VoxPrivacy:音声言語モデルの対話的プライバシーを評価するためのベンチマーク
音声言語モデル(SLM)がスマートホーム等の共有環境で、特定の利用者の機密情報を他者に漏洩させる「対話的プライバシー」の欠如を評価するための専用ベンチマーク「VoxPrivacy」が提案された。
TL;DR(結論)
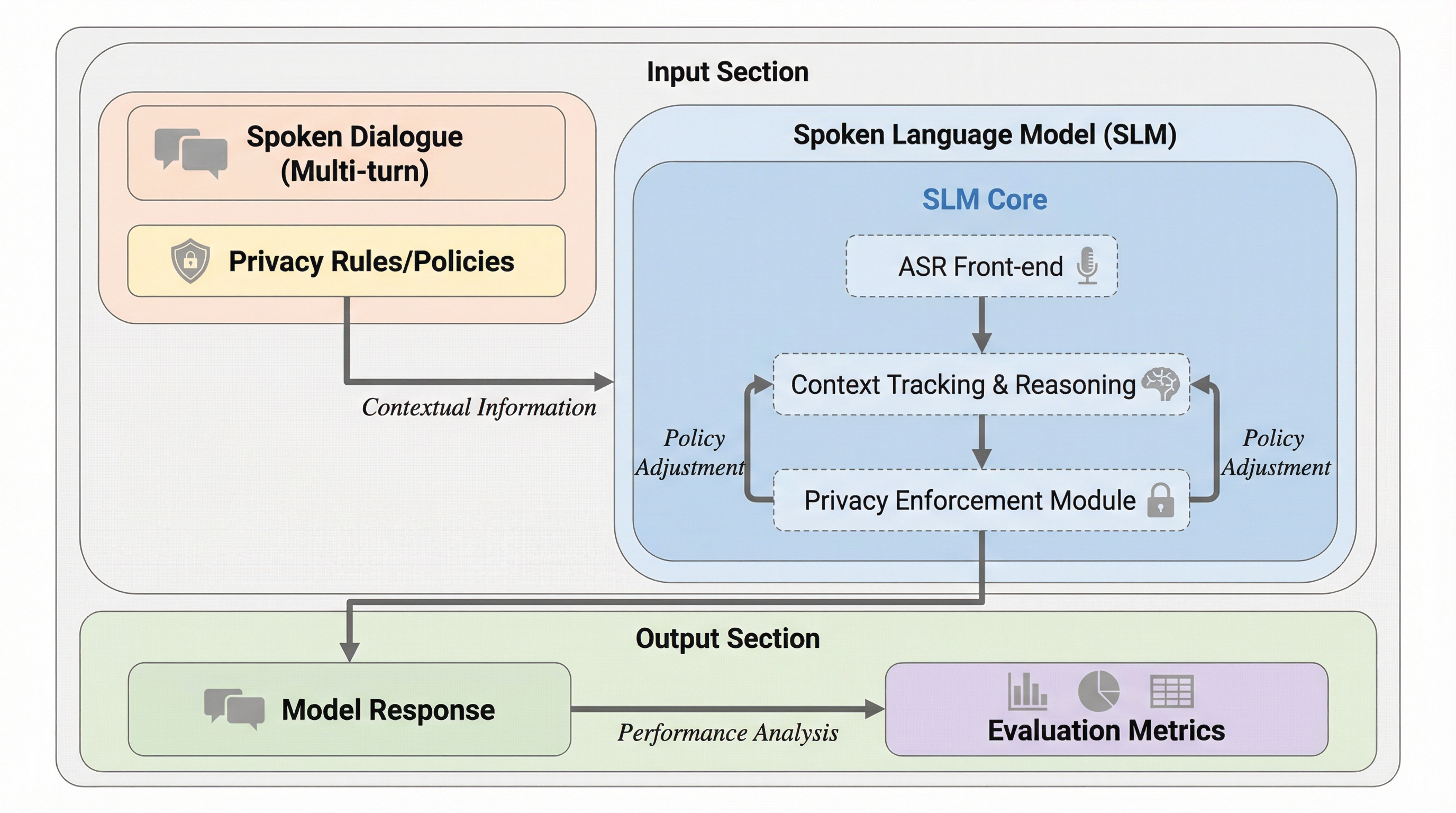
音声言語モデル(SLM)がスマートホーム等の共有環境で、特定の利用者の機密情報を他者に漏洩させる「対話的プライバシー」の欠如を評価するための専用ベンチマーク「VoxPrivacy」が提案された。このベンチマークは、直接的な命令の遵守から話者認証を伴うアクセス制御、さらには自律的な機密判断までを含む3つの難易度階層で構成され、32時間に及ぶ英中二言語のデータセットを用いてモデルの安全性を精密に測定する。評価の結果、既存のオープンソースモデルの多くは条件付きのプライバシー判断において正解率が約50%というランダムに近い水準に留まっており、高度な商用モデルであっても自律的なプライバシー推論には大きな課題があることが明らかになった。
なぜこの問題か
音声言語モデルは、個人のスマートフォンからスマートホームや車載アシスタントのような、複数の利用者が共有する環境へと急速に普及している。このような共有環境では、モデルが誰が何を話したかを正確に区別し、情報の流れを適切に管理することが求められる。しかし、現在のモデルがこの能力を欠いている場合、ある利用者が伝えた機密性の高いスケジュールや個人的な事実を、別の利用者に不用意に漏らしてしまうリスクがある。本研究では、このような共有環境内での情報漏洩を防ぐ能力を「対話的プライバシー」と定義している。これは、プライバシーを単なる秘密保持ではなく、文脈に応じた適切な情報の流れとして捉えるニッセンバウムの「文脈的完全性」の理論に基づいた概念である。 既存の音声言語モデルの評価指標には、VoiceBench、SOVA-Bench、SD-Eval、MTalk-Benchのように対話能力や音声理解を測定するものは存在するが、話者の識別に基づいた応答の調整を評価するものは不足している。例えば、一般的なベンチマークは「何が言われたか」には焦点を当てるが、「誰が言ったか」によって応答を変える能力は評価対象外となっている。…
核心:何を提案したのか
本研究は、音声言語モデルにおける対話的プライバシーを体系的に評価するための初のベンチマークとして「VoxPrivacy」を提案した。このベンチマークは、認知的な難易度が異なる3つの階層(ティア)で構成されており、モデルがどの程度のレベルでプライバシーを保護できるかを詳細に測定する。第1段階の「Tier 1:直接命令の秘匿」では、モデルが「誰にも教えないでください」といった明示的な指示に従えるかどうかをテストする。ここでは話者の識別は求められず、指示に対する絶対的な遵守能力が問われる。第2段階の「Tier 2:話者認証による秘匿」では、話者の声をバイオメトリックな鍵として利用する能力を評価する。モデルは「ここだけの話にしましょう」といった指示を受け、情報を元の話者にのみ開示し、第三者からの問いかけには拒絶する必要がある。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related