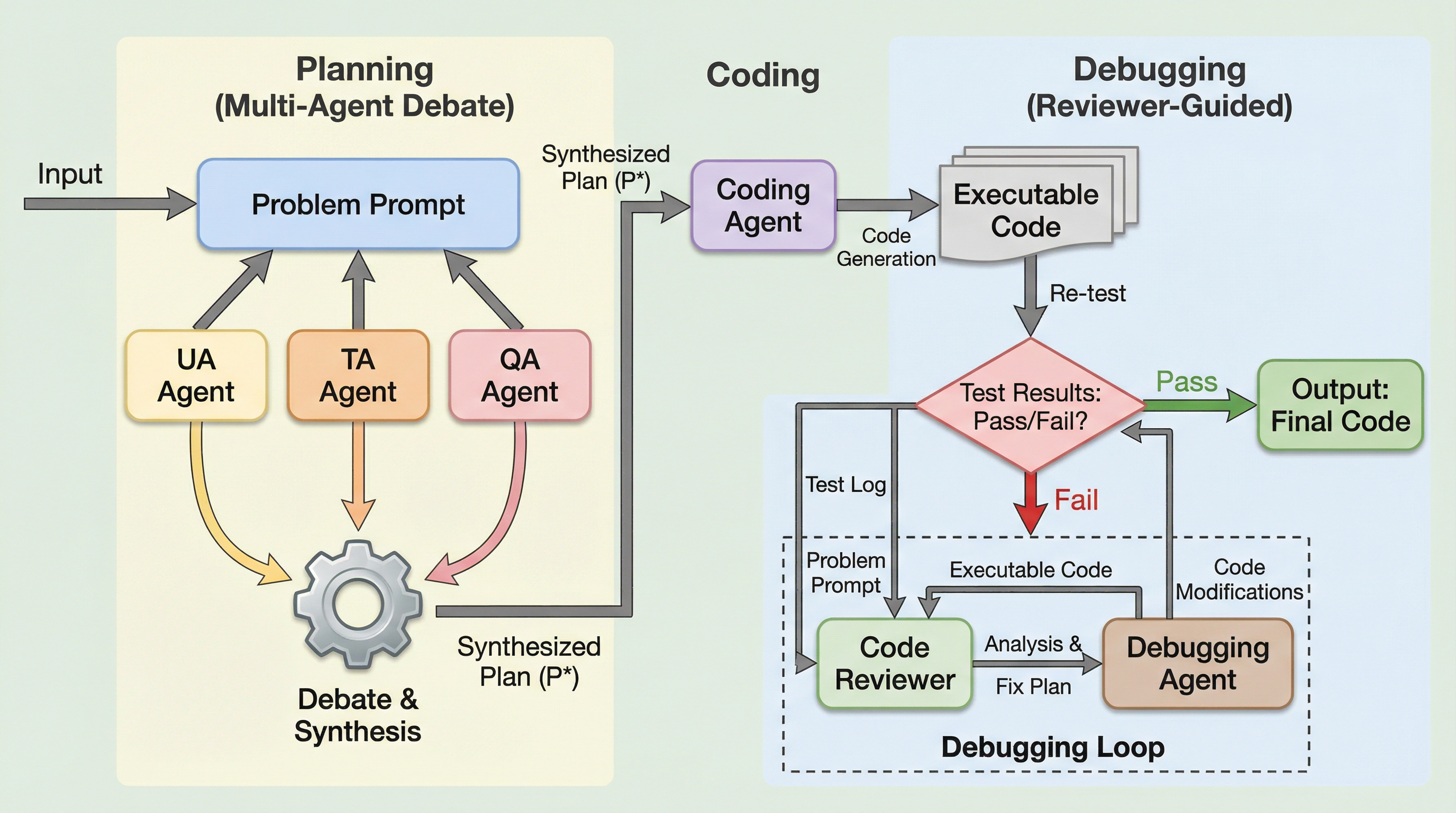
マルチエージェント連携と適応型信頼ゲートによる効率的かつ最適化されたコード生成
大規模言語モデルが自動コード生成で成果を上げる一方、Pangu-1Bのような小規模言語モデル(SLM)は複雑な論理推論において文脈維持が困難な「推論のボトルネック」や、同じ誤りを繰り返す「失敗ループ」という課題を抱えています。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
大規模言語モデルが自動コード生成で成果を上げる一方、Pangu-1Bのような小規模言語モデル(SLM)は複雑な論理推論において文脈維持が困難な「推論のボトルネック」や、同じ誤りを繰り返す「失敗ループ」という課題を抱えています。
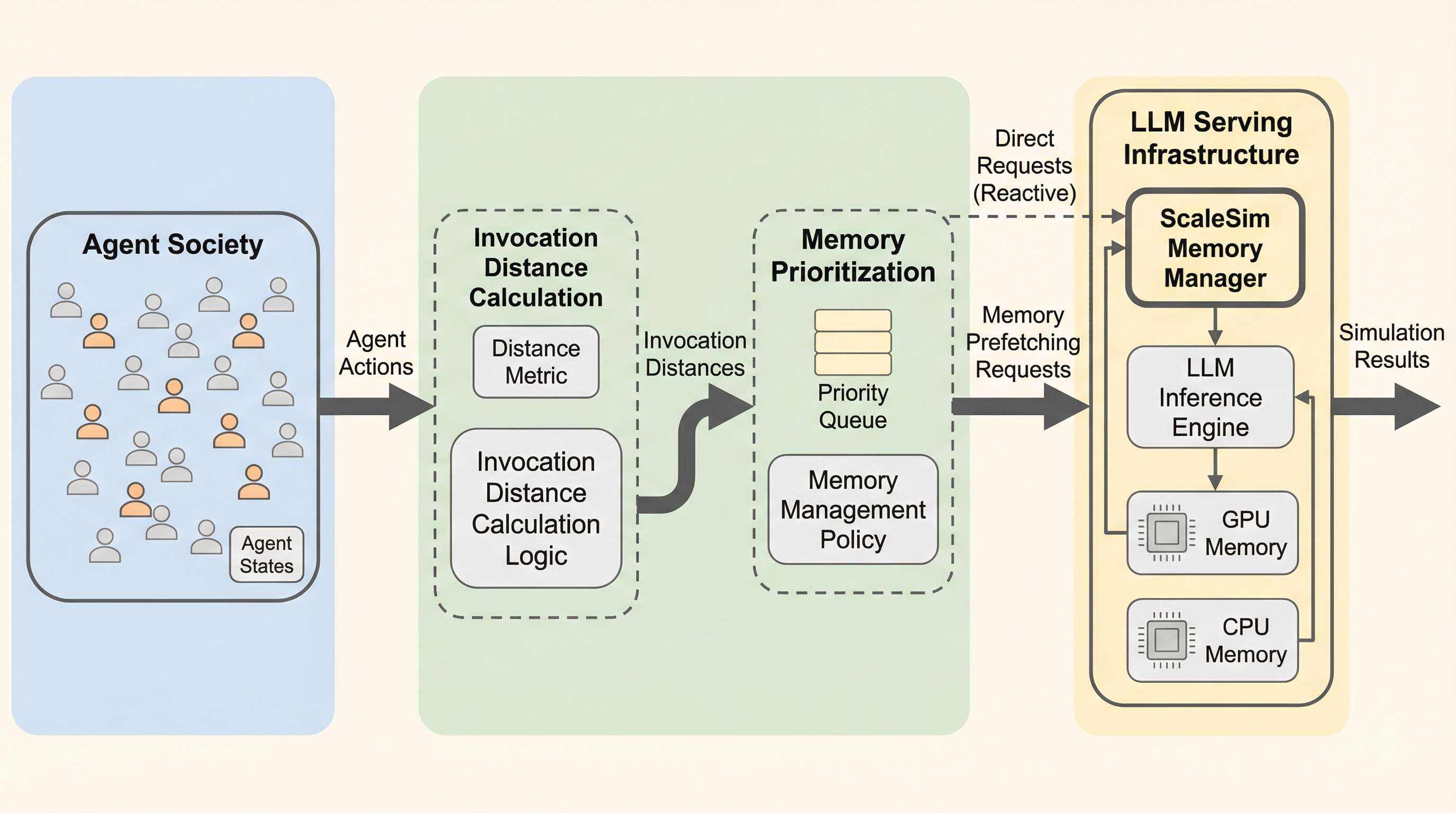
大規模なマルチエージェント・シミュレーションにおいて、各エージェントが個別に保持するLoRAアダプタやキャッシュなどの膨大なメモリ消費がGPUの物理容量を超え、頻繁なデータ転送による深刻な遅延が発生している。
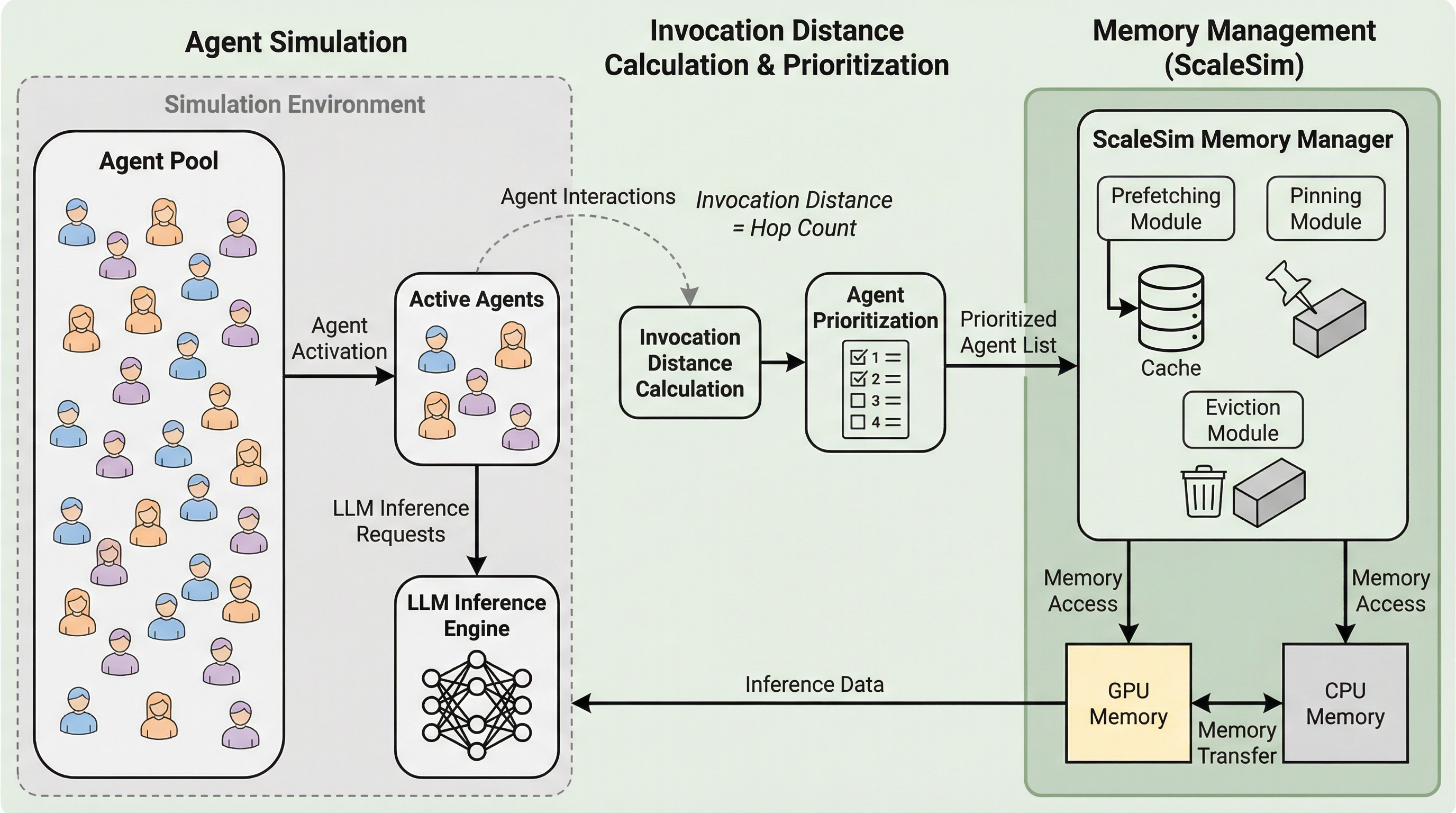
大規模言語モデルを用いたマルチエージェントシミュレーションでは、エージェント数の増加に伴い、各個体が保持するLoRAアダプタやプレフィックスキャッシュなどの膨大な専用データがGPUメモリを圧迫し、頻繁なデータ転送による遅延が深刻なボトルネックとなっている。
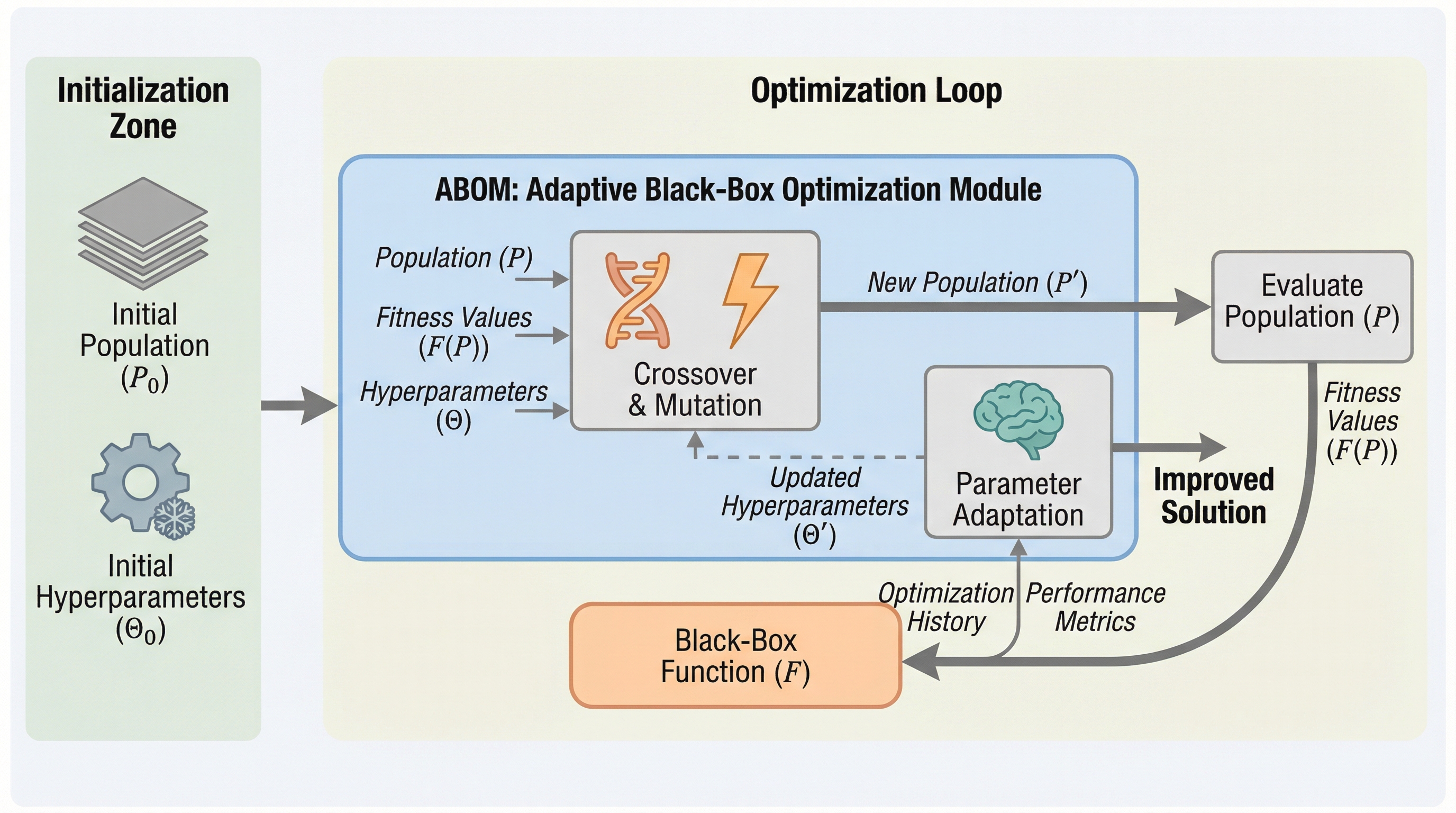
従来のメタブラックボックス最適化(MetaBBO)は、未知のタスクに汎化させるために事前に大量の手動設計された学習タスクを必要とするという大きな制約がありましたが、本研究で提案された「ABOM」は、ターゲットとなるタスクの最適化プロセスで生成されるデータのみを用いてオンラインでパラメータを適応させることで、この制約を根本から解消します。 進化計算の主要な操作である選択、交叉、変異を注意機構(Attention Mechanism)を用いた微分可能な関数として定義し、生成された個体群をエリートアーカイブに近づけるように自己更新を行うクローズドループの学習メカニズムを導入することで、事前のメタ学習を一切行わない「ゼロショット最適化」を実現しました。 合成ベンチマークおよび無人航空機の経路計画問題を用いた検証により、提案手法は高次元の問題においても既存の高度なアルゴリズムを凌駕する性能を達成しただけでなく、注意行列の可視化を通じて自然選択や遺伝的再結合といった探索パターンの統計的な解釈性を提供することが確認されています。
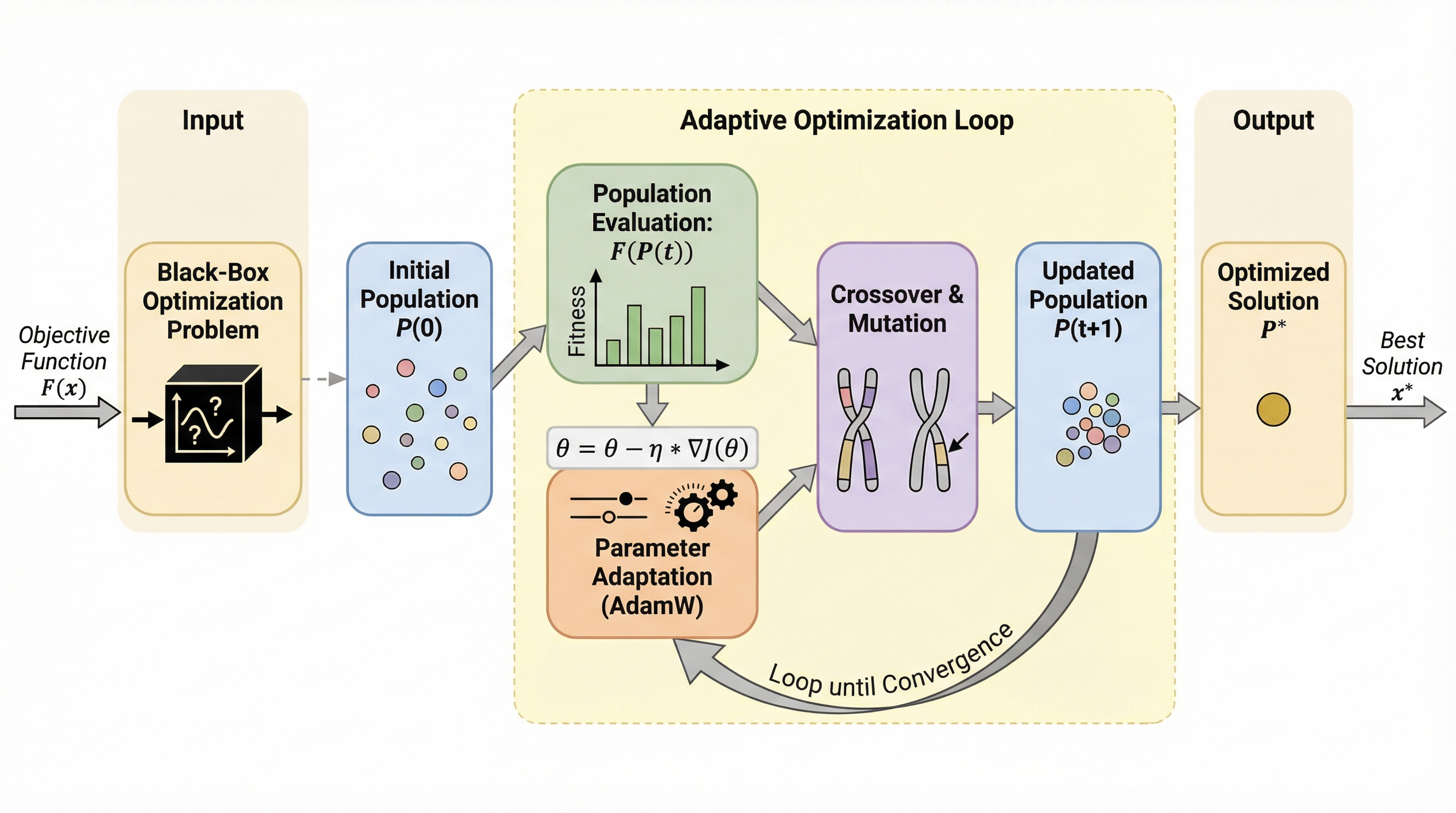
従来のメタブラックボックス最適化(MetaBBO)は、未知のタスクへ適応するために事前に設計された膨大な学習用タスク分布を必要としていたが、本研究が提案するABOM(Adaptive meta Black-box Optimization Model)は、ターゲットとなるタスクから得られる自己生成データのみを用いてオンラインでパラメータを適応させる。 このモデルは、進化計算の主要なオペレータである選択、交叉、突然変異をアテンション機構に基づいた微分可能な関数として定義しており、生成された個体群とエリートアーカイブの距離を最小化するようにパラメータをリアルタイムで更新することで、事前のメタ学習フェーズを一切必要としない「ゼロショット最適化」を実現している。 合成ベンチマーク(BBOB)や実世界の無人航空機(UAV)経路計画問題において、ABOMは事前に学習済みの最新メタ学習手法や高度に調整された適応型アルゴリズムと同等以上の性能を発揮し、さらにGPU加速への対応やアテンション行列を通じた探索パターンの可視化による高い解釈性、および全域収束性の理論的保証を兼ね備えている。
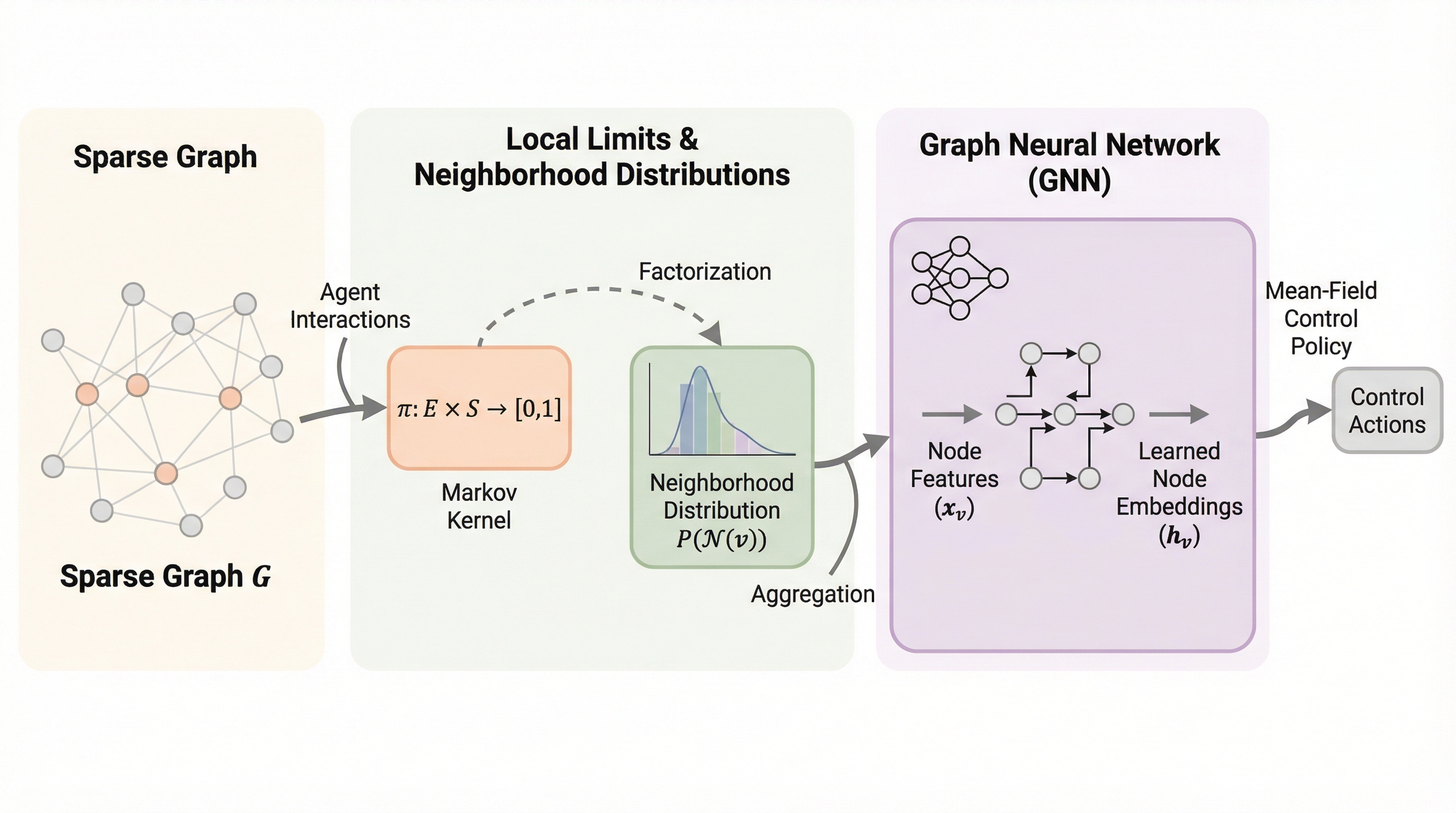
大規模マルチエージェントシステムにおいて、従来の平均場制御が前提としていた「全エージェント間の一様な相互作用」という制約を打破し、現実的な希薄グラフ上での制御を可能にする理論的枠組み「Sparse-MFC」が提案されました。
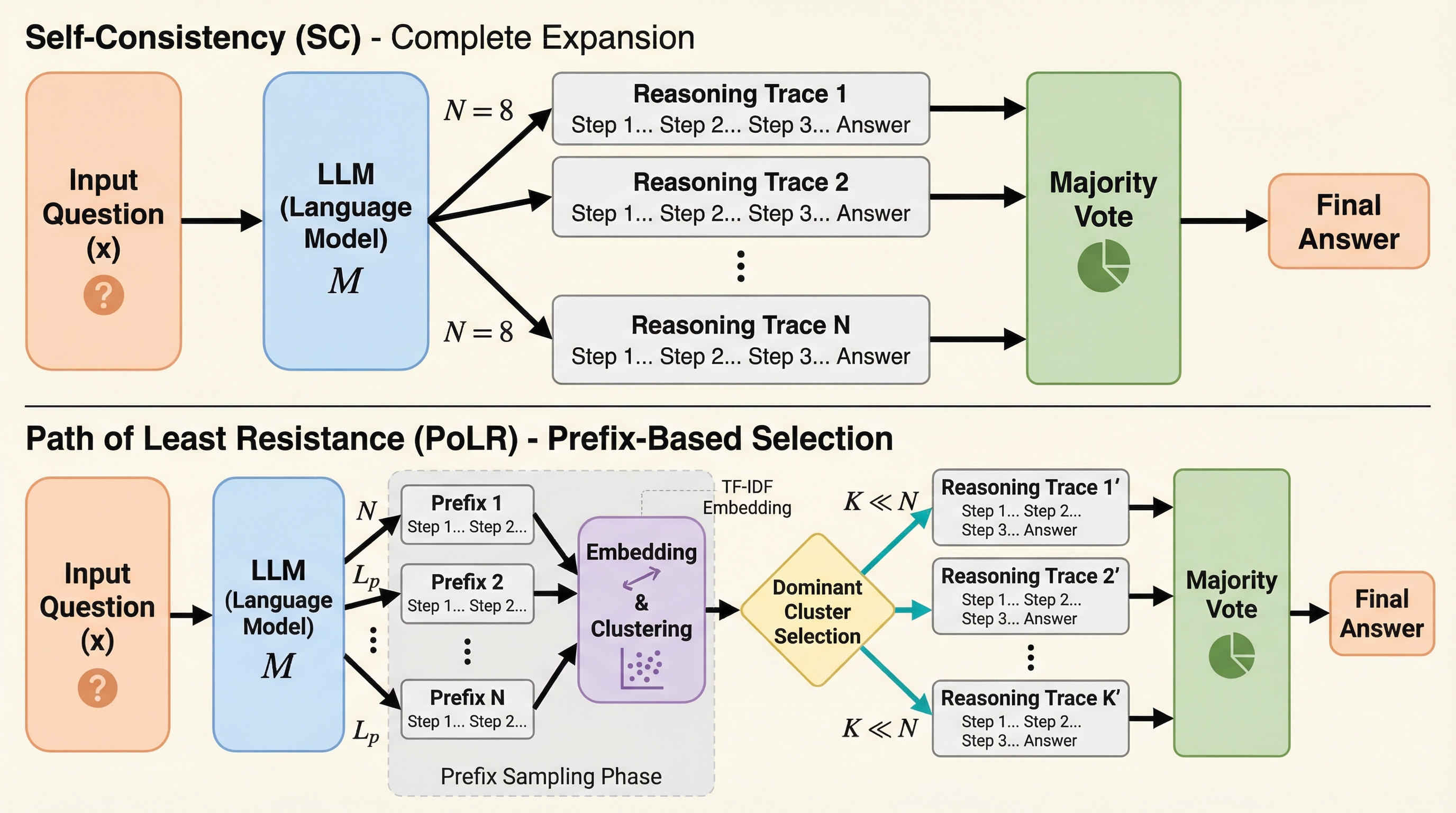
PoLR(Path of Least Resistance)は、大規模言語モデル(LLM)の推論コストを劇的に削減するために開発された、推論時に適用可能な新しいアルゴリズムである。従来のSelf-Consistency(SC)がすべての推論経路を最後まで生成して計算資源を浪費するのに対し、本手法は初期の短い断片(プレフィックス)を生成した段階でクラスタリングを行い、最も有力なグループのみを拡張することで無駄な計算を排除する。 数学や科学などの多様なベンチマークにおいて、SCと同等以上の精度を維持しながら、トークン使用量を最大60%、実行時間を最大50%削減することに成功しており、モデルの追加学習を必要としないドロップイン型の代替案として極めて高い実用性を持つ。 理論的な分析により、推論の初期段階には最終的な正解を予測するための強い信号が含まれていることが示されており、この「プレフィックスの一貫性」を利用することで、効率性と精度の両立を実現している。既存の適応的推論手法とも完全に補完関係にあり、それらと組み合わせることでさらなる計算資源の節約が可能となる。
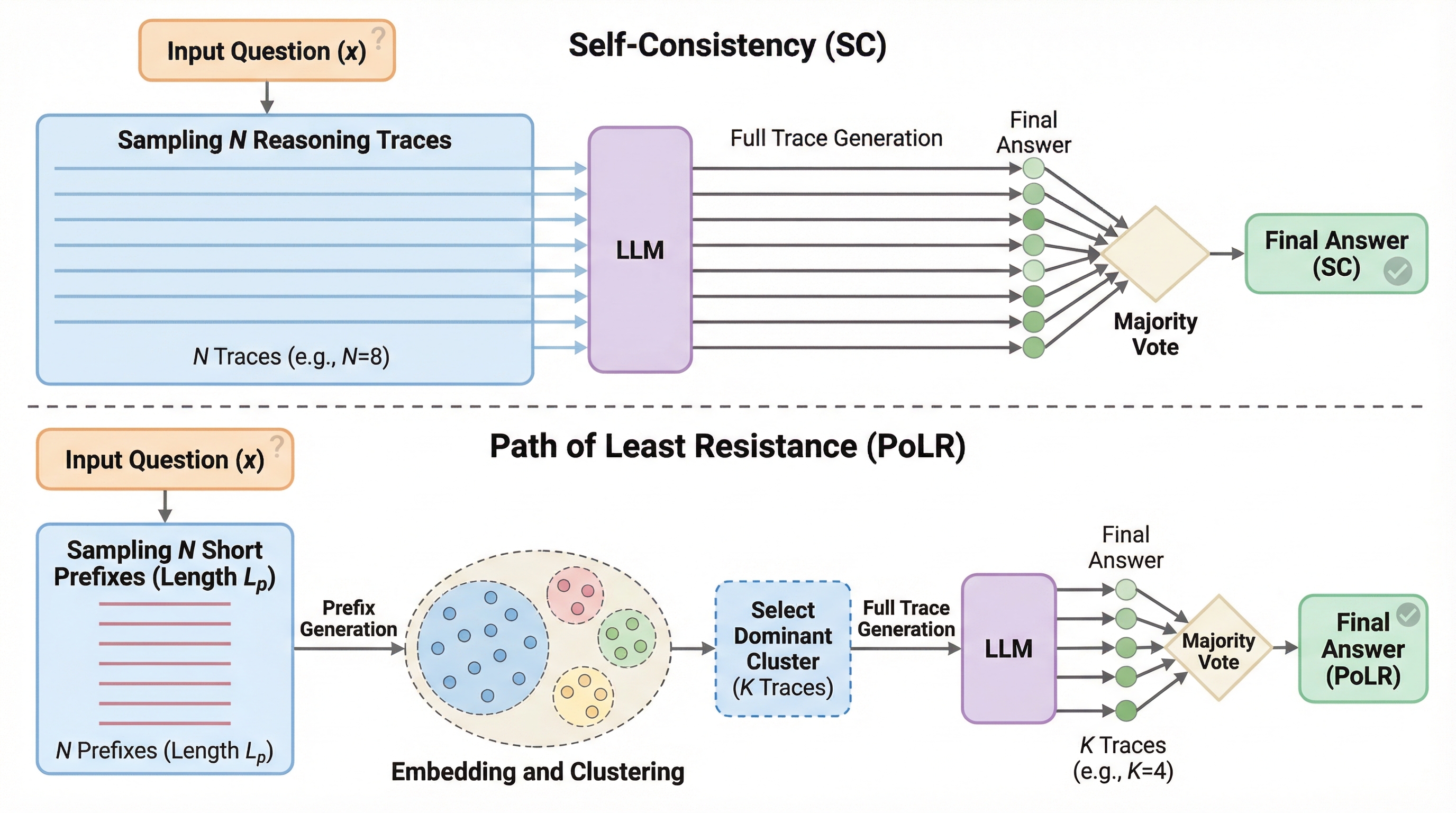
大規模言語モデル(LLM)の推論精度を向上させる自己整合性(Self-Consistency)は、全推論経路を最後まで生成するため計算コストが極めて高いという課題がありますが、本研究は推論の初期段階である「接頭辞」に正解を予測する強力な信号が含まれるという「接頭辞の合意」現象に着目した新手法PoLR(Path of Least Resistance)を提案しました。 PoLRは、まず複数の短い接頭辞を生成してクラスタリングを行い、最も支配的な推論グループのみを最後まで拡張することで、精度を維持または向上させながらトークン使用量を最大60パーセント、実行時間を最大50パーセント削減することに成功しており、モデルの微調整を必要としない推論時のプラグインとして機能します。 数学(GSM8K、MATH500、AIME24/25)や科学(GPQA-DIAMOND)などの難解な推論タスクにおいて、既存の適応型推論手法(Adaptive Consistencyなど)と組み合わせることでさらなる効率化が可能であり、1.5Bから32Bまでの多様なモデル規模でその有効性と実用性が実証されました。
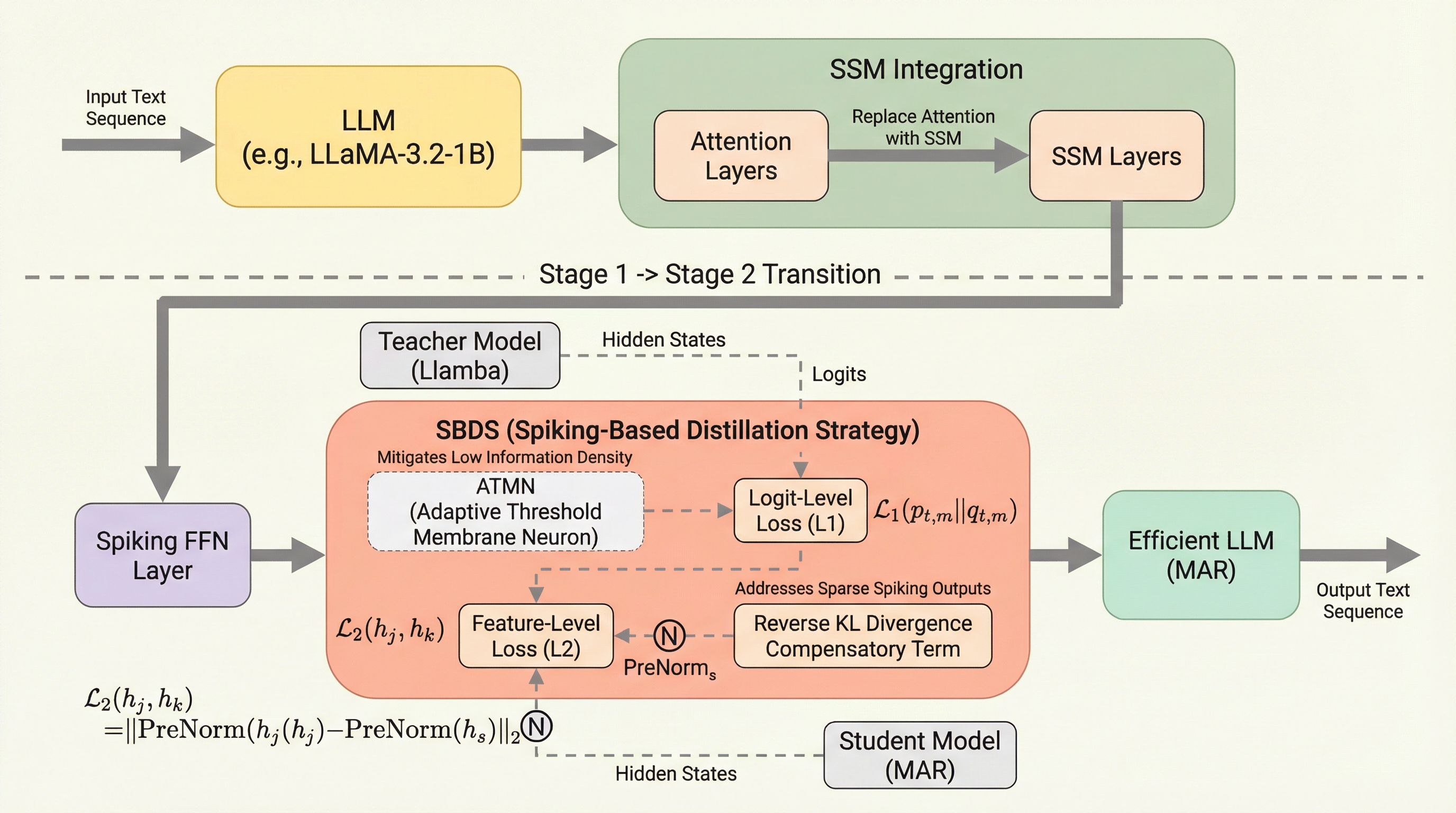
大規模言語モデルの計算コストとエネルギー消費を削減するため、アテンション機構を状態空間モデル(SSM)に置き換えて線形時間処理を実現し、さらにFFN層をスパイキングニューラルネットワーク(SNN)で疎化する二段階フレームワーク「MAR」を提案しています。
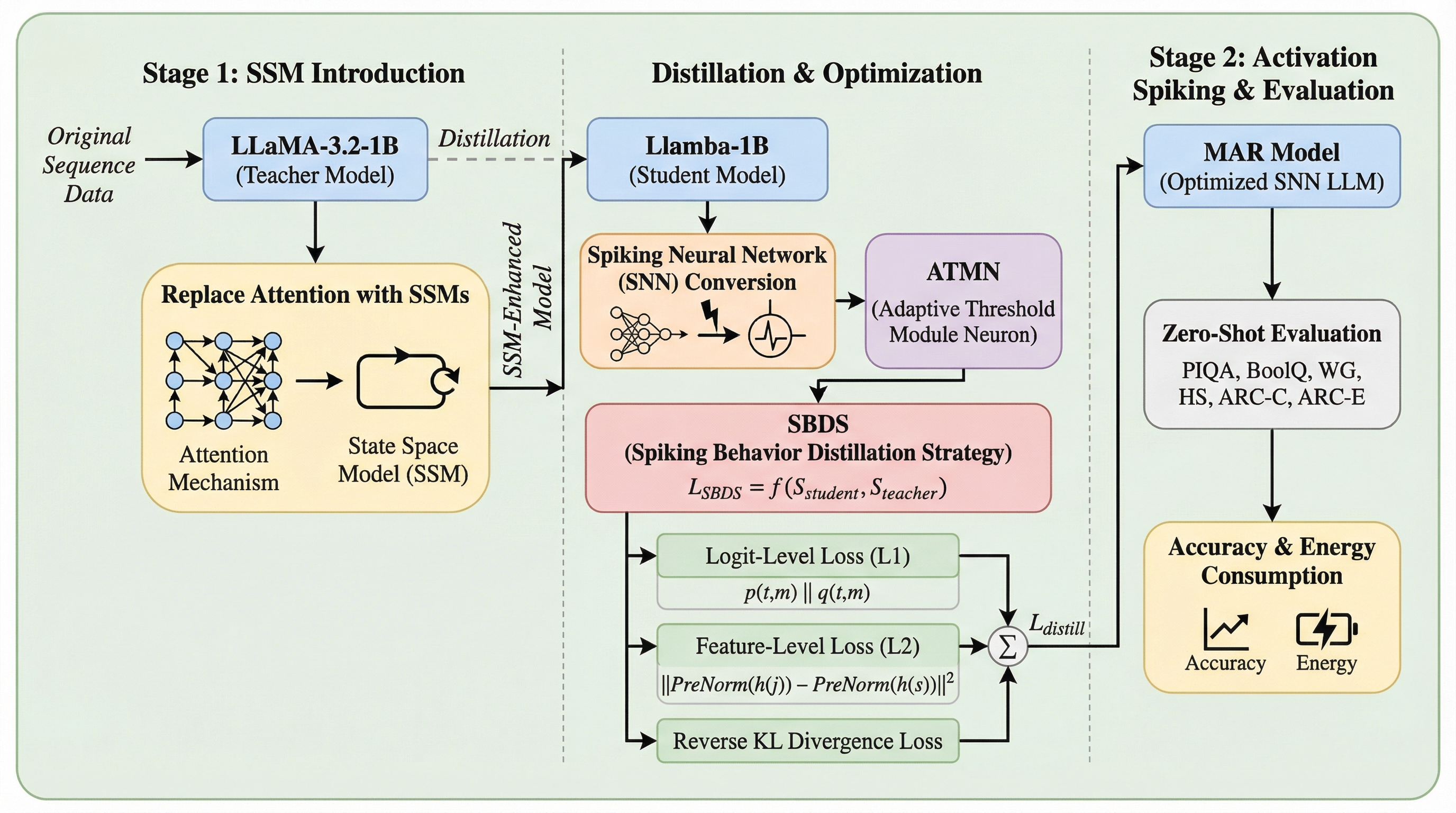
MARは、計算負荷の高い注意機構を線形時間の状態空間モデル(SSM)に置き換えた上で、フィードフォワードネットワーク(FFN)をスパイキングニューラルネットワーク(SNN)によってスパース化する、二段階のモジュール対応アーキテクチャ洗練フレームワークである。