OCR強化型マルチモーダルASRは聞きながら読むことができる
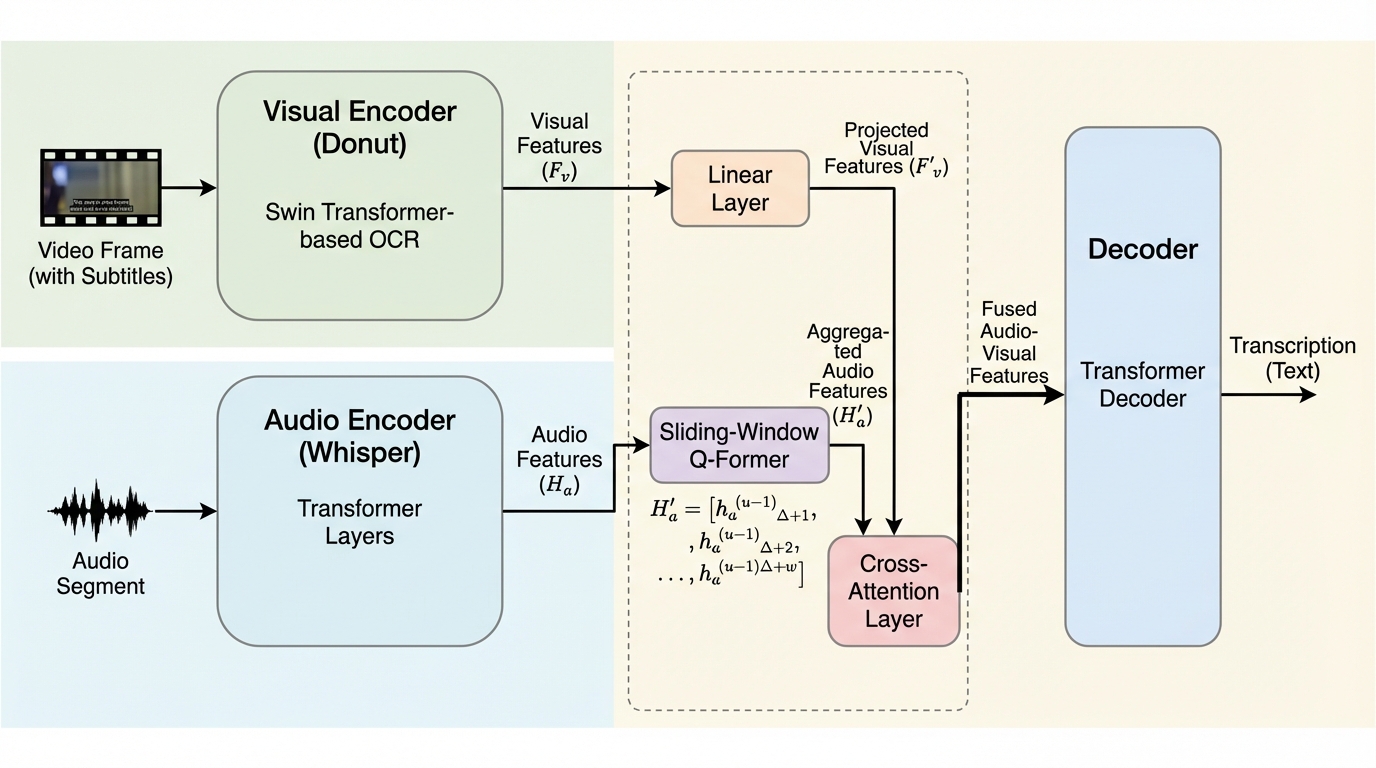
本研究では、音声認識モデルのWhisperとOCRモデルのDonutを統合した、エンドツーエンドのマルチモーダル音声認識モデル「Donut-Whisper」を提案し、映画の字幕などの視覚的なテキスト情報を活用することで、音声のみのモデルが苦手とするノイズ環境や未知語の認識精度を大幅に向上させた。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
本研究では、音声認識モデルのWhisperとOCRモデルのDonutを統合した、エンドツーエンドのマルチモーダル音声認識モデル「Donut-Whisper」を提案し、映画の字幕などの視覚的なテキスト情報を活用することで、音声のみのモデルが苦手とするノイズ環境や未知語の認識精度を大幅に向上させた。
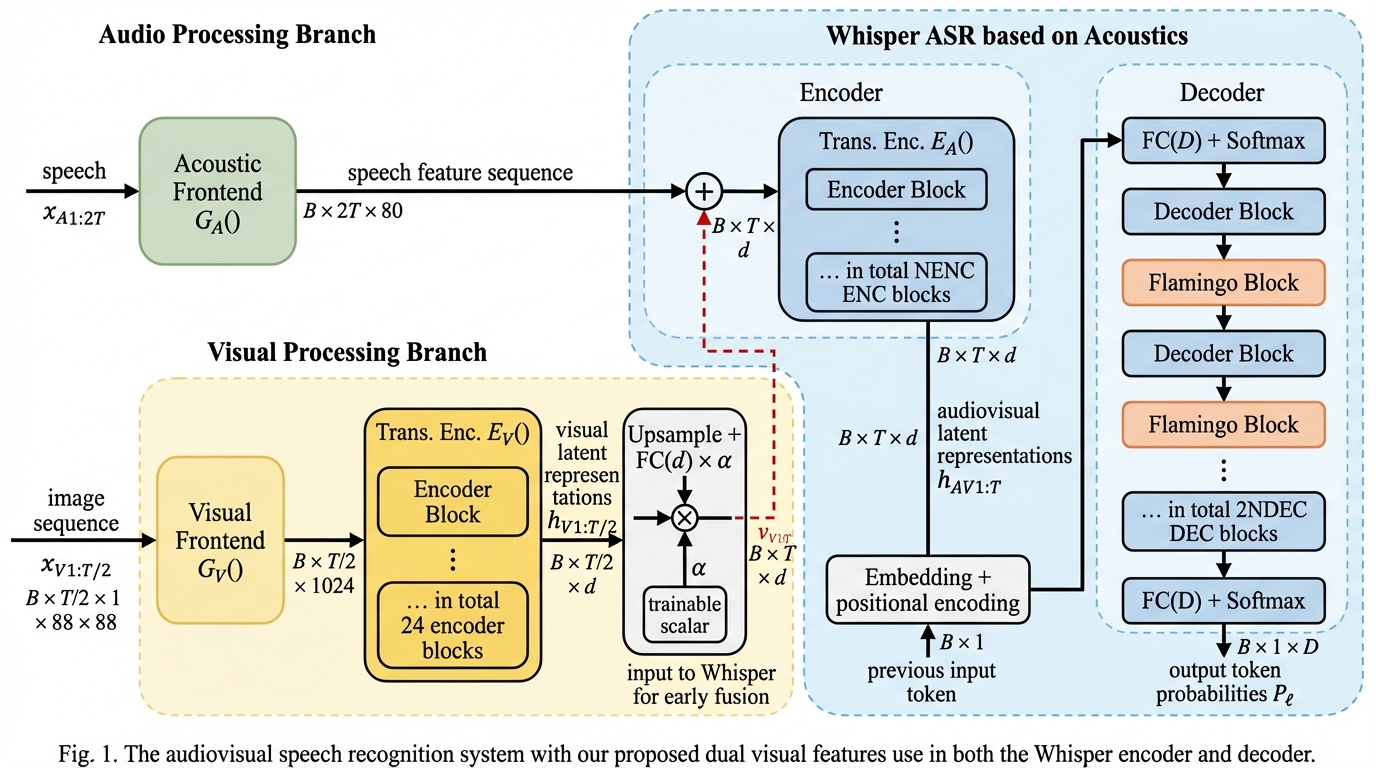
本研究は、Whisper ASRの騒音耐性を劇的に向上させるため、視覚的特徴量をエンコーダとデコーダの両方に統合する「デュアルユース」手法を提案し、従来の融合手法が抱えていた学習の不安定さや相互作用の欠如という課題を解決した。
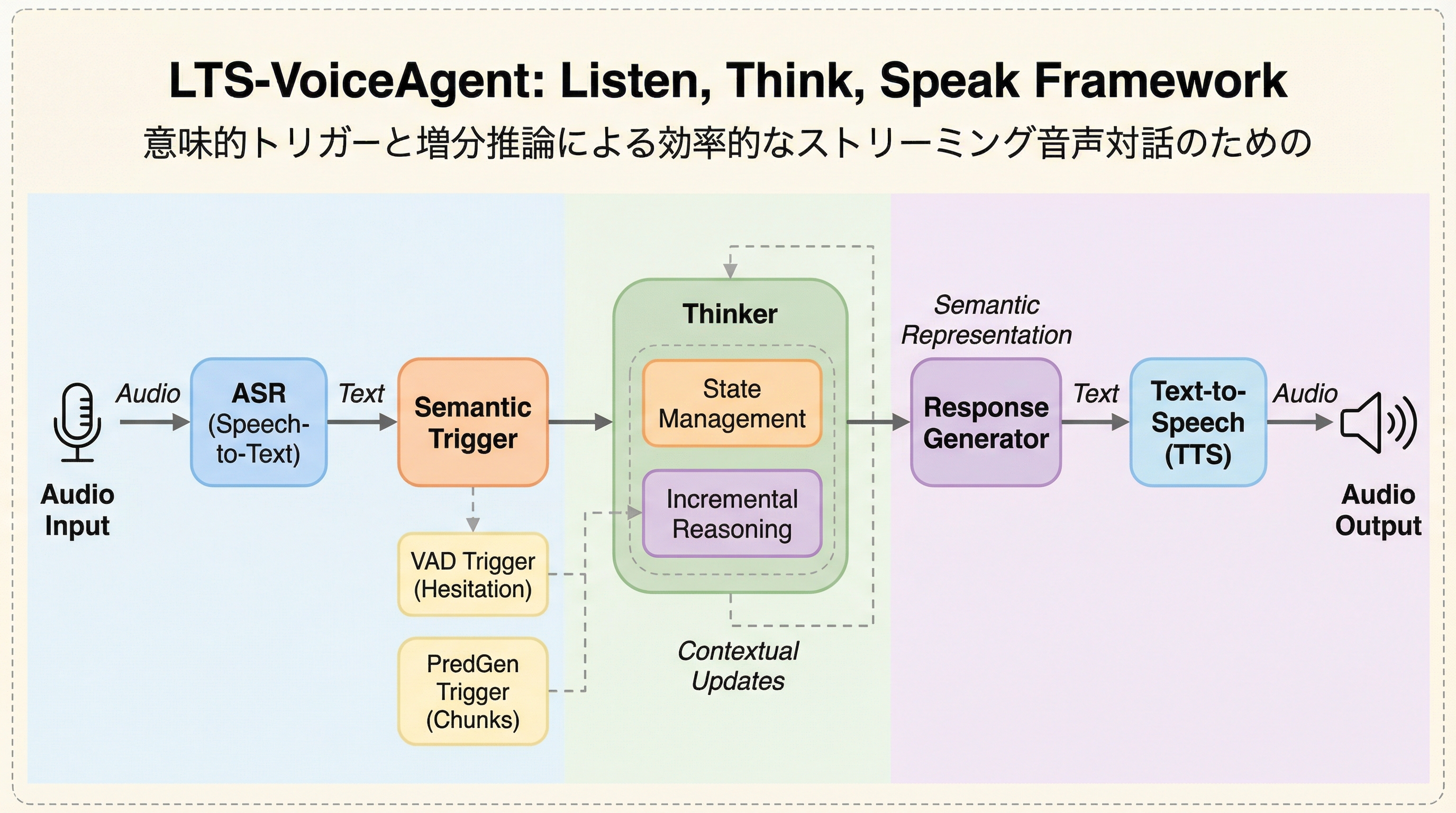
従来の音声エージェントが抱えていた「推論能力の不足」と「高い応答遅延」の二律背反を解消するため、意味の区切りを検知して思考を開始する「動的意味トリガー」と、思考と発話を並列化する「二重役割ストリームオーケストレーター」を導入したLTS-VoiceAgentフレームワークを提案しました。
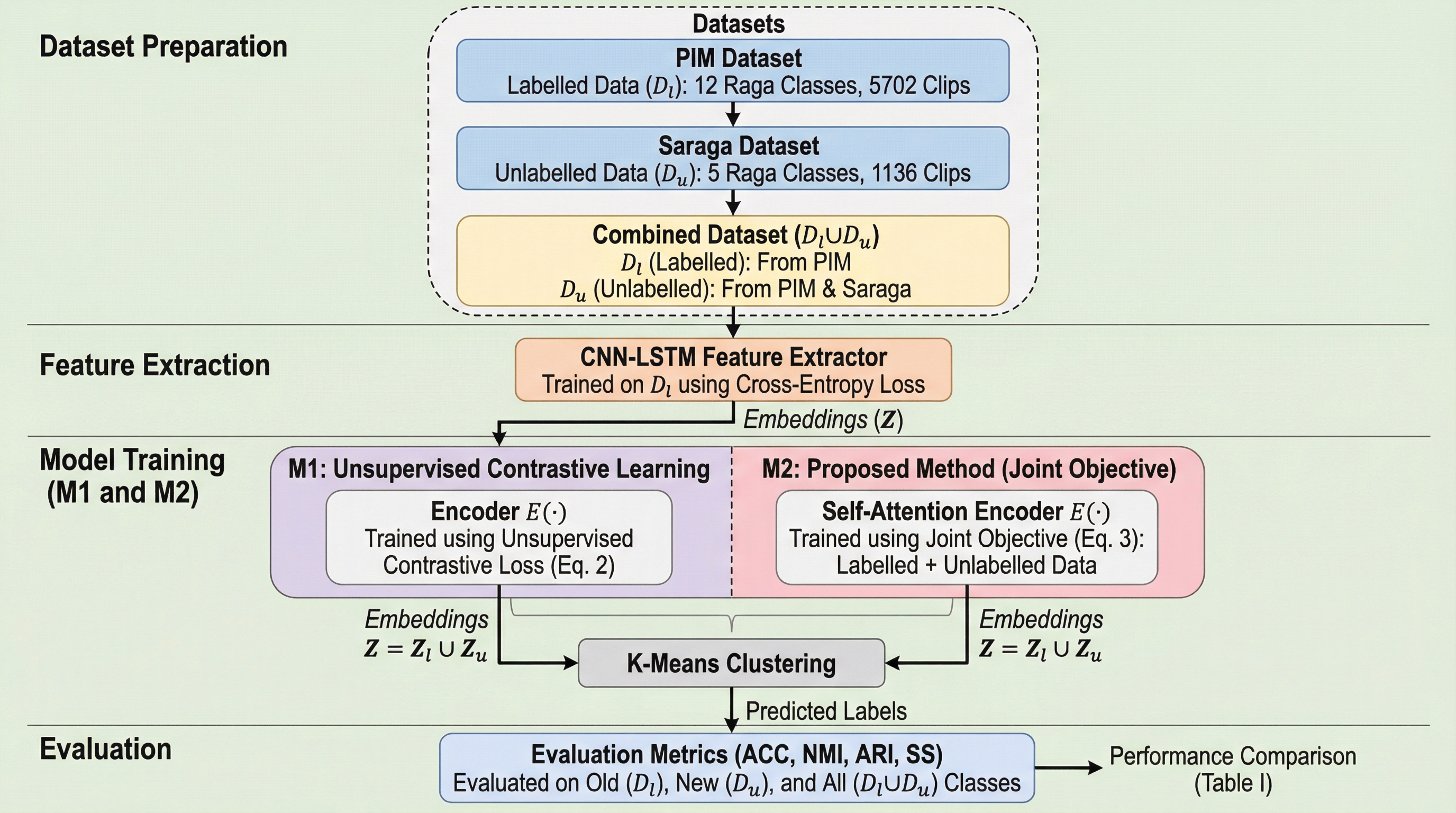
インド古典音楽のラーガ識別において、既知のラーガを正確に分類する能力を維持しながら、訓練データに含まれない未知のラーガを自動的に発見・構造化する「一般化カテゴリー発見(GCD)」フレームワークを提案した。
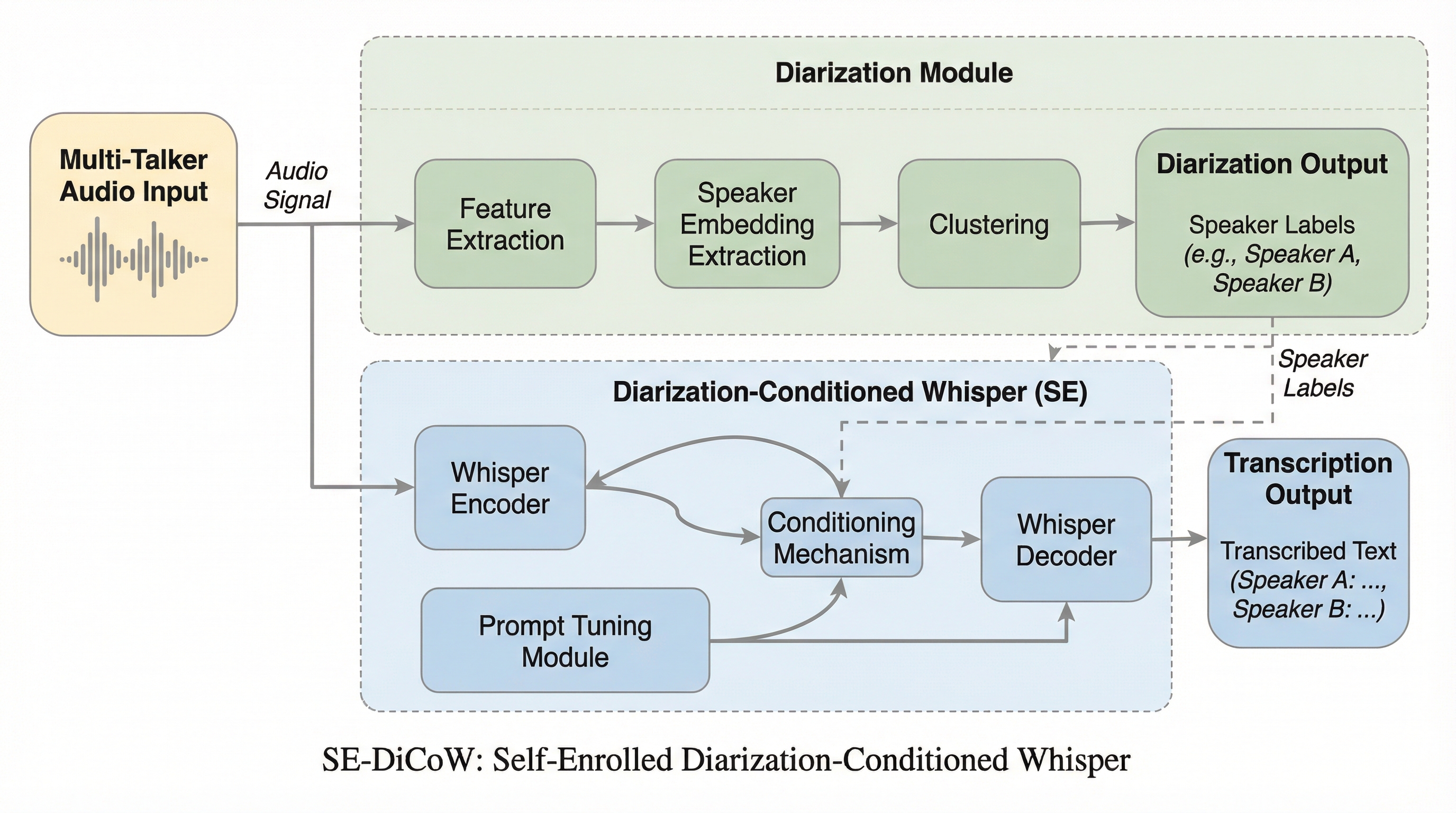
複数話者が同時に発話する環境において、従来の話者属性付き音声認識(ASR)は、話者が完全に重なる区間で情報の曖昧さが生じ、特定の話者を正確に識別することが困難でした。本研究で提案されたSE-DiCoWは、会話全体から対象話者が最も活発な区間を自動的に特定して「自己登録セグメント」として抽出し、クロスアテンション機構を通じてモデルに条件付けを行うことで、この根本的な問題を解決します。この革新的な自己登録メカニズムと学習プロセスの改善により、EMMA MT-ASRベンチマークにおいて従来モデルからエラー率を相対的に52.4%削減し、実環境のデータセットにおいても最先端の性能を達成することに成功しました。
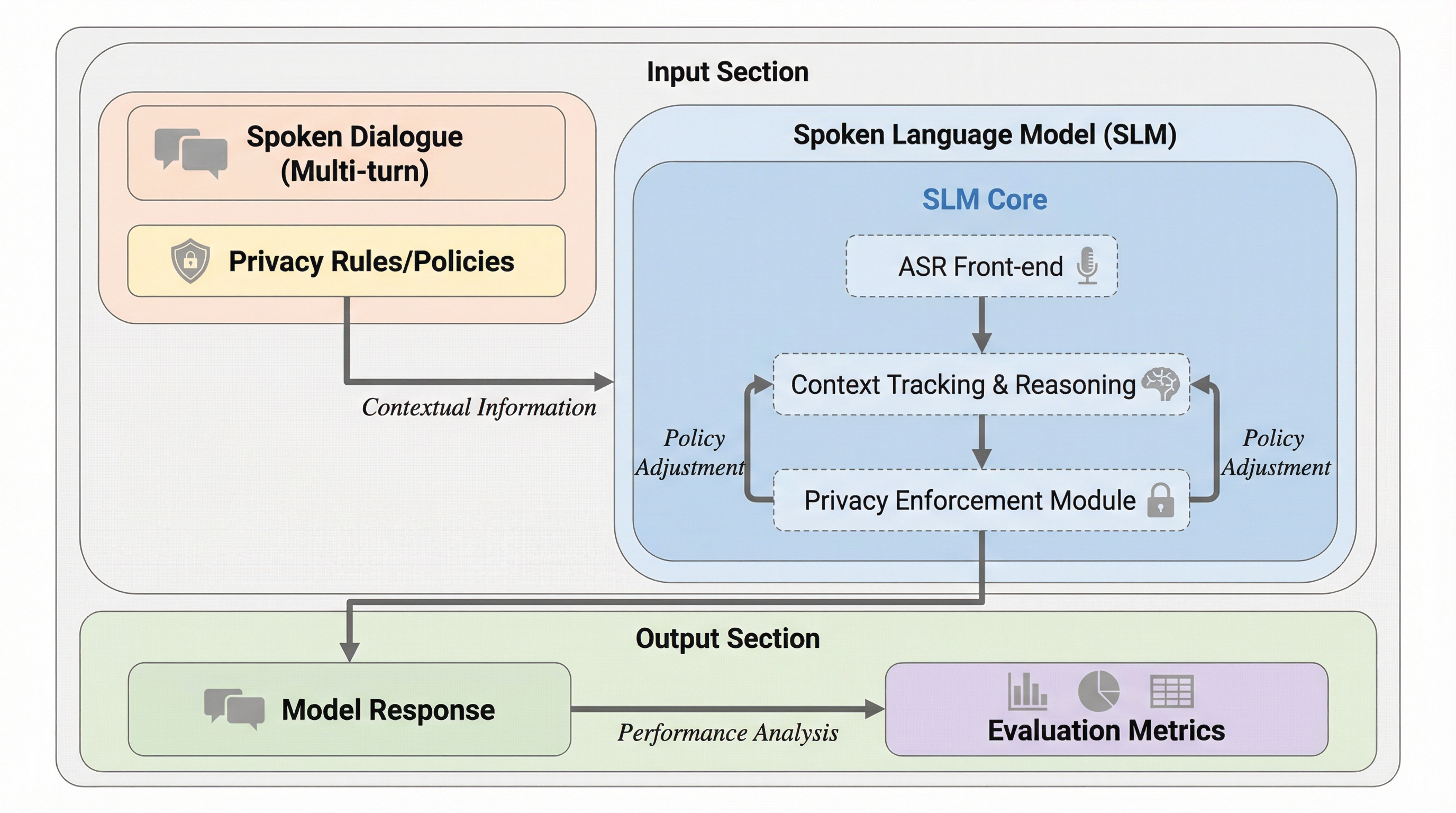
音声言語モデル(SLM)がスマートホーム等の共有環境で、特定の利用者の機密情報を他者に漏洩させる「対話的プライバシー」の欠如を評価するための専用ベンチマーク「VoxPrivacy」が提案された。
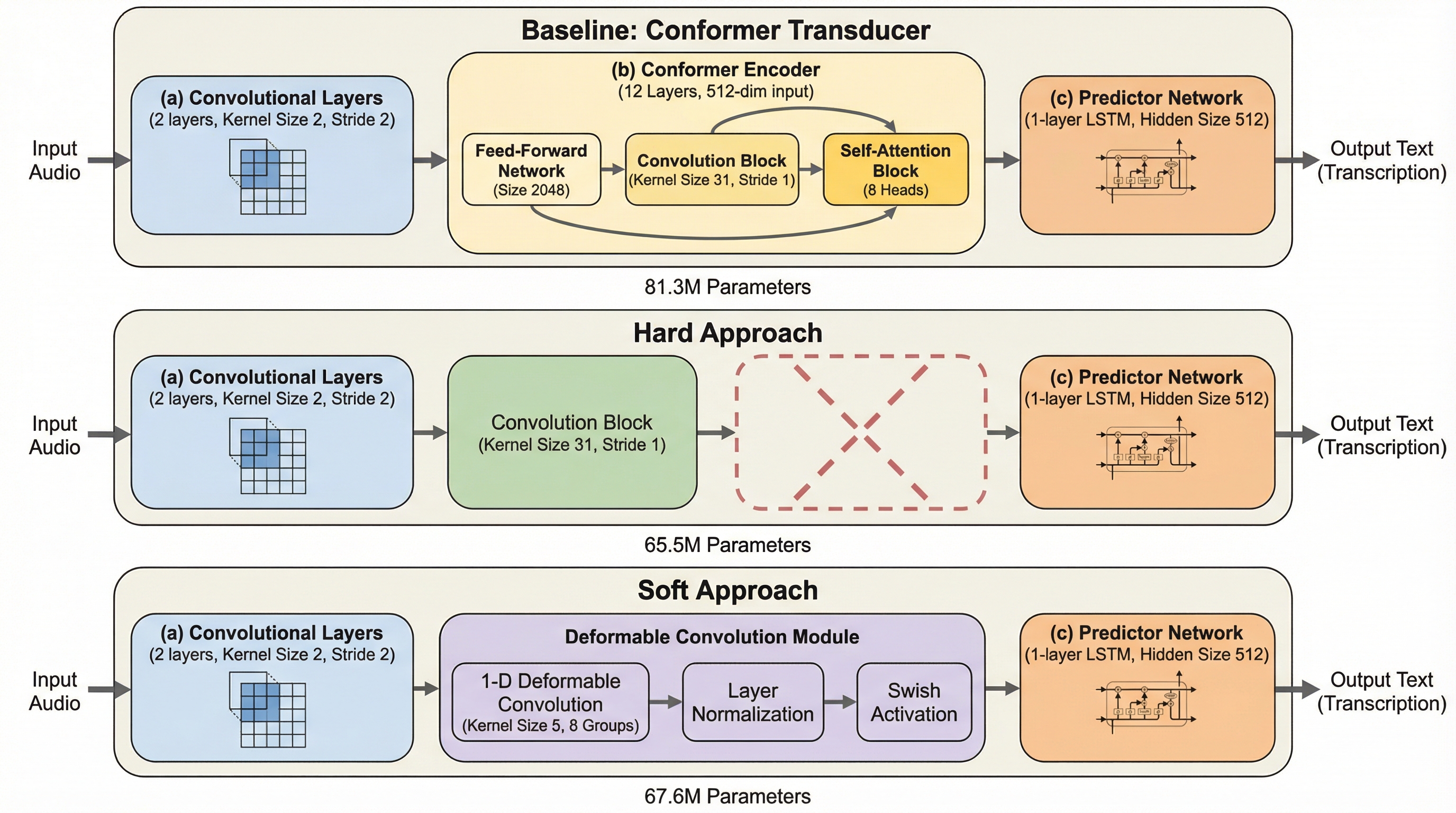
ストリーミング自動音声認識(ASR)において、Self-Attentionは全域的な依存関係を捉える設計でありながら、実際にはチャンク内の局所的な情報処理に終始していることが判明しました。 本研究では、Self-Attentionを軽量な可変形畳み込み(Deformable Convolution)に置き換える「ソフト手法」と、完全に削除する「ハード手法」を提案し、計算コストを大幅に削減しました。 LibriSpeech等のデータセットを用いた検証の結果、単語誤り率(WER)の悪化を最小限に抑えつつ、パラメータ数を最大19.4%削減し、GPU上での処理速度を約2倍に高速化することに成功しました。
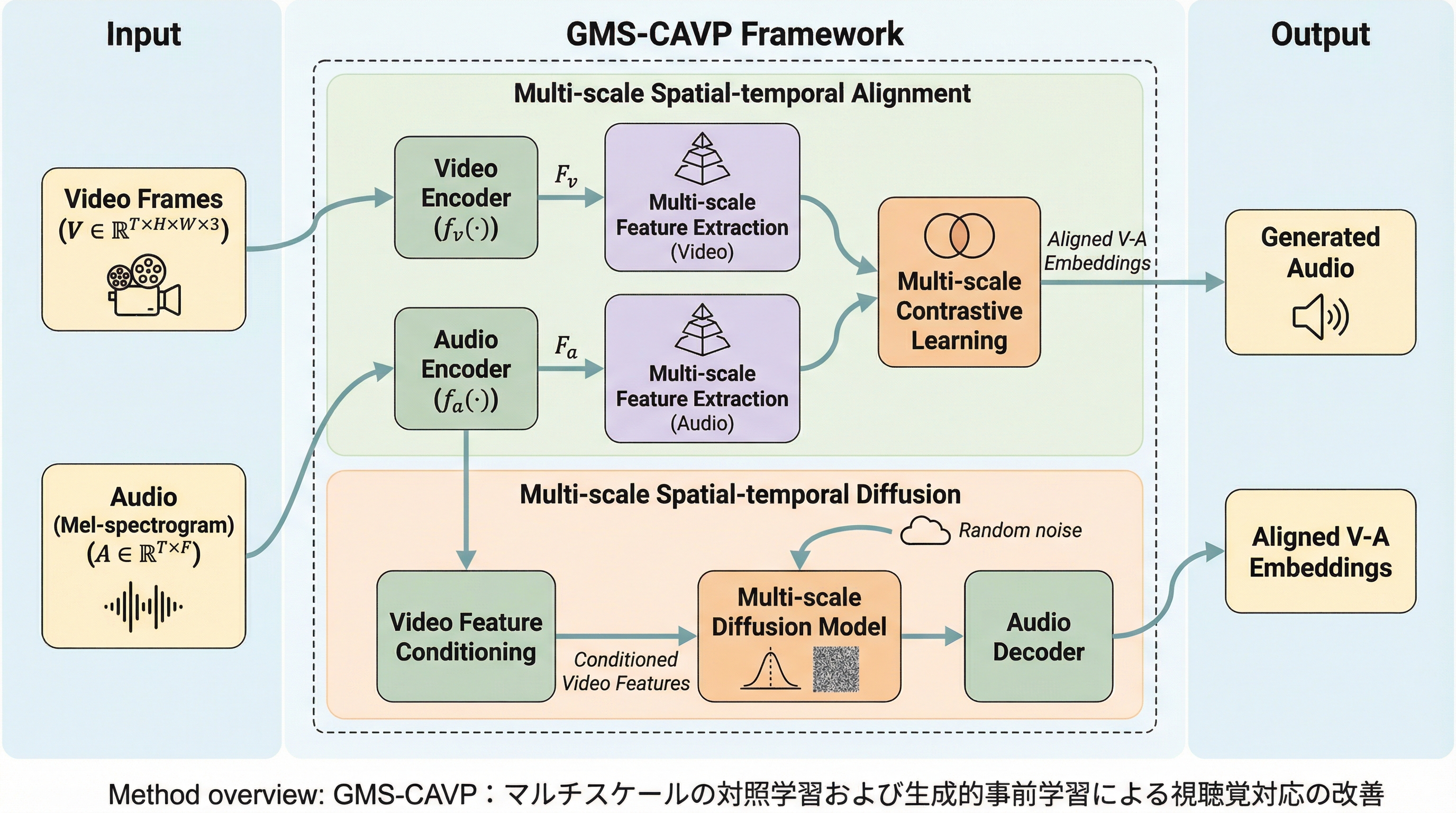
GMS-CAVPは、映像と音声の間の意味的・時間的な対応関係を高度にモデル化するため、マルチスケールでの対照学習と拡散モデルベースの生成学習を統合した新しい視聴覚事前学習フレームワークである。 従来の単一スケールによるグローバルな整列の限界を克服するため、階層的な空間・時間構造を捉える「マルチスケール空間・時間整列(MSA)」と、モダリティ間の翻訳能力を高める「マルチスケール空間・時間拡散(MSD)」を導入している。 VGGSound、AudioSet、Panda70Mを用いた大規模な実験において、映像からの音声生成および双方向検索の双方で従来手法を大幅に上回る世界最高水準の性能を達成し、高い同期性と音響品質を証明した。
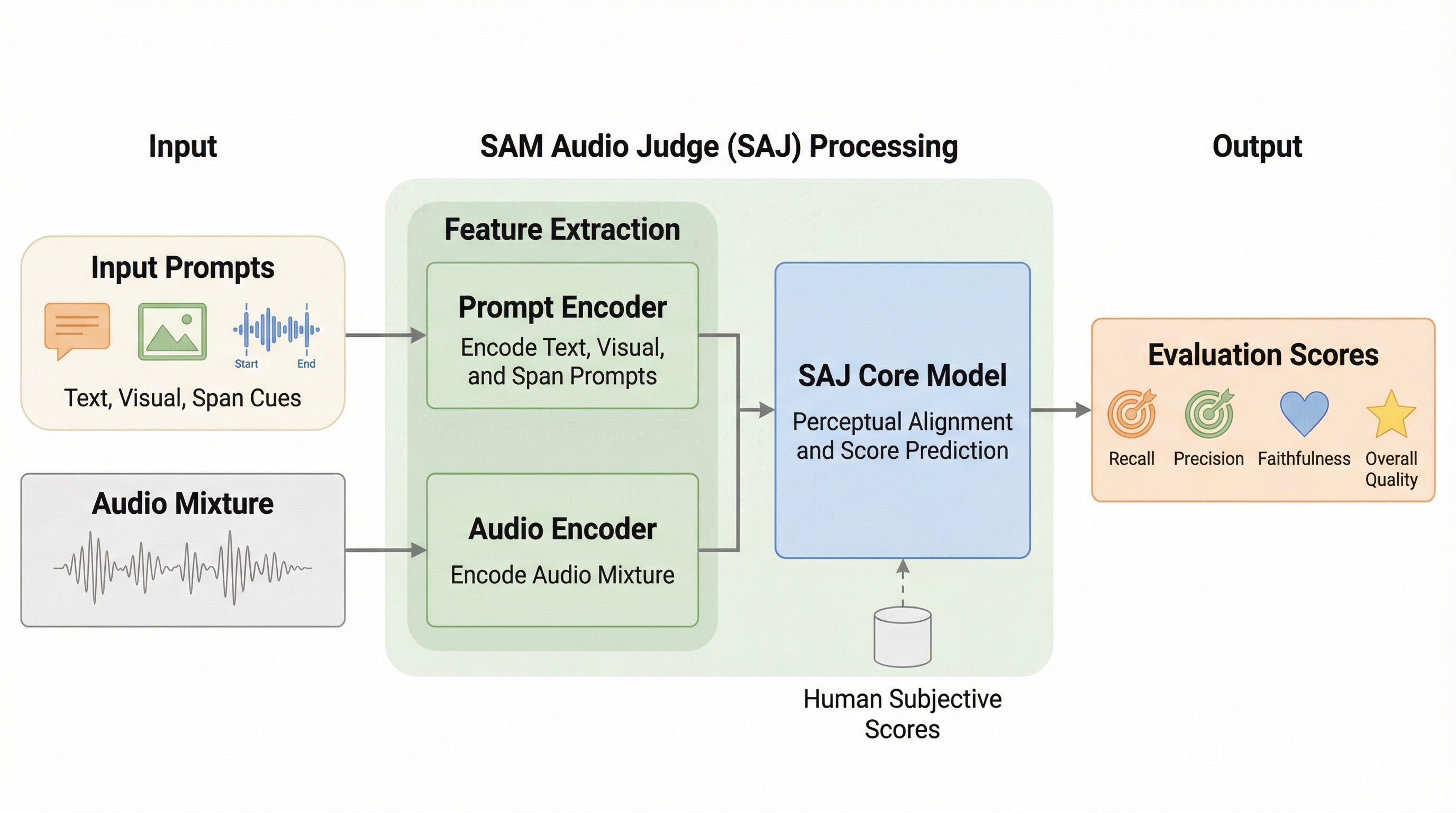
従来の音源分離評価で主流だったSDRなどの指標は、正解信号への依存や人間の知覚との乖離という大きな課題を抱えていましたが、本研究では正解信号を必要とせず、人間の知覚と高度に一致する新しい客観的評価指標「SAM Audio Judge(SAJ)」を開発しました。
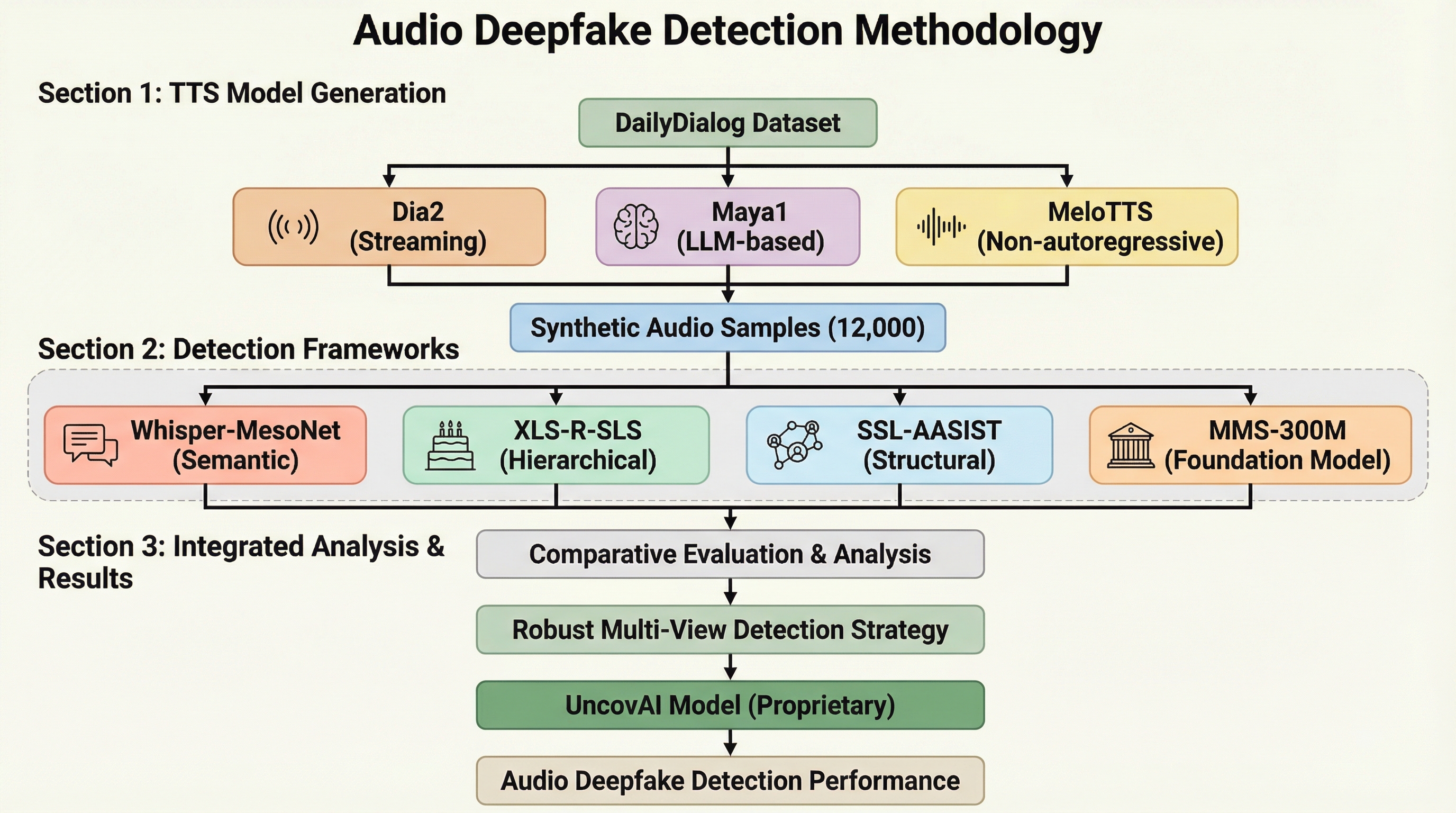
最新のText-to-Speech(TTS)技術であるDia2、Maya1、MeloTTSは、大規模言語モデルやフローマッチング、階層型コーデックを採用することで、従来の検出器では識別が困難な極めて自然な音声を生成する。