SE-DiCoW:自己登録型ダイアライゼーション条件付きWhisper
複数話者が同時に発話する環境において、従来の話者属性付き音声認識(ASR)は、話者が完全に重なる区間で情報の曖昧さが生じ、特定の話者を正確に識別することが困難でした。本研究で提案されたSE-DiCoWは、会話全体から対象話者が最も活発な区間を自動的に特定して「自己登録セグメント」として抽出し、クロスアテンション機構を通じてモデルに条件付けを行うことで、この根本的な問題を解決します。この革新的な自己登録メカニズムと学習プロセスの改善により、EMMA MT-ASRベンチマークにおいて従来モデルからエラー率を相対的に52.4%削減し、実環境のデータセットにおいても最先端の性能を達成することに成功しました。
TL;DR(結論)
複数話者が同時に発話する環境において、従来の話者属性付き音声認識(ASR)は、話者が完全に重なる区間で情報の曖昧さが生じ、特定の話者を正確に識別することが困難でした。本研究で提案されたSE-DiCoWは、会話全体から対象話者が最も活発な区間を自動的に特定して「自己登録セグメント」として抽出し、クロスアテンション機構を通じてモデルに条件付けを行うことで、この根本的な問題を解決します。この革新的な自己登録メカニズムと学習プロセスの改善により、EMMA MT-ASRベンチマークにおいて従来モデルからエラー率を相対的に52.4%削減し、実環境のデータセットにおいても最先端の性能を達成することに成功しました。
なぜこの問題か
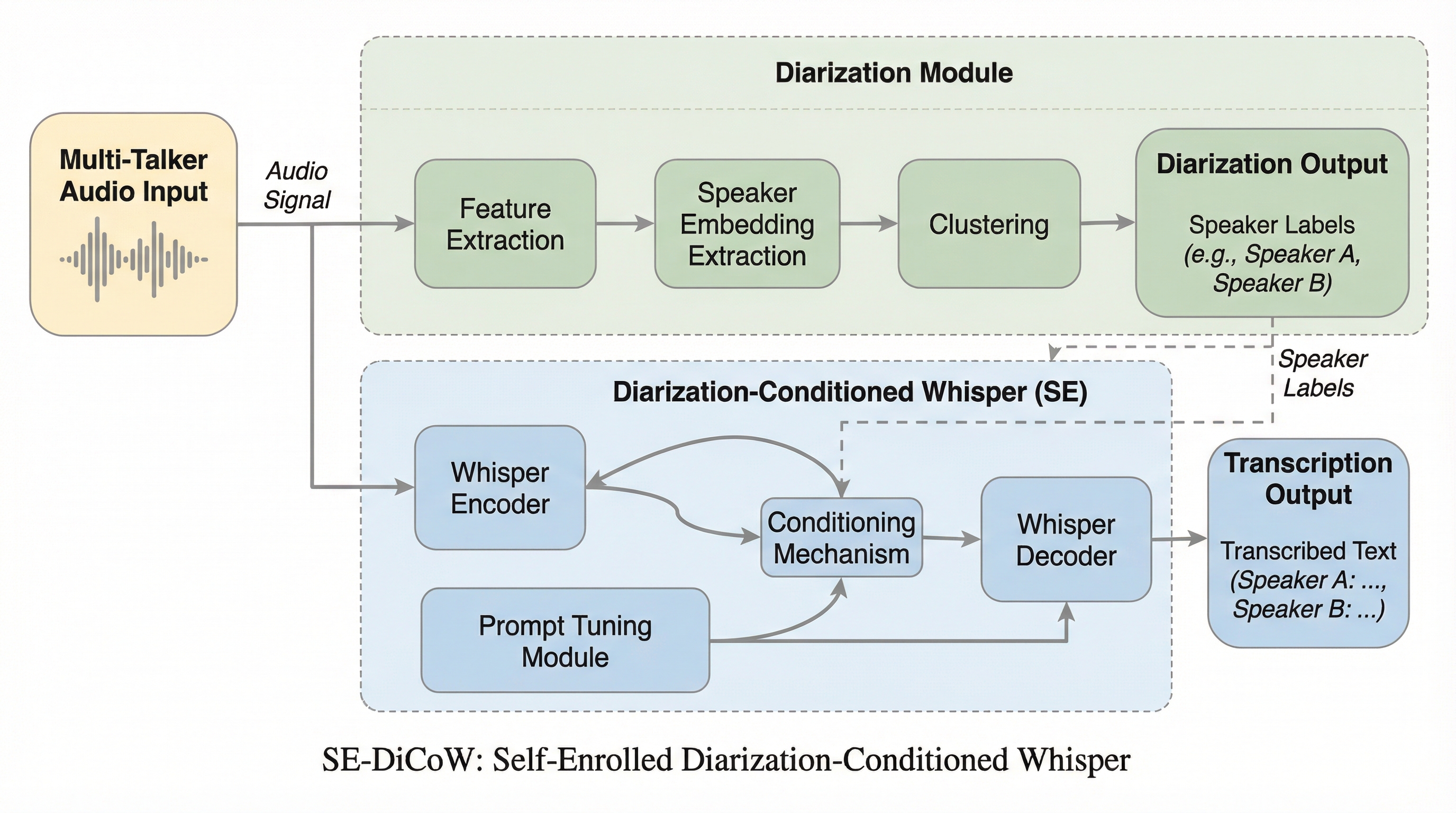
会議やインタビュー、日常的な多人数会話などの複雑な音響環境において、音声認識システムには単に言葉をテキスト化するだけでなく、「誰が何を話したか」を正確に記録する話者属性付き音声認識(ASR)の能力が強く求められています。しかし、現実の会話では複数の話者が同時に話す「重なり発話」が頻繁に発生し、これが現在の技術における大きな壁となっています。既存の単一話者向け音声認識モデルは、こうした重なりや自然な対話の構造に対して脆弱であり、話者の特定に失敗したり、複数の声を混同して誤認識を引き起こしたりします。 特に、先行研究であるDiCoW(Diarization-Conditioned Whisper)は、話者ダイアライゼーションの結果を条件付け情報として利用することで、最小限の微調整で高い多言語・多ドメイン性能を示してきました。しかし、DiCoWには「静止・対象・非対象・重複(STNO)マスク」の曖昧さという致命的な限界がありました。これは、2人以上の話者が完全に重なっている場合に、書き起こすべき内容が異なるにもかかわらず、モデルに与えられる条件付け情報がほぼ同一になってしまうという問題です。…
核心:何を提案したのか
本論文では、DiCoWの主要な限界を克服するために、自己登録型ダイアライゼーション条件付きWhisperである「SE-DiCoW(Self-Enrolled Diarization-Conditioned Whisper)」を提案します。この手法の核心は、外部から事前に用意された話者の登録音声(エンロールメント)を必要とせず、処理対象の会話そのものの中から最適な参照区間を自動的に見つけ出し、それを条件付け情報として利用する「自己登録メカニズム」にあります。 具体的には、ダイアライゼーションの出力を用いて、会話内のどこからでも対象話者が最も活発に話している(他の話者の干渉が少ない、あるいは対象話者の特徴が明確な)区間を「登録セグメント」として特定します。このセグメントは、エンコーダーの各層においてクロスアテンション機構を介し、固定された条件付け情報としてモデルに注入されます。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related