ScaleSim:呼び出し距離に基づくメモリ管理による大規模マルチエージェントシミュレーションの効率化
大規模言語モデルを用いたマルチエージェントシミュレーションでは、エージェント数の増加に伴い、各個体が保持するLoRAアダプタやプレフィックスキャッシュなどの膨大な専用データがGPUメモリを圧迫し、頻繁なデータ転送による遅延が深刻なボトルネックとなっている。
TL;DR(結論)
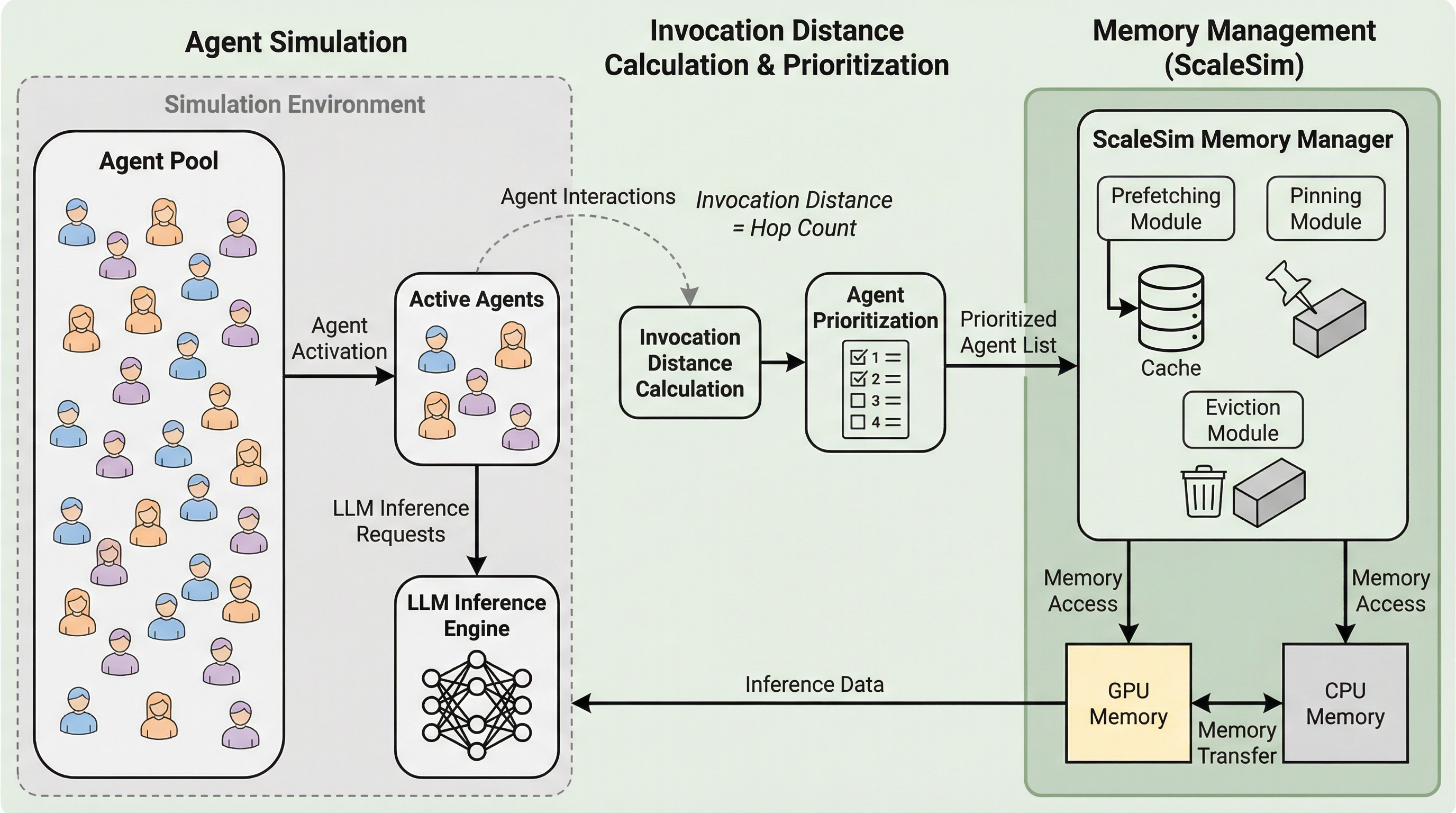
大規模言語モデルを用いたマルチエージェントシミュレーションでは、エージェント数の増加に伴い、各個体が保持するLoRAアダプタやプレフィックスキャッシュなどの膨大な専用データがGPUメモリを圧迫し、頻繁なデータ転送による遅延が深刻なボトルネックとなっている。 本研究が提案する「ScaleSim」は、エージェントが次にモデルを呼び出すまでの相対的な順序を推定する「呼び出し距離」という統一的な概念を導入し、この指標に基づいてメモリの能動的な事前読み込みや優先順位付きの破棄をインテリジェントに実行する。 この仕組みにより、エージェントの活動が時間的に疎であるという特性を最大限に活用し、既存のサービングシステムであるSGLangと比較して最大1.74倍の実行速度向上を達成し、限られた計算資源での大規模なエージェント社会の構築を可能にした。
なぜこの問題か
大規模言語モデル(LLM)を基盤としたマルチエージェントシミュレーションは、社会科学、自動運転、都市計画、ロボティクス、経済モデリングなど、非常に幅広い分野で複雑なシステムの挙動を分析するための重要なツールとなっている。しかし、シミュレーションの解像度を高めるためにエージェントの数を増やそうとすると、GPUメモリの物理的な容量制限という極めて厳しい壁に直面することになる。各エージェントは、自身の役割を定義するプロンプトや特定のタスクに適応するためのLoRAアダプタ、過去の行動履歴を保持するプレフィックスキャッシュ、さらにはベクトルデータベースのインデックスといった、エージェント固有のプライベートな状態をGPU上に保持しなければならない。エージェントの人口が増大するにつれて、これらのメモリ需要の総計は単一のGPU、あるいは複数のGPUの合計容量を容易に超えてしまう。 その結果、システムは実行中のエージェントのデータをホスト(CPU)とデバイス(GPU)の間で絶えず入れ替える必要に迫られ、膨大なI/Oオーバーヘッドが発生する。…
核心:何を提案したのか
本研究では、大規模マルチエージェントシミュレーションの効率を劇的に向上させる新しいLLMサービングシステムとして「ScaleSim」を提案した。ScaleSimの核心的な革新は、各エージェントが次にLLMリクエストを発行するまでの相対的な時間的間隔を推定する「呼び出し距離(invocation distance)」という統一された抽象化概念を導入した点にある。この概念により、システムはどのアダプタやキャッシュがいつ必要になるかを事前に予測し、メモリ管理の判断基準として活用することが可能になる。ScaleSimは、この呼び出し距離をガイドとして、メモリの能動的な事前読み込み(プリフェッチ)と、優先順位に基づいた賢いメモリ破棄(エビクション)を実現する。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related