速さは自信
生物学的な神経系がエネルギー制約下で「最初の信号」に基づいて行動することに着想を得て、反復推論モデル(TRM)において推論速度を自信の指標として扱う手法を提案した。アンサンブル手法において、予測値を平均化するのではなく、最も早く停止信号を出したモデルの回答を採用する「halt-first」選択により、計算量を10分の1に削減しつつ、Sudoku-Extremeでの正解率を91.5%から97.2%へと大幅に向上させた。 この特性を単一モデルに内蔵するため、訓練時に4つの並列な潜在状態を維持し、最も損失が低い「勝者」のみを誤差逆伝播させる「Winner-Take-All(WTA)」学習を導入した。これにより、推論時の計算コストを増やすことなく、従来のテスト時拡張(TTA)に匹敵する96.9%の精度を達成し、ベースラインモデルの86.1%を大きく上回る結果を得た。 消費者向けハードウェアであるRTX 5090単体での実験を可能にするため、Muon最適化手法と改良型SwiGLUを組み合わせ、学習の高速化と安定化を実現した。推論速度が平衡状態の条件の良さを反映するという理論的解釈を示し、反復型モデルにおける「速さは自信である」という直感を数学的に裏付けた。
TL;DR(結論)
生物学的な神経系がエネルギー制約下で「最初の信号」に基づいて行動することに着想を得て、反復推論モデル(TRM)において推論速度を自信の指標として扱う手法を提案した。アンサンブル手法において、予測値を平均化するのではなく、最も早く停止信号を出したモデルの回答を採用する「halt-first」選択により、計算量を10分の1に削減しつつ、Sudoku-Extremeでの正解率を91.5%から97.2%へと大幅に向上させた。 この特性を単一モデルに内蔵するため、訓練時に4つの並列な潜在状態を維持し、最も損失が低い「勝者」のみを誤差逆伝播させる「Winner-Take-All(WTA)」学習を導入した。これにより、推論時の計算コストを増やすことなく、従来のテスト時拡張(TTA)に匹敵する96.9%の精度を達成し、ベースラインモデルの86.1%を大きく上回る結果を得た。 消費者向けハードウェアであるRTX 5090単体での実験を可能にするため、Muon最適化手法と改良型SwiGLUを組み合わせ、学習の高速化と安定化を実現した。推論速度が平衡状態の条件の良さを反映するという理論的解釈を示し、反復型モデルにおける「速さは自信である」という直感を数学的に裏付けた。
なぜこの問題か
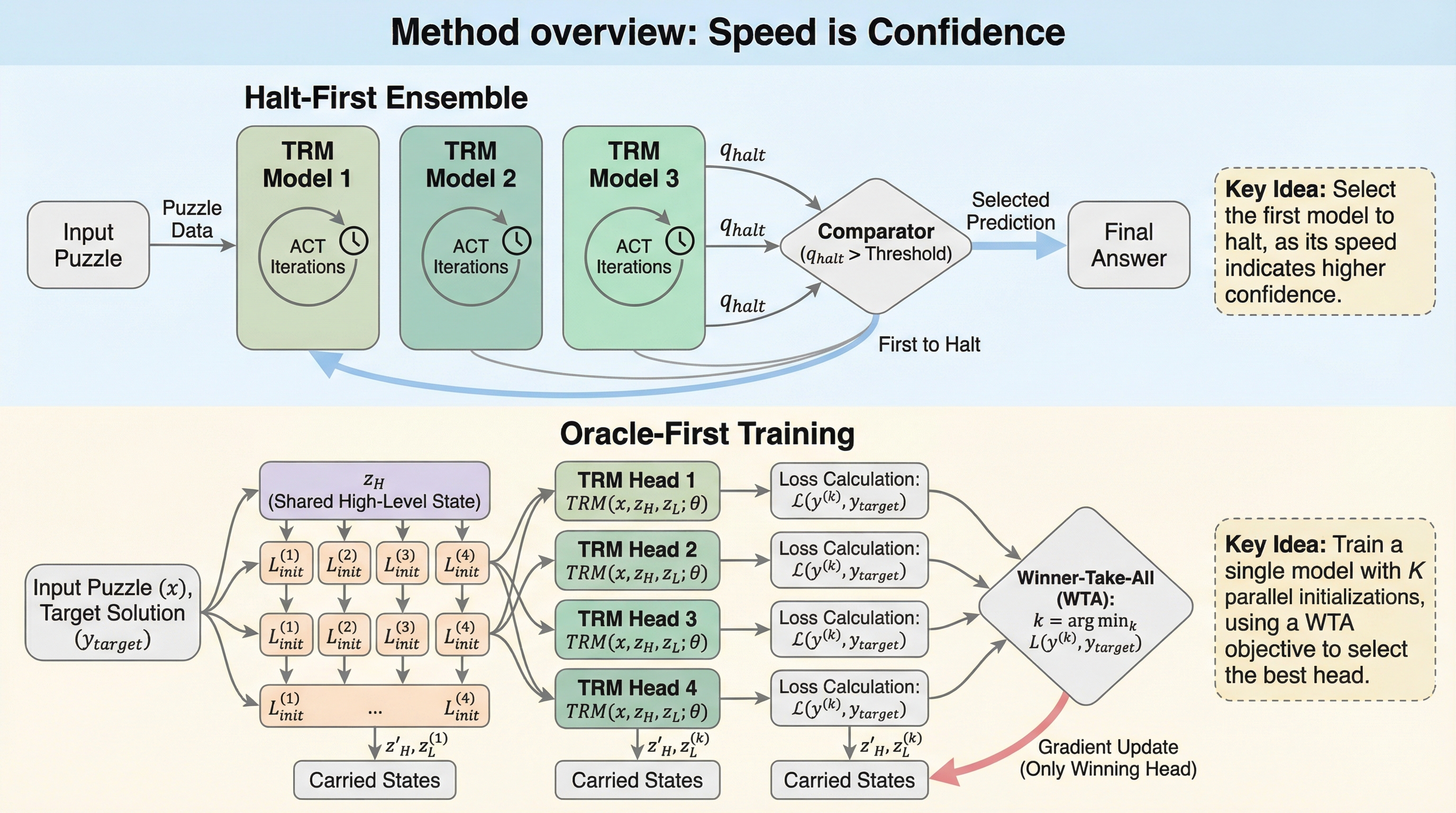
生物学的な神経システムは、常に厳しいエネルギー制約にさらされながらも、迅速な意思決定を迫られている。進化の過程で導き出された解決策は、不確実な状況下で無限に熟考するのではなく、最初に到達した確信的な信号に基づいて行動することであった。例えば、皮質の勝者総取り(Winner-Take-All)回路では、競合する神経集団が閾値を目指して競争し、最初に発火したものが他を抑制して行動を誘発する。この「最初の発火までの時間」に情報をエンコードする「time-to-first-spike(TTFS)」コーディングは、速度とエネルギー効率の両立を可能にしている。 現代のニューラルネットワーク、特に反復的な推論を行うモデルにおいても、同様の課題が存在する。標準的なアンサンブル手法では、複数のモデルの予測値を単純に平均化するが、これは各モデルがいつ回答に到達したかというタイミングの情報を完全に無視している。適応的計算時間(ACT)を用いるモデルにおいて、収束の速さはその推論パスが「クリーン」であること、つまり矛盾や後戻りがないことを示唆する重要な信号である。…
核心:何を提案したのか
本研究の核心的な提案は、推論速度を自信の明示的な表現として扱う二つの手法である。第一に、アンサンブル推論において「最初に停止したモデルの回答を採用する(halt-first selection)」という単純かつ強力なルールを提案した。これは、複数のモデルを並列に走らせ、いずれかのモデルが停止閾値を超えた瞬間にその回答を最終出力とするものである。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related