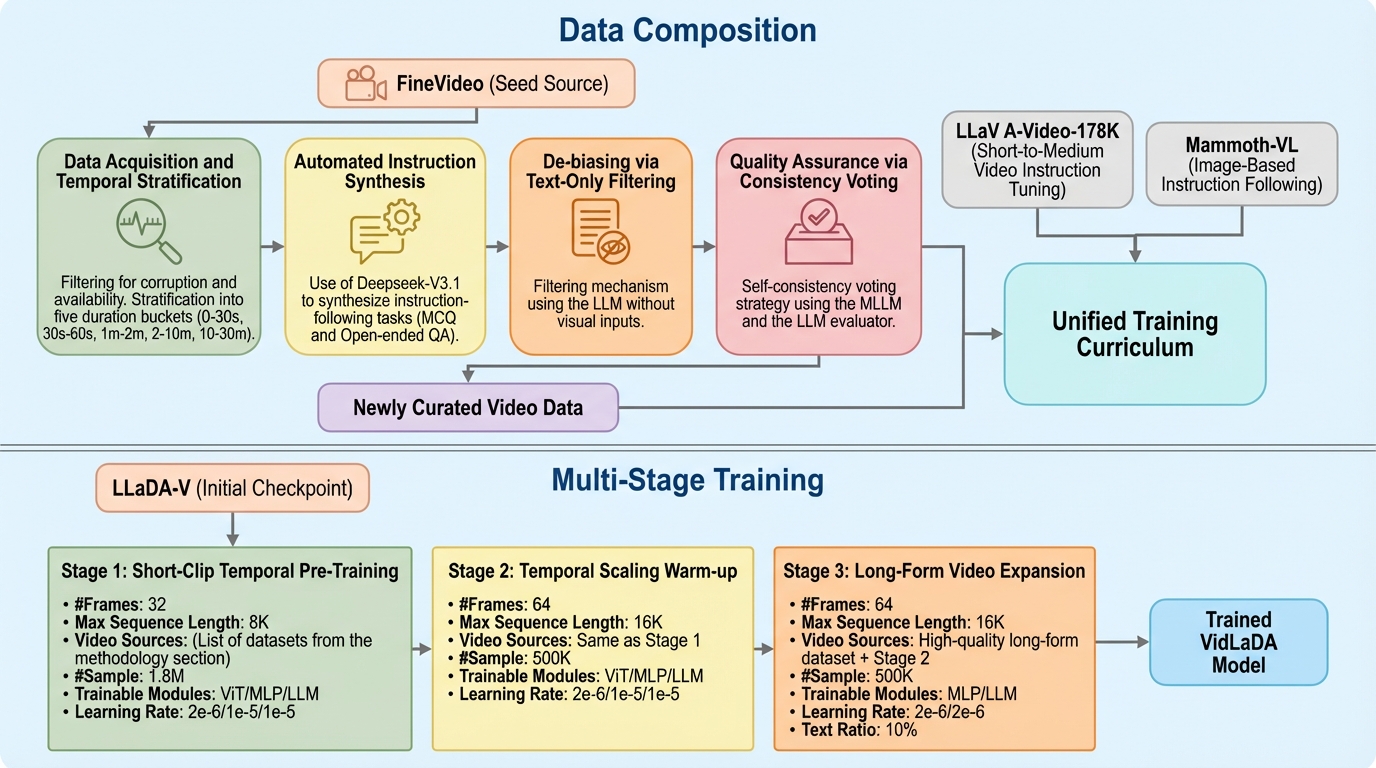
従来のビデオ大規模言語モデルが抱えていた自己回帰型モデル特有の単方向アテンションによる理解の限界と、逐次デコードによる生成速度の遅さを、双方向アテンションを持つ拡散言語モデル(DLM)を採用することで根本から解決した。
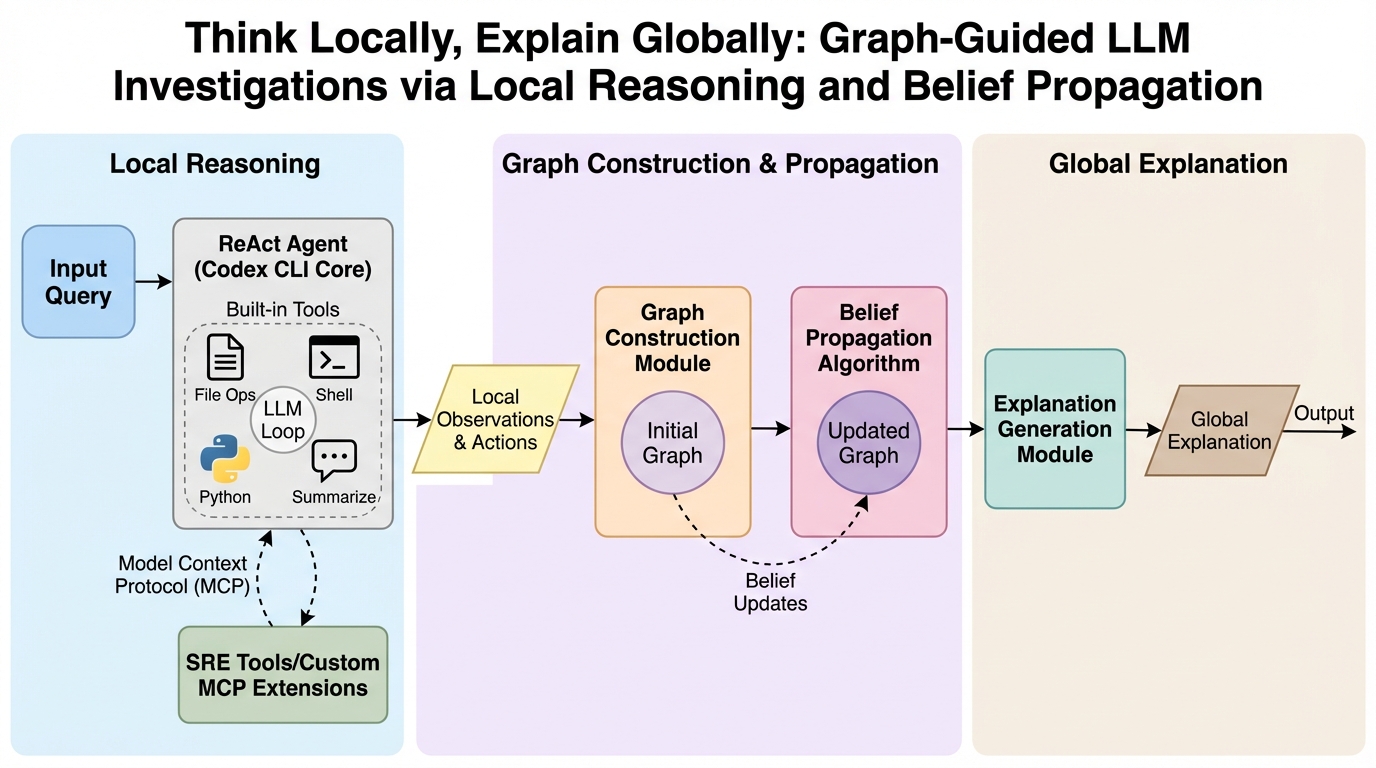
Think Locally, Explain Globally: 局所的推論と信念伝播によるグラフ誘導型LLM調査フレームワーク「EoG」の提案
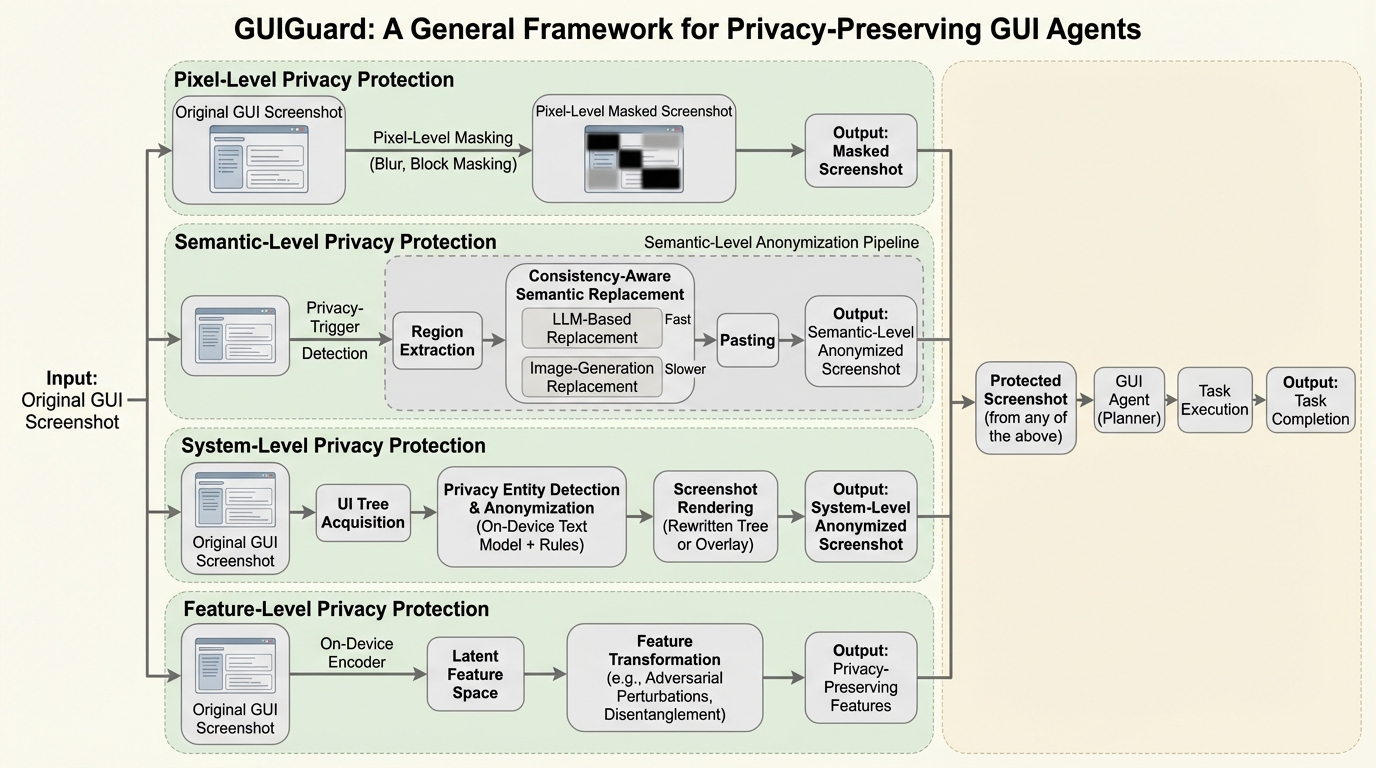
GUIエージェントが画面情報をリモートモデルに送信する際に生じる深刻なプライバシーリスクを解決するため、認識・保護・実行の3段階で構成される汎用フレームワーク「GUIGuard」が提案されました。
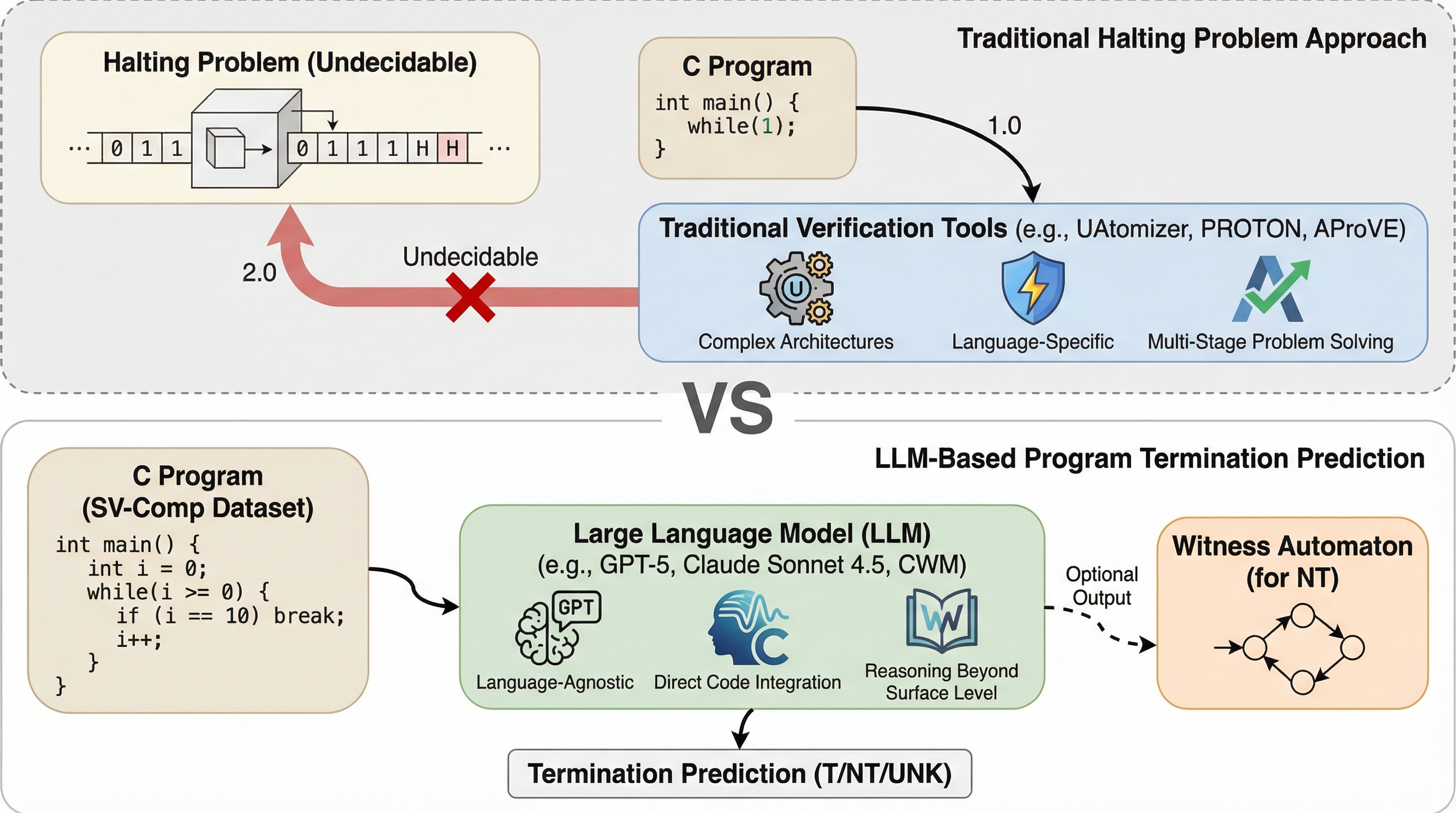
大規模言語モデル(LLM)は、計算機科学の難問である「停止問題」の予測において、専門的な検証ツールに匹敵する極めて高い性能を示した。特にGPT-5やClaude Sonnet-4.5は、国際的なソフトウェア検証コンペティション(SV-Comp 2025)のトップクラスのツールに次ぐスコアを記録し、その推論能力の高さが証明された。 一方で、プログラムが終了しないことの数学的な証明となる「証拠(ウィットネス)」の生成には依然として課題があり、コードの長さや複雑さが増すにつれて予測精度が低下する傾向も確認された。 信頼性を高めるために導入された「テストタイム・スケーリング(TTS)」による合意形成アルゴリズムは、モデルの不確実性を適切に管理し、誤判定によるペナルティを回避してスコアを劇的に向上させる有効な手段であることが明らかになった。
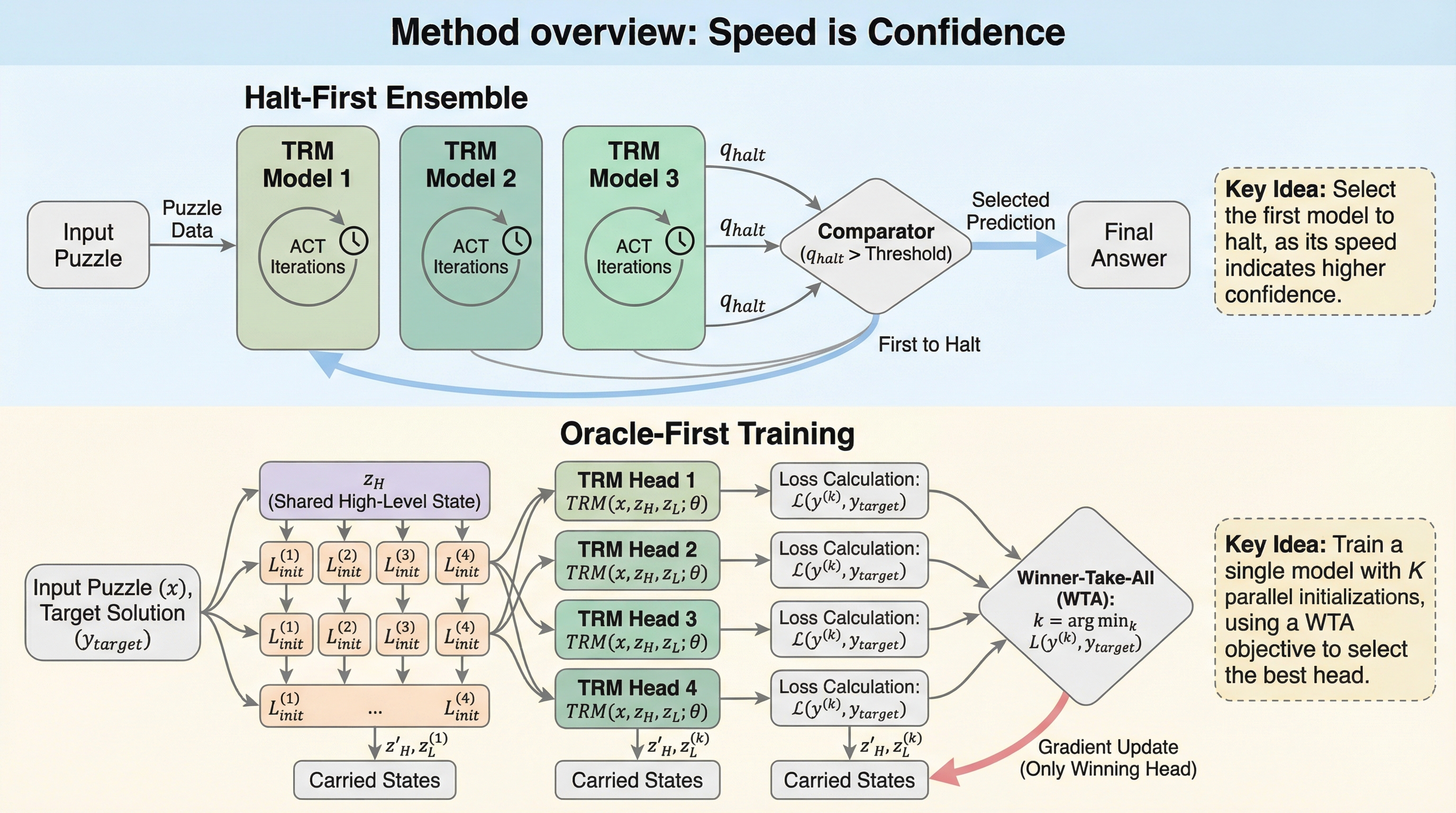
生物学的な神経系がエネルギー制約下で「最初の信号」に基づいて行動することに着想を得て、反復推論モデル(TRM)において推論速度を自信の指標として扱う手法を提案した。アンサンブル手法において、予測値を平均化するのではなく、最も早く停止信号を出したモデルの回答を採用する「halt-first」選択により、計算量を10分の1に削減しつつ、Sudoku-Extremeでの正解率を91.5%から97.2%へと大幅に向上させた。 この特性を単一モデルに内蔵するため、訓練時に4つの並列な潜在状態を維持し、最も損失が低い「勝者」のみを誤差逆伝播させる「Winner-Take-All(WTA)」学習を導入した。これにより、推論時の計算コストを増やすことなく、従来のテスト時拡張(TTA)に匹敵する96.9%の精度を達成し、ベースラインモデルの86.1%を大きく上回る結果を得た。 消費者向けハードウェアであるRTX 5090単体での実験を可能にするため、Muon最適化手法と改良型SwiGLUを組み合わせ、学習の高速化と安定化を実現した。推論速度が平衡状態の条件の良さを反映するという理論的解釈を示し、反復型モデルにおける「速さは自信である」という直感を数学的に裏付けた。
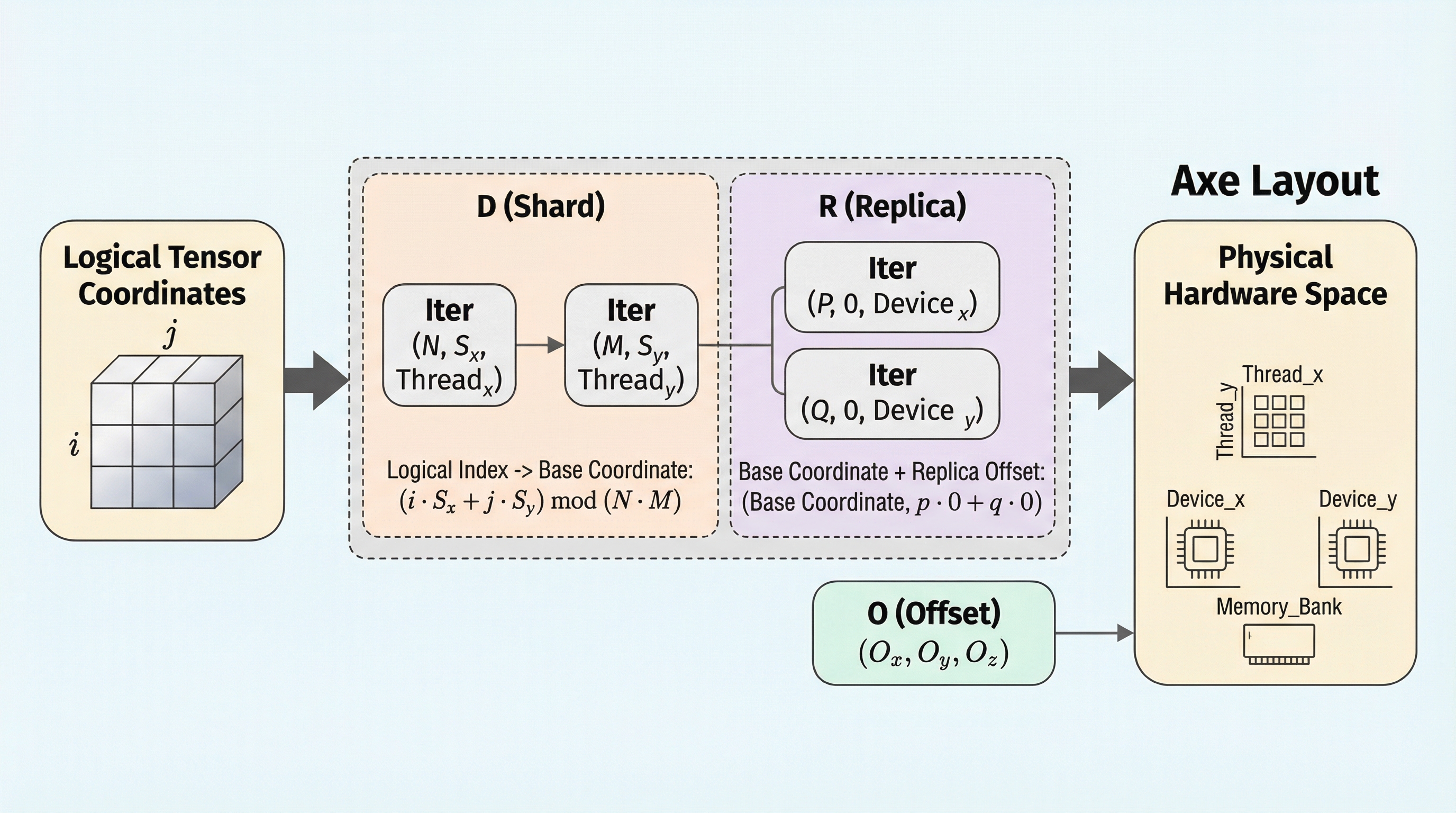
現代の深層学習ワークロードのスケールアップに伴い、デバイスメッシュやメモリ階層、異種アクセラレータ間でのデータと計算の調整が不可欠となっていますが、本論文は論理的なテンソル座標を「名前付き軸」を介して多軸物理空間にマッピングする、ハードウェアを意識した抽象化「Axe Layout」を提案しています。