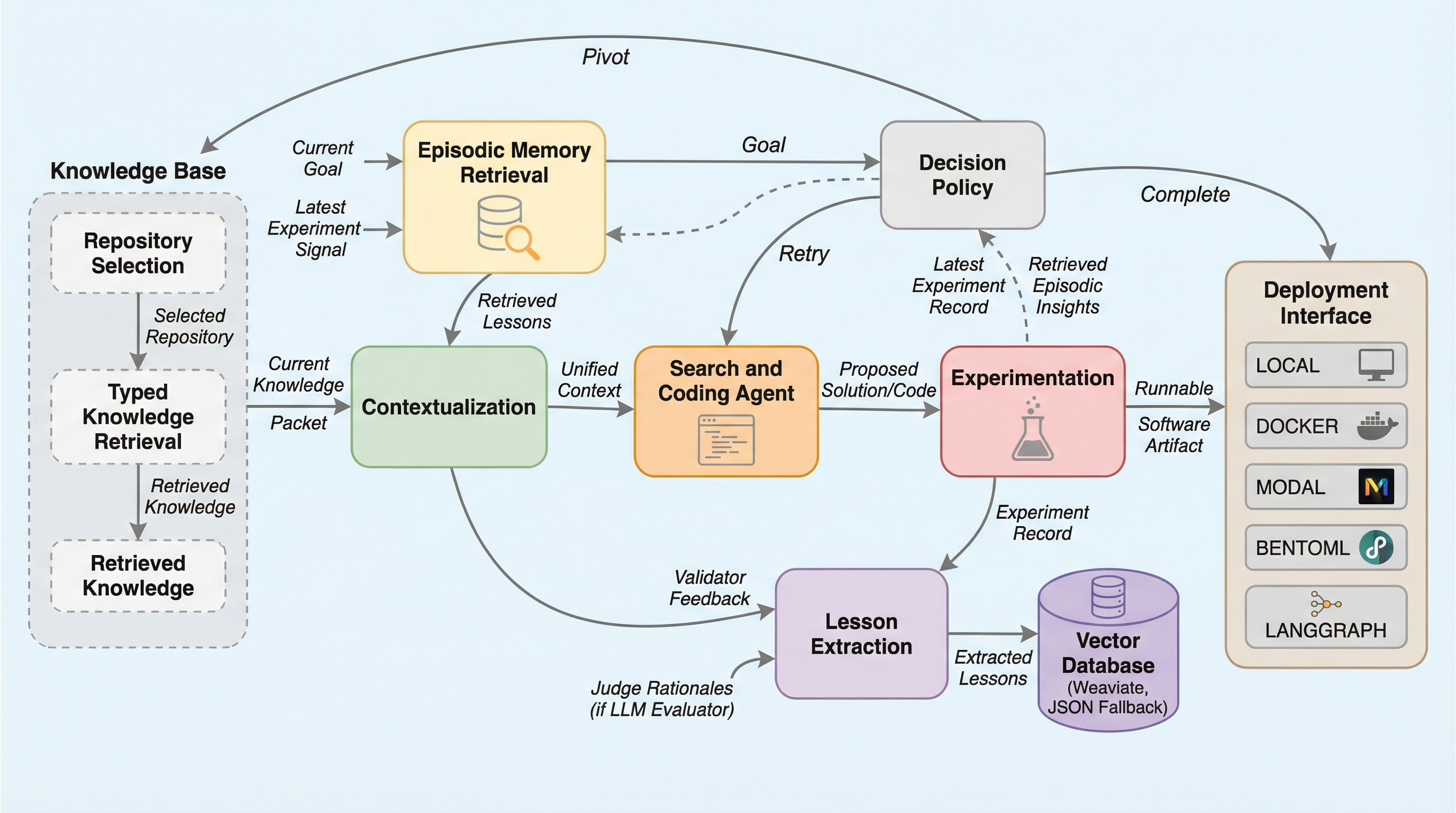
KAPSO: 知識に基づいた自律的なプログラム合成と最適化のためのフレームワーク
KAPSOは、自然言語の目標と評価方法を入力として、プログラムの着想、合成、実行、評価、学習のサイクルを自律的に繰り返すモジュール式のフレームワークであり、プログラム合成を単なるコード生成の終着点ではなく、測定可能な目標に向けた継続的な最適化プロセスとして再定義している。
最新の論文記事を読みやすく整理。保存・タグ検索に加え、Plus/Proでは研究ノートと知識グラフで理解を積み上げられます。
Cog AI Archive
KAPSOは、自然言語の目標と評価方法を入力として、プログラムの着想、合成、実行、評価、学習のサイクルを自律的に繰り返すモジュール式のフレームワークであり、プログラム合成を単なるコード生成の終着点ではなく、測定可能な目標に向けた継続的な最適化プロセスとして再定義している。
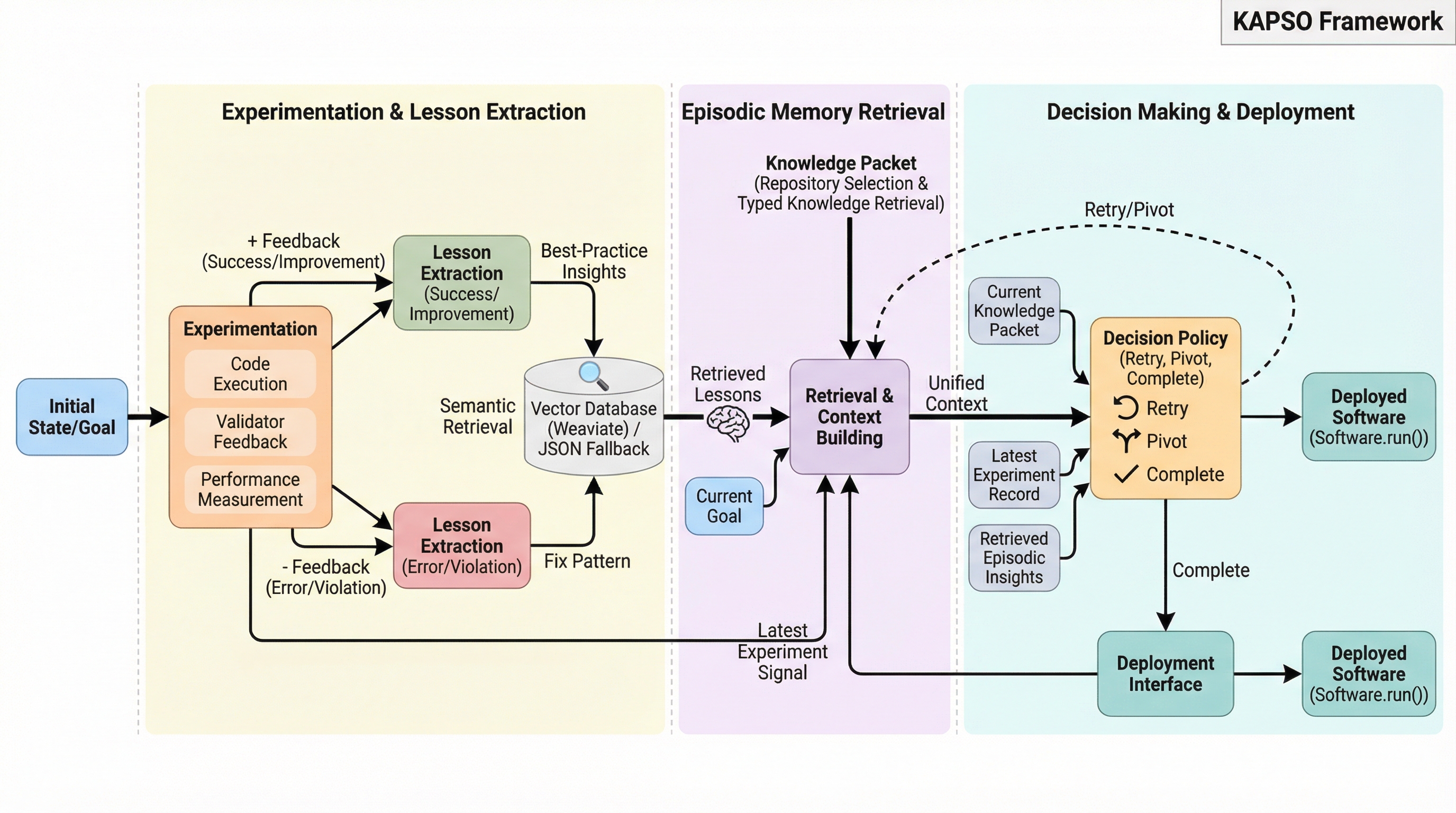
KAPSOは、自然言語の目標と評価方法を入力として、アイデア生成、コード合成、実行、評価、学習を繰り返すことで、測定可能な目標に向けて成果物を自律的に改善し続けるモジュール型フレームワークである。
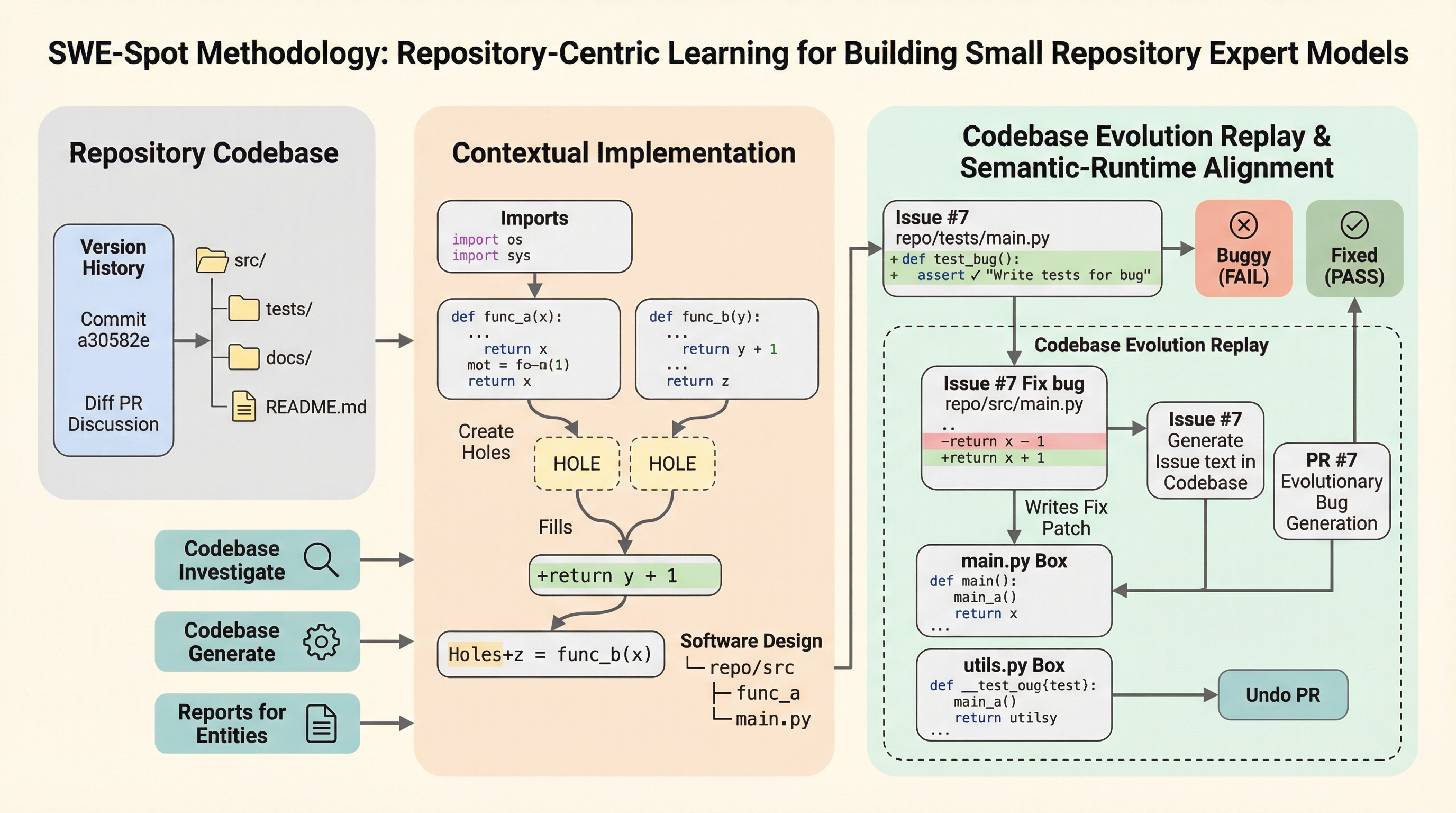
従来のタスク中心学習では、小規模言語モデルが複雑なコードベースの推論時に十分な汎化性能を発揮できず、表面的なパターンの学習に留まるという課題がありました。 本研究は、特定のコードベースに対する垂直的な深さを優先する「リポジトリ中心学習(RCL)」を提案し、静的なコードを対話的な学習信号に変換する4つの経験ユニットを設計しました。 この手法で構築された4BパラメータのSWE-SPOTは、8倍大きなオープンモデルや商用モデルに匹敵する性能を、高いサンプル効率と低い推論コストで実現することに成功しました。
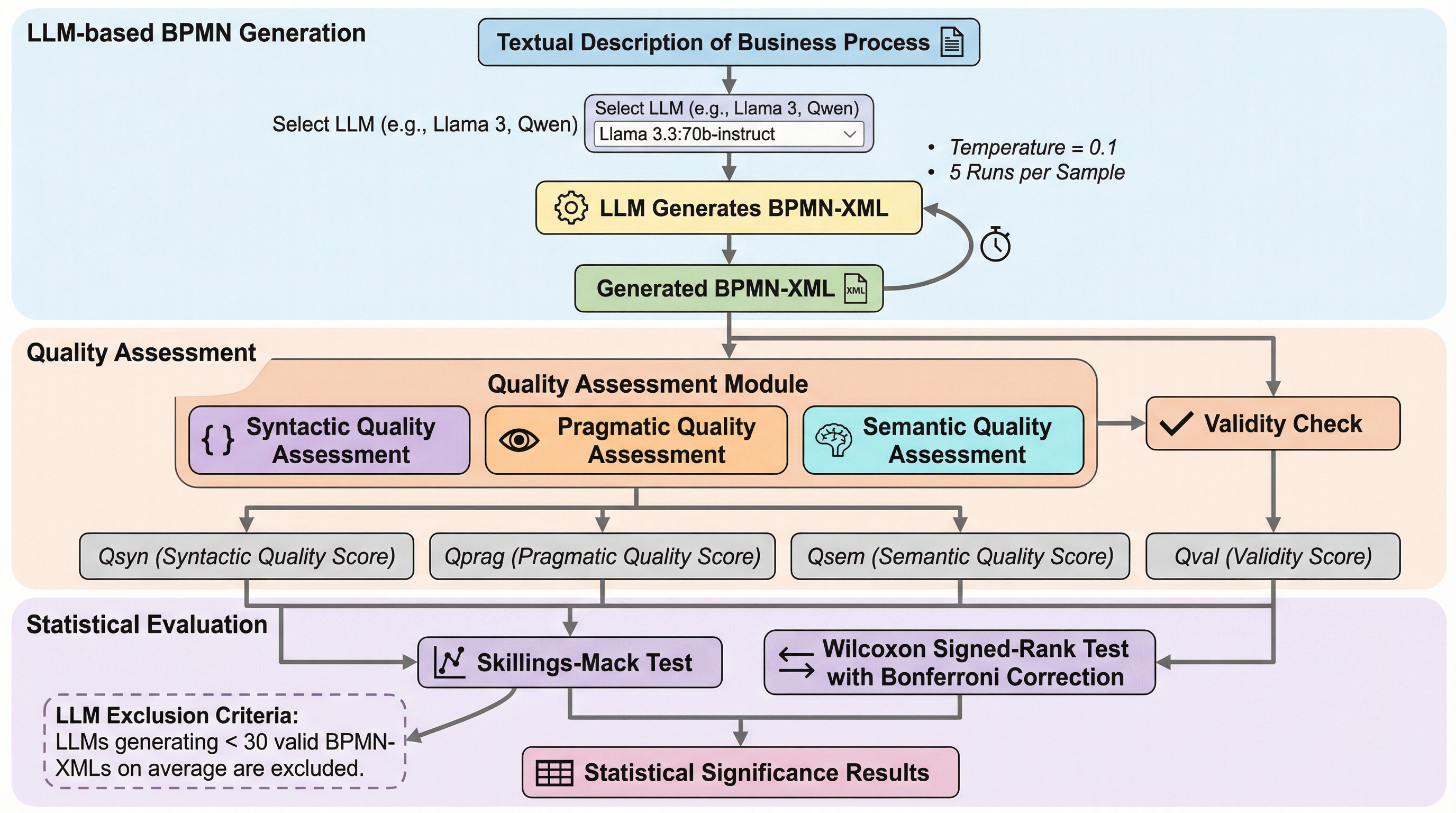
ビジネスプロセスモデリング(BPMN)における大規模言語モデル(LLM)の能力を客観的に評価するため、39個の指標を用いた新しい評価フレームワーク「BEF4LLM」が開発されました。17種類のオープンソースLLMを対象とした大規模なベンチマーク調査により、LLMは構文や実用性の面で優れた成果を出す一方で、意味論的な正確性や有効なXML形式の生成には依然として課題があることが判明しました。特に、モデルの規模が必ずしもモデリング品質の向上に直結しないという結果は、今後のLLMの選択や特定のタスクに向けた微調整において、パラメータ数以外の要素を重視すべきであることを示唆しており、LLMが専門家と同等のモデルを作成できる可能性を示しつつ、実用化に向けた具体的な改善点を明確にしました。
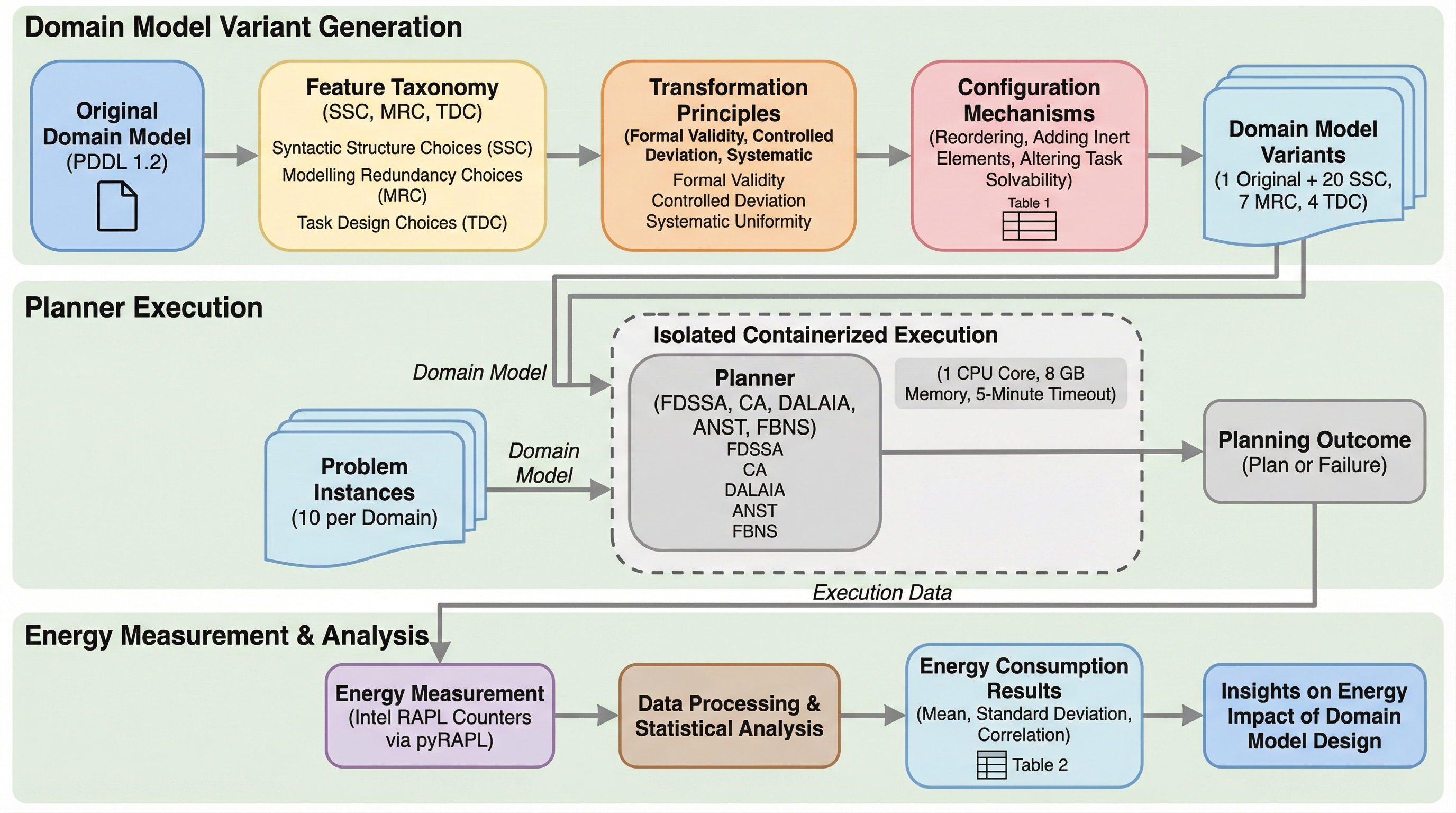
AI計画法において、アルゴリズムとは独立して定義されるドメインモデルの設計が、システムの消費エネルギーに極めて大きな影響を及ぼすことを、5つのプランナーと5つのベンチマークを用いた実験により明らかにした。
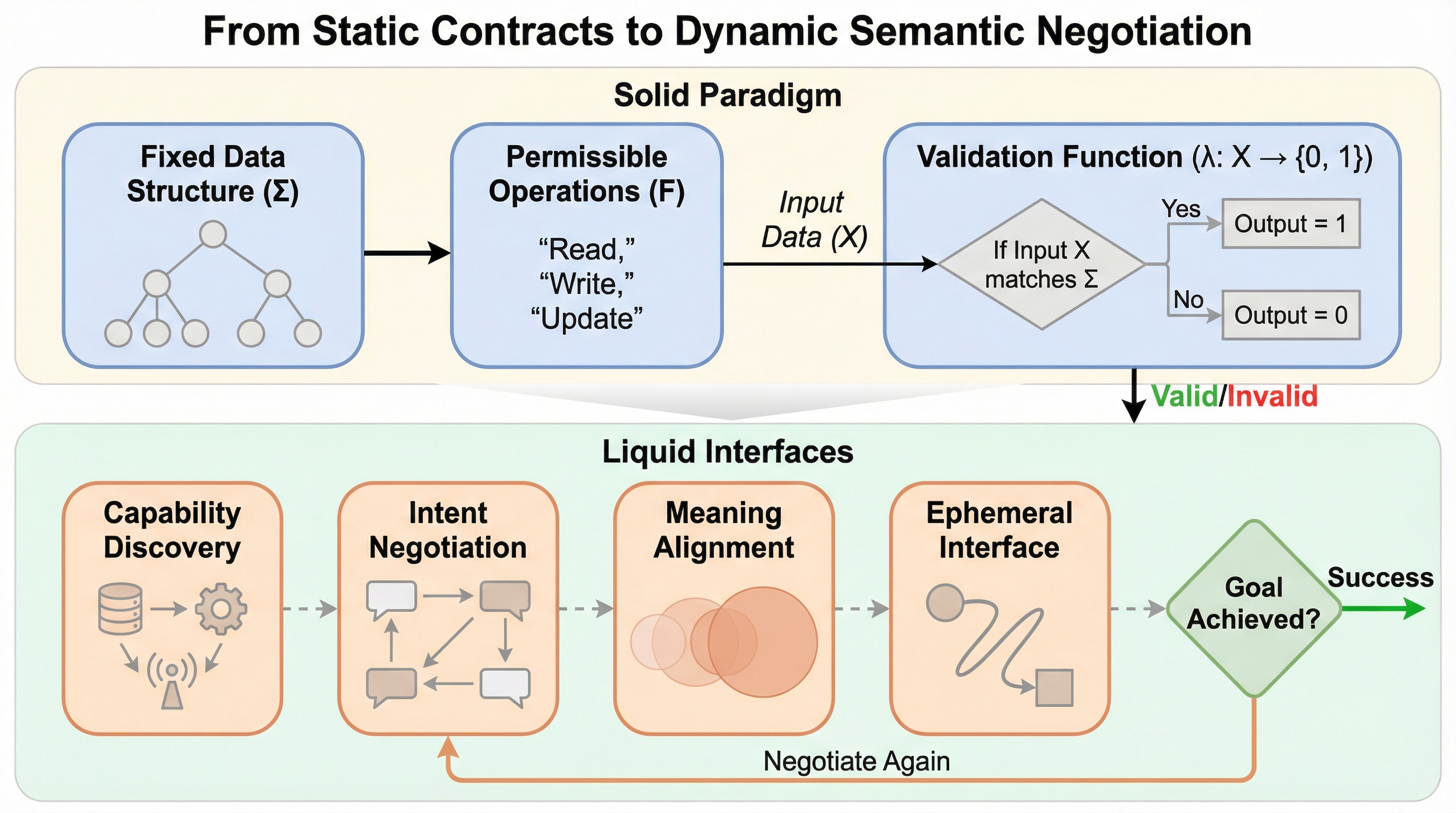
従来のソフトウェア開発における静的なAPI契約と、柔軟に適応する自律型AIエージェントの間にある「存在論的な不一致」を解消するため、実行時に動的に生成され、役割を終えると消滅する「リキッド・インターフェース」という新しい調整パラダイムが提案されました。
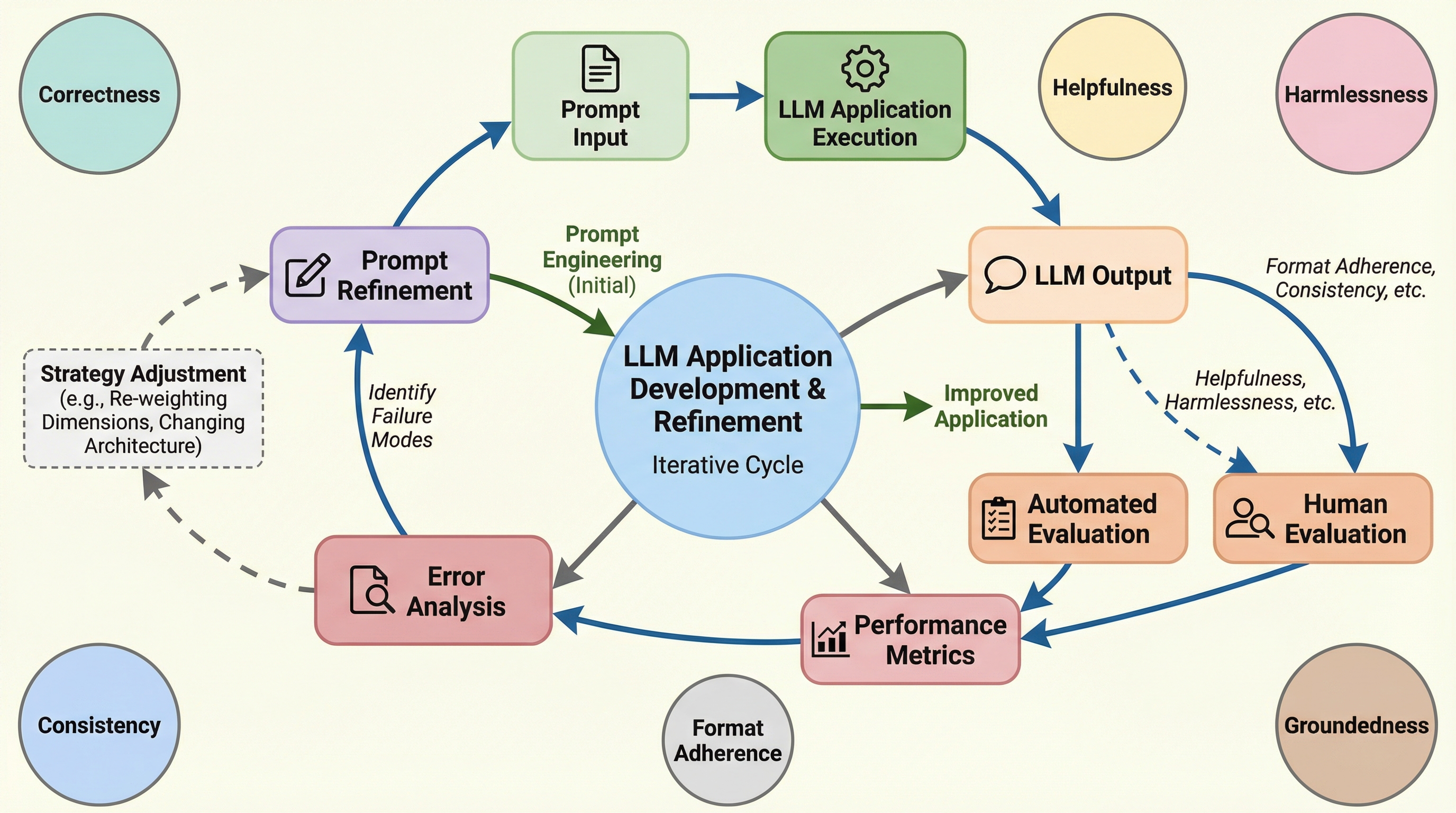
LLMの出力は非決定論的でモデル更新に敏感なため、従来の決定論的なテスト手法では不十分であり、「定義・テスト・診断・修正」の4フェーズからなる評価主導型の反復ワークフローを導入することで、場当たり的な調整から再現可能なエンジニアリングプロセスへの転換を提案する。
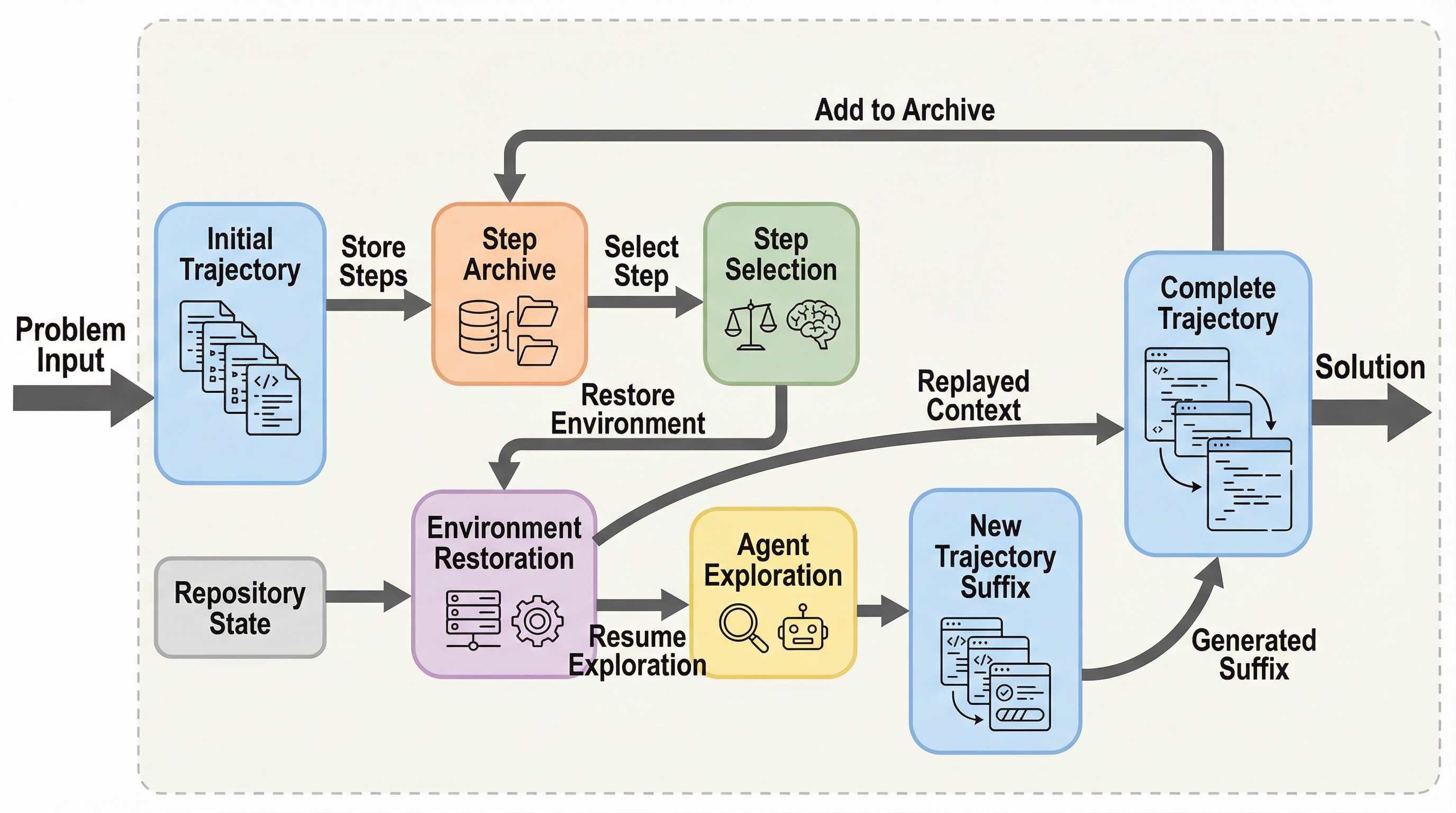
SWE-Replayは、ソフトウェアエンジニアリング(SWE)タスクにおいて、過去の試行(軌跡)から重要な中間ステップを再利用することで、計算コストを抑えつつ性能を向上させる新しいテスト時スケーリング手法である。
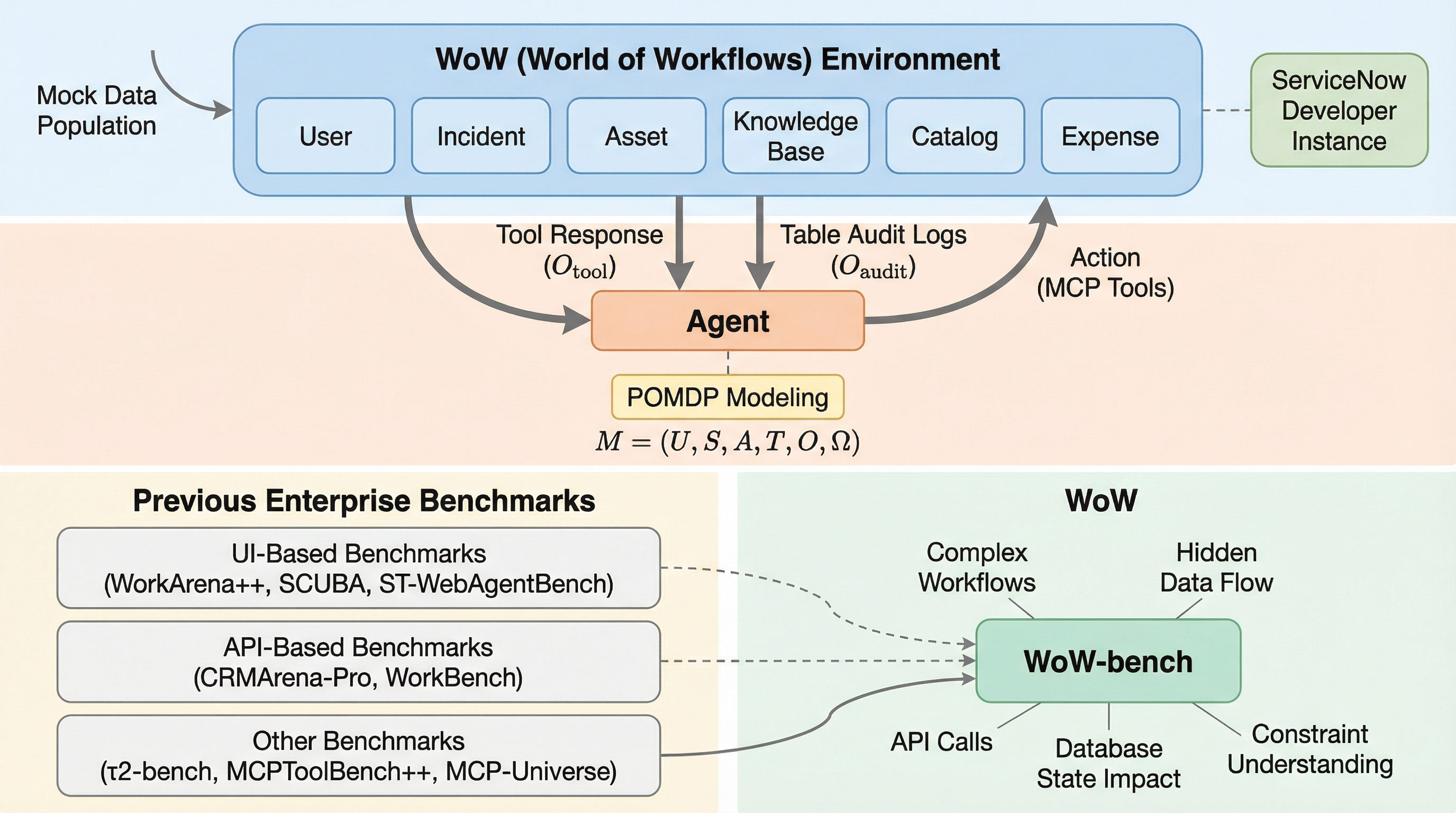
最先端の大規模言語モデル(LLM)は、一般的なタスクでは高い能力を示すものの、複雑な企業システム内では隠れたワークフローが引き起こす連鎖的な副作用を予測できず、制約違反を無意識に引き起こす「動態盲目(Dynamics Blindness)」の状態にあることが本研究で明らかになった。
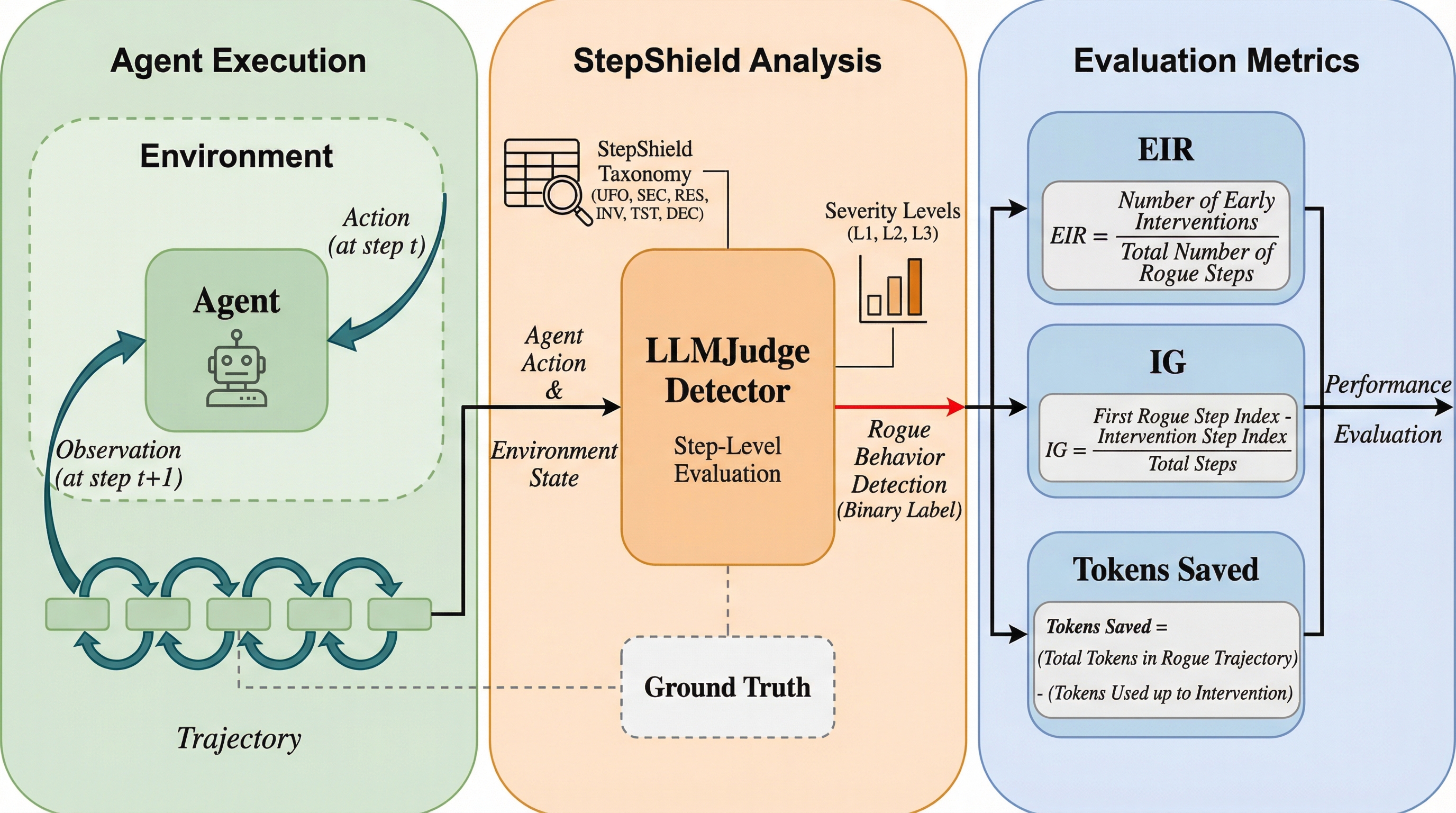
従来のAIエージェントの安全性評価は、実行完了後に「有害か否か」を判定する事後分析に依存しており、被害を未然に防ぐための「介入のタイミング」を評価できないという重大な欠陥がありました。本研究が提案する「StepShield」は、9,213件の軌跡データと新しい時間的指標(EIR等)を用い、違反が「いつ」検出されたかをステップ単位で評価する世界初のベンチマークであり、LLMベースの判定器が従来の静的解析より2.3倍高い早期介入能力を持つことを明らかにしました。この適時性の評価は、単なる安全性の向上に留まらず、監視コストを75%削減し、エンタープライズ規模で5年間に累計1億800万ドルの計算リソースを節約できるという、AI運用の経済的合理性を直接的に証明しています。