ストリーミング自動音声認識にSelf-Attentionは本当に必要なのか?
ストリーミング自動音声認識(ASR)において、Self-Attentionは全域的な依存関係を捉える設計でありながら、実際にはチャンク内の局所的な情報処理に終始していることが判明しました。 本研究では、Self-Attentionを軽量な可変形畳み込み(Deformable Convolution)に置き換える「ソフト手法」と、完全に削除する「ハード手法」を提案し、計算コストを大幅に削減しました。 LibriSpeech等のデータセットを用いた検証の結果、単語誤り率(WER)の悪化を最小限に抑えつつ、パラメータ数を最大19.4%削減し、GPU上での処理速度を約2倍に高速化することに成功しました。
TL;DR(結論)
ストリーミング自動音声認識(ASR)において、Self-Attentionは全域的な依存関係を捉える設計でありながら、実際にはチャンク内の局所的な情報処理に終始していることが判明しました。 本研究では、Self-Attentionを軽量な可変形畳み込み(Deformable Convolution)に置き換える「ソフト手法」と、完全に削除する「ハード手法」を提案し、計算コストを大幅に削減しました。 LibriSpeech等のデータセットを用いた検証の結果、単語誤り率(WER)の悪化を最小限に抑えつつ、パラメータ数を最大19.4%削減し、GPU上での処理速度を約2倍に高速化することに成功しました。
なぜこの問題か
深層学習の多くの分野において、Transformerベースのアーキテクチャは自然言語処理(NLP)やコンピュータビジョン、音声処理のデファクトスタンダードとなっています。 特に音声認識の分野では、広範囲の依存関係を捉えるSelf-Attentionモジュールと、局所的なパターンを抽出する畳み込みモジュールを組み合わせたConformerが、最先端の性能(SOTA)を達成してきました。 しかし、このような成功体験に基づき、制約の多い特定のタスクに対してもTransformer構造をそのまま適用することが一般的になっていますが、それが常に最適であるかどうかは十分に検証されていませんでした。 ストリーミング自動音声認識(ASR)は、入力された音声の全容を待たずに逐次テキスト化を行う必要があり、計算量と遅延(レイテンシ)に対して非常に厳しい制約が課されるタスクです。 ストリーミング環境では、音声データは「チャンク」と呼ばれる短い断片ごとに処理されるため、モデルが一度に参照できる文脈の範囲は極めて限定的になります。…
核心:何を提案したのか
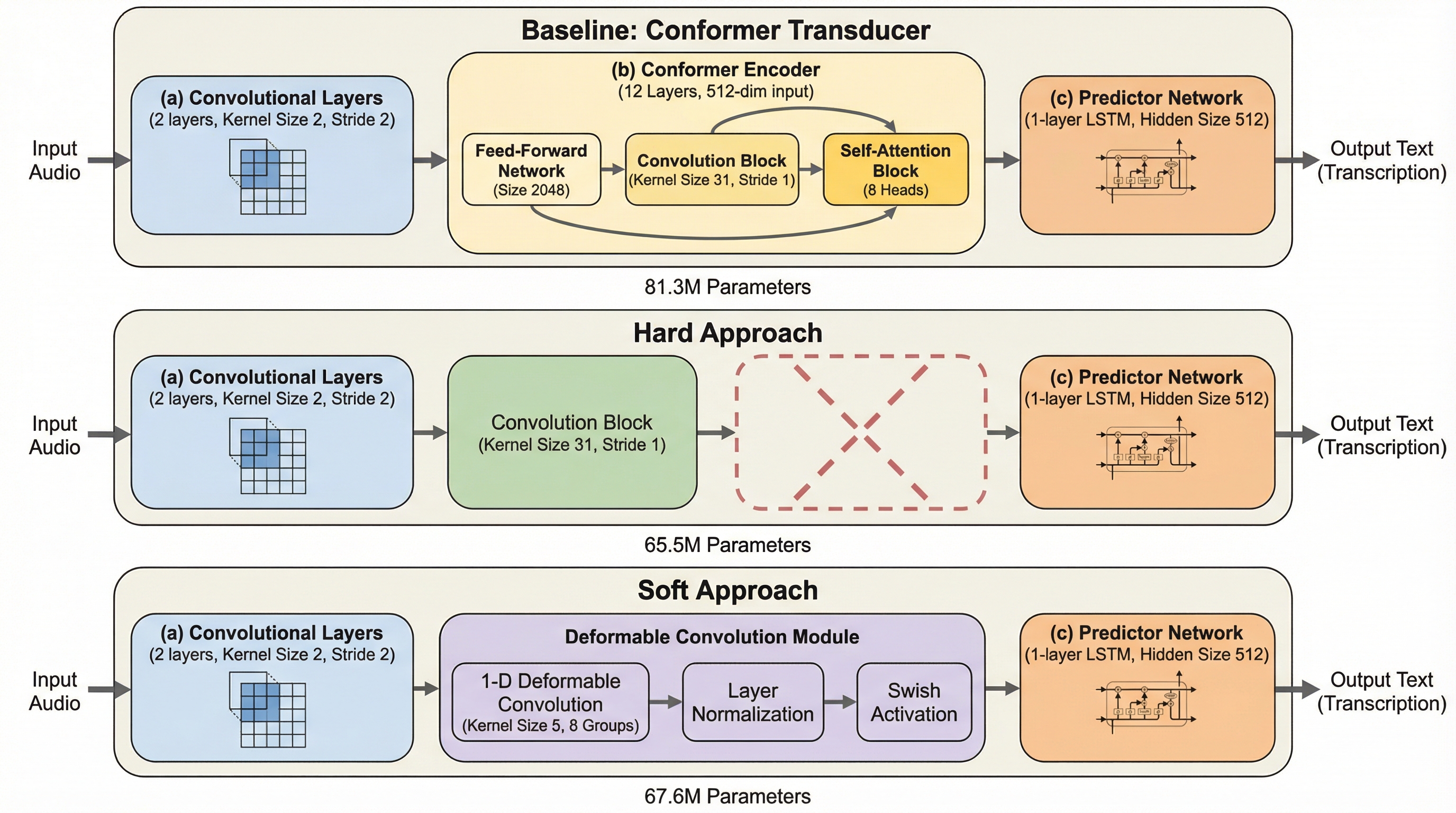
本研究では、まず厳格なストリーミング設定下でのConformerエンコーダ内のSelf-Attentionの挙動を詳細に分析しました。 12層のConformerエンコーダにおいて、各層の平均アテンションマップを可視化したところ、重みが対角線付近に集中していることが明らかになりました。 これは、Self-Attentionが本来の目的である長距離の依存関係ではなく、畳み込みモジュールが得意とするような短距離の依存関係のみを捉えていることを示唆しています。 この分析に基づき、著者らはSelf-Attentionをより軽量で効率的なモジュールに置き換える、あるいは排除する2つのアプローチを提案しました。 第一の「ソフト手法(Soft Approach)」は、Self-Attentionを1次元の可変形畳み込み(1-D Deformable Convolution)モジュールに置き換える手法です。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related