VidLaDA: 効率的なビデオ理解のための双方向拡散大規模言語モデル
従来のビデオ大規模言語モデルが抱えていた自己回帰型モデル特有の単方向アテンションによる理解の限界と、逐次デコードによる生成速度の遅さを、双方向アテンションを持つ拡散言語モデル(DLM)を採用することで根本から解決した。
TL;DR(結論)
従来のビデオ大規模言語モデルが抱えていた自己回帰型モデル特有の単方向アテンションによる理解の限界と、逐次デコードによる生成速度の遅さを、双方向アテンションを持つ拡散言語モデル(DLM)を採用することで根本から解決した。 新たに提案されたVidLaDAは、ビデオ内の時空間情報を全方位から統合的に処理し、複数のトークンを並列に生成することで、従来の自己回帰型モデルと同等以上の精度を維持しながら、効率的なビデオ理解と推論を実現している。 さらに、マルチモーダルな情報の冗長性を排除する加速戦略「MARS-Cache」を導入したことで、精度を損なうことなく従来の拡散モデルと比較して12倍以上のスループット向上を達成し、長時間のビデオ解析における実用性を大幅に高めた。
なぜこの問題か
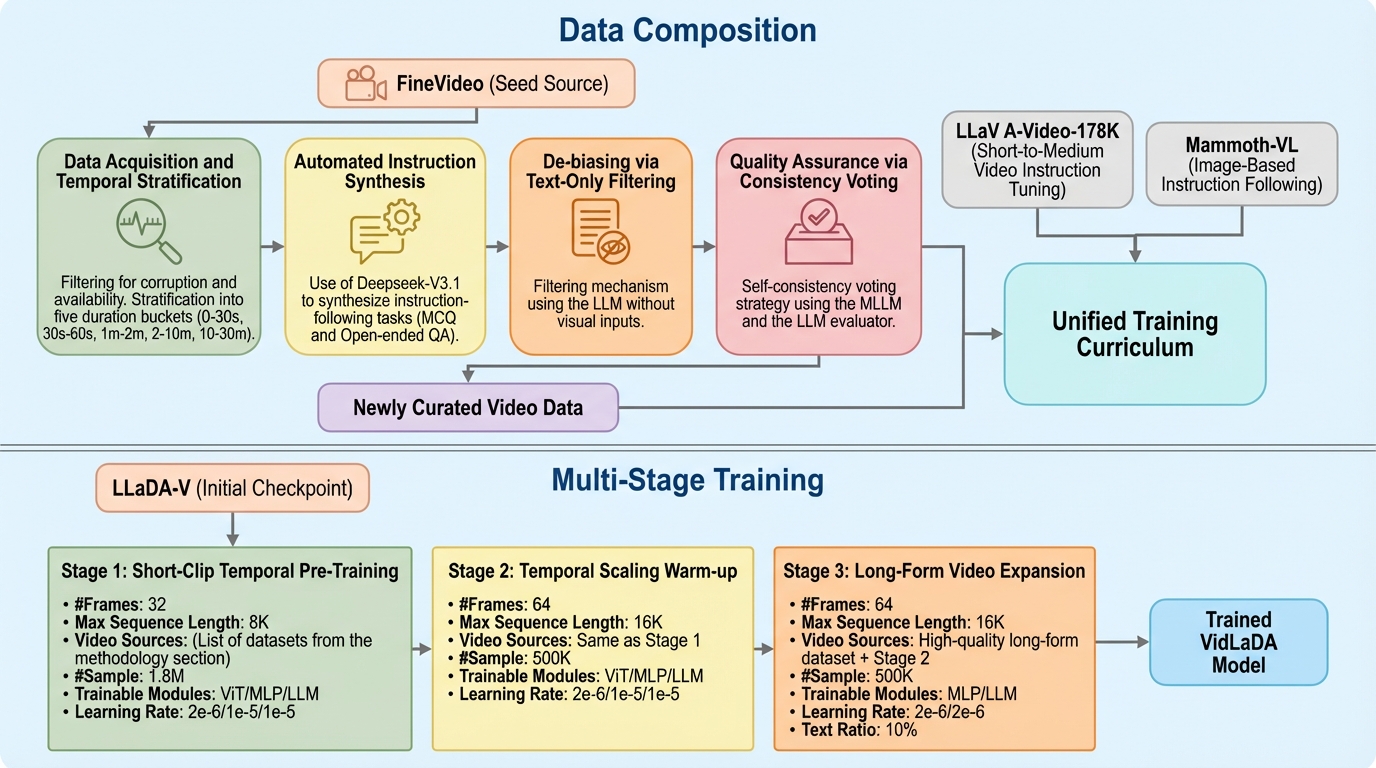
現在のビデオ大規模言語モデル(Video LLM)の多くは、画像を処理するビジョンエンコーダーと、テキストを生成する自己回帰型(AR)の大規模言語モデルを組み合わせた構成を採用している。しかし、この自己回帰的なアプローチには、ビデオという情報の性質とモデルの構造との間に根本的なミスマッチが存在している。テキストとは異なり、ビデオ内の視覚的な意味(物体、関係性、イベントの兆候)は時間と空間の中に分散しており、本質的に左から右へという順序を持っているわけではない。それにもかかわらず、自己回帰型モデルでは過去のトークンから未来のトークンを予測するという単方向の制約(因果的アテンションマスク)が課されている。 この制約は、モデルの理解効率を著しく低下させる二重のボトルネックを生み出している。第一に、単方向のアテンションは、ビデオ全体の時空間的な情報を統合することを妨げる。初期のトークンは後続の多くの位置から参照される一方で、後半のトークンは構造的に十分に注目されないという「受容野の非対称性」が生じる。これにより、重要な視覚的証拠がビデオの後半にある場合に、モデルがそれを十分に活用できないという位置バイアスが発生する。…
核心:何を提案したのか
本研究では、上述した自己回帰型モデルの限界を打破するために、拡散言語モデル(DLM)をベースとした新しいビデオ理解モデル「VidLaDA」を提案している。VidLaDAの最大の特徴は、自己回帰的な制約を完全に取り払い、フル双方向アテンション(Full Bidirectional Attention)を採用した点にある。これにより、ビデオトークン、テキストプロンプト、そして生成途中の回答トークンのすべてが、互いに全方位的に相互作用することが可能になった。この設計により、ビデオ内のどの時点にある情報であっても、モデルはグローバルな文脈の中で等しくアクセスし、統合することができる。 VidLaDAは、生成プロセスを離散空間における反復的なデノイジング(ノイズ除去)として定式化している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related