Lattice:対話エージェントのための生成的ガードレール
従来の対話型AIにおけるガードレールは、あらかじめ定義された静的なルールに依存しているため、運用中に発生する新しい脅威や多様な展開コンテキストに柔軟に適応できないという深刻な課題を抱えていたが、本研究ではガードレールの自己構築と継続的な自動改善を実現する革新的なフレームワーク「Lattice」を提案した。
TL;DR(結論)
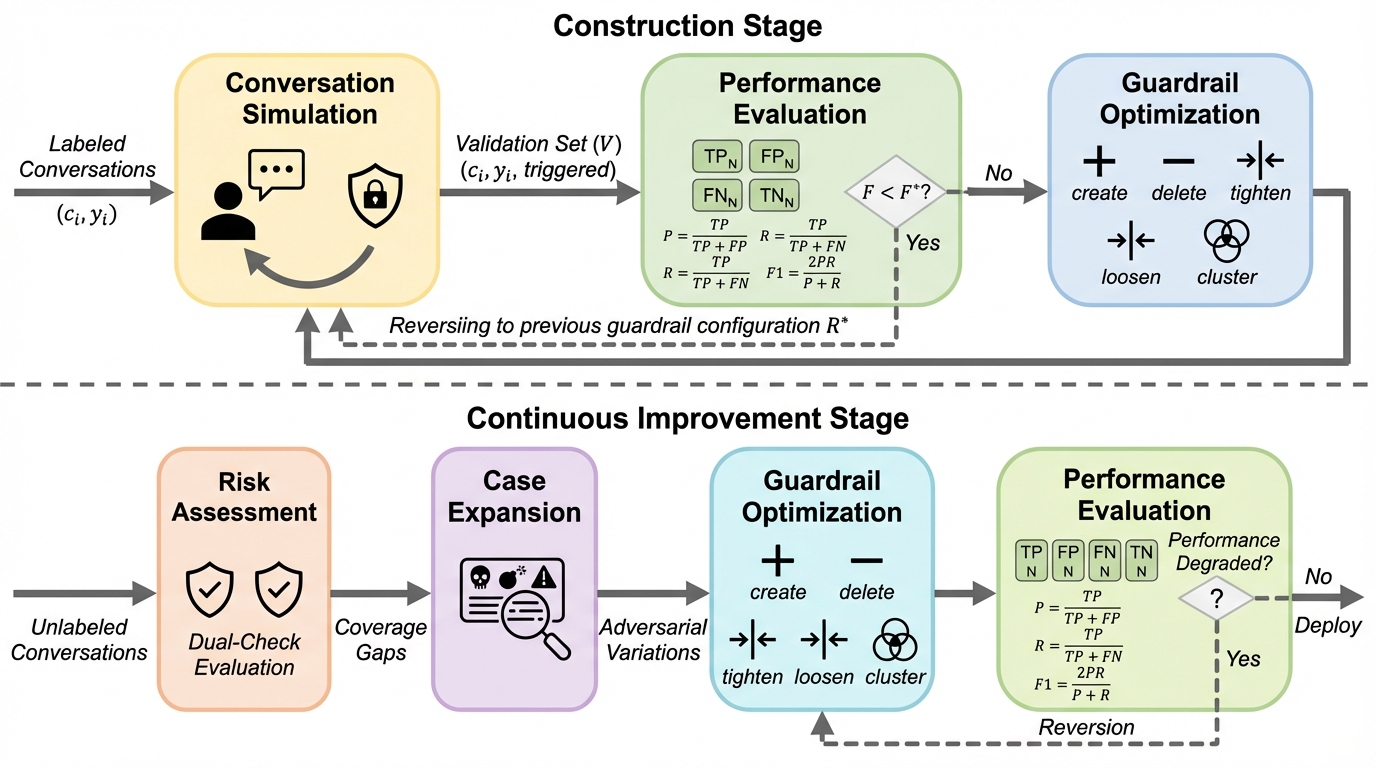
従来の対話型AIにおけるガードレールは、あらかじめ定義された静的なルールに依存しているため、運用中に発生する新しい脅威や多様な展開コンテキストに柔軟に適応できないという深刻な課題を抱えていたが、本研究ではガードレールの自己構築と継続的な自動改善を実現する革新的なフレームワーク「Lattice」を提案した。 Latticeは二段階のプロセスで構成されており、まずラベル付きの少数の例から反復的な対話シミュレーションと最適化を経て初期ガードレールを構築し、次に展開後の運用フェーズにおいてリスク評価や敵対的ビームサーチを用いたテストを通じて、未知の攻撃や文脈のギャップを埋めるようにルールを自律的に進化させ続ける仕組みを持つ。 ProsocialDialogデータセットを用いた評価では、91%という高いF1スコアを記録し、従来のキーワードマッチングを43ポイント、LlamaGuardを25ポイント、NeMo Guardrailsを4ポイント上回る優れた性能を実証したほか、ドメインを跨いだ継続改善ステージにおいても閉ループ最適化によりF1スコアをさらに7ポイント向上させる成果を上げた。
なぜこの問題か
大規模言語モデル(LLM)を対話型AIシステムとして展開する際、その高い能力と安全性の確保の間には根本的な緊張関係が存在している。システムは多様な文脈で自然に応答する必要がある一方で、現実世界の運用においては有害な出力を防ぐための強固なメカニズムが不可欠である。現在の対話の安全性確保におけるアプローチは、主に静的なガードレールメカニズムに基づいている。これらのシステムは、あらかじめ決められたパターンに基づいて入力クエリやLLMの出力をフィルタリングするように設計された固定のルールセットを採用している。しかし、このような静的なガードレールには、展開されたシステムにおける有効性を損なう二つの重大な限界があることが指摘されている。 第一に、展開後に新たに出現する攻撃ベクトルや対話の文脈に適応することができないという点である。第二に、既存の保護機能を回避するために特別に細工された敵対的な入力に対して、システムが脆弱性を示すという脆さがある。これらの限界は、より深いアルゴリズム上の課題を浮き彫りにしている。…
核心:何を提案したのか
本研究では、ガードレールの構築と適応を継続的な最適化問題として扱うフレームワークである「Lattice」を提案した。Latticeは、設計時に定義された固定ルールに依存するのではなく、反復的な対話シミュレーションを通じて初期のガードレールセットを構築し、さらに展開後も継続的にそれらを改善していくというアプローチをとる。このフレームワークは大きく分けて二つのステージで構成されている。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related