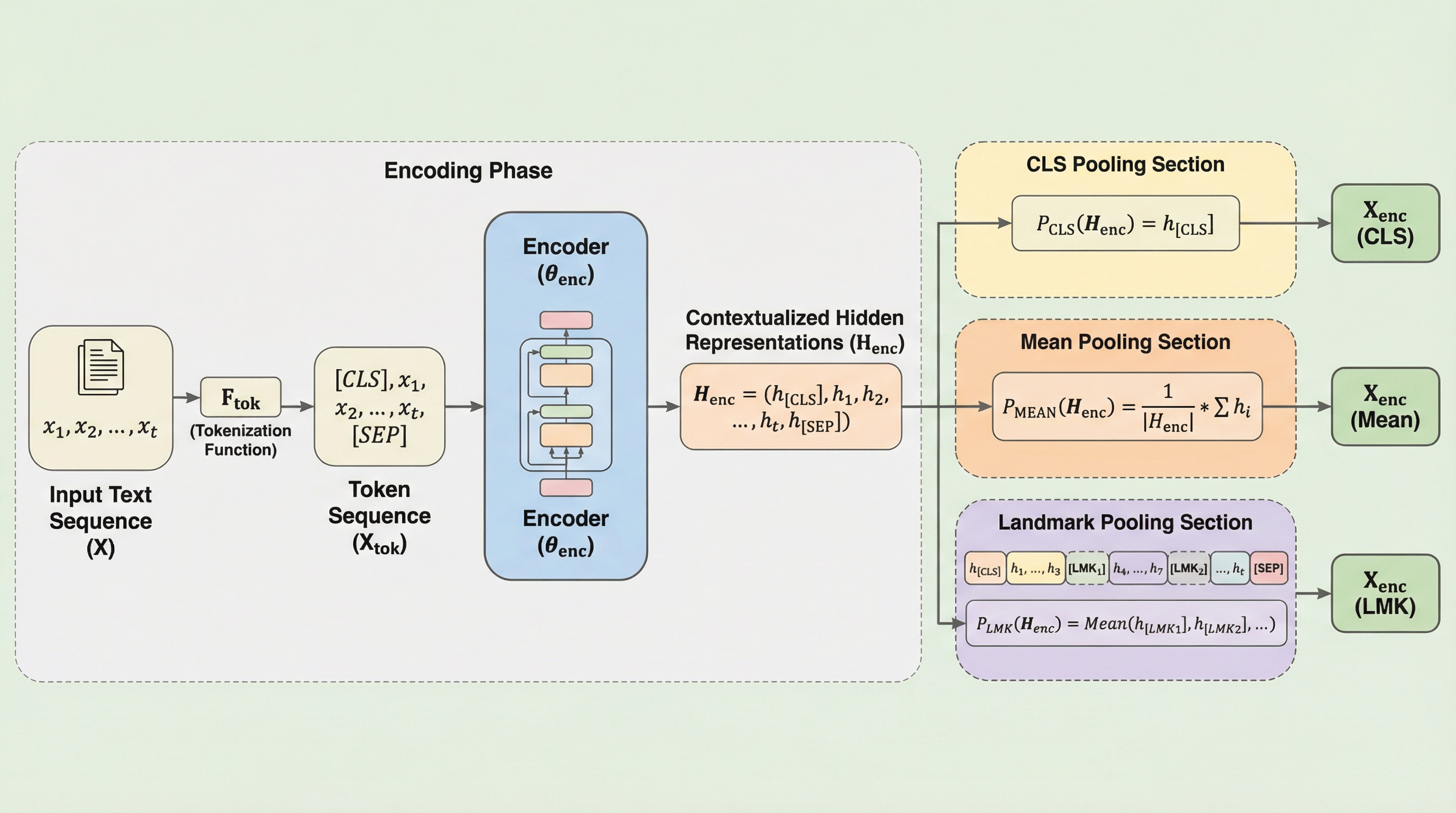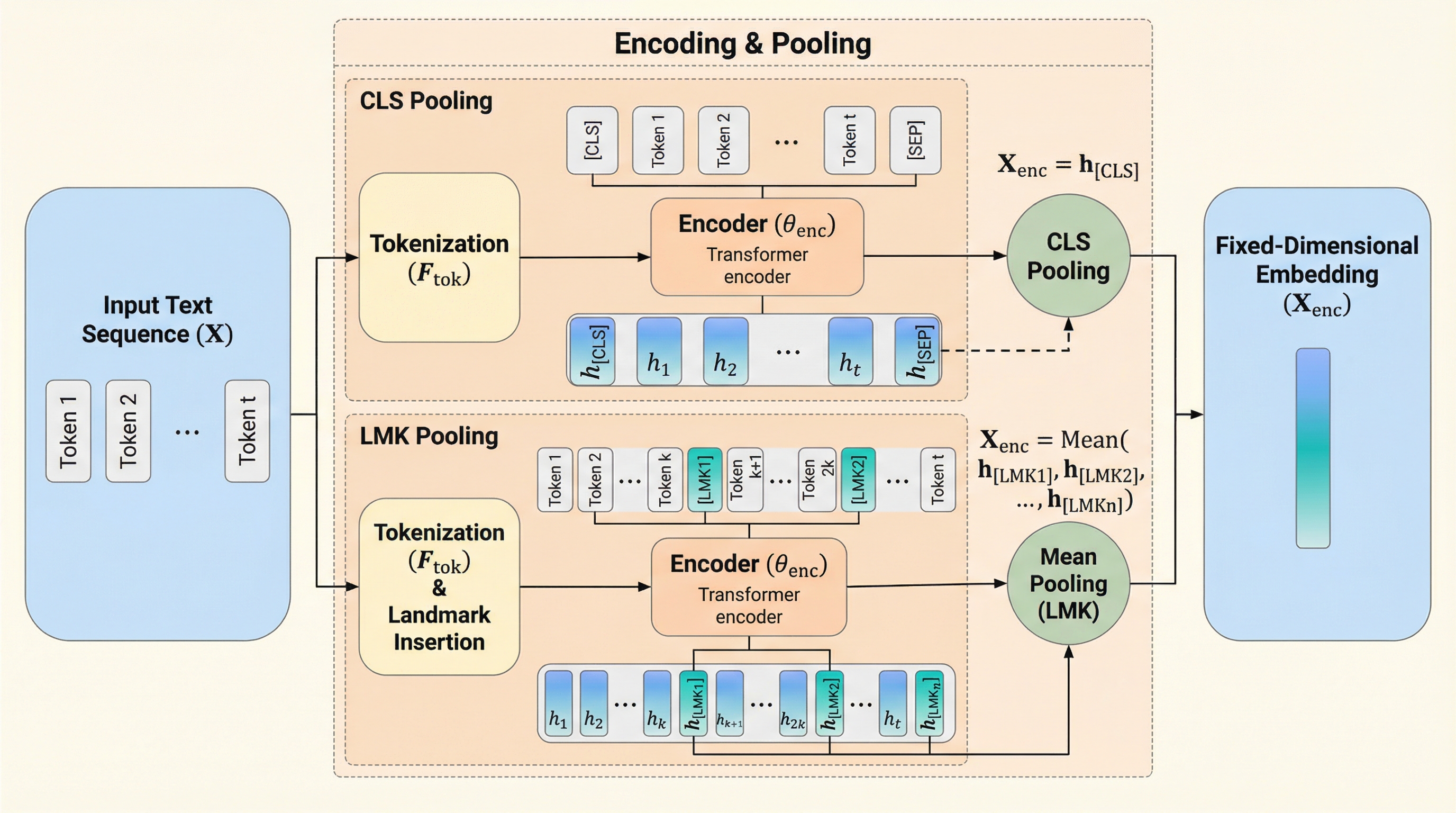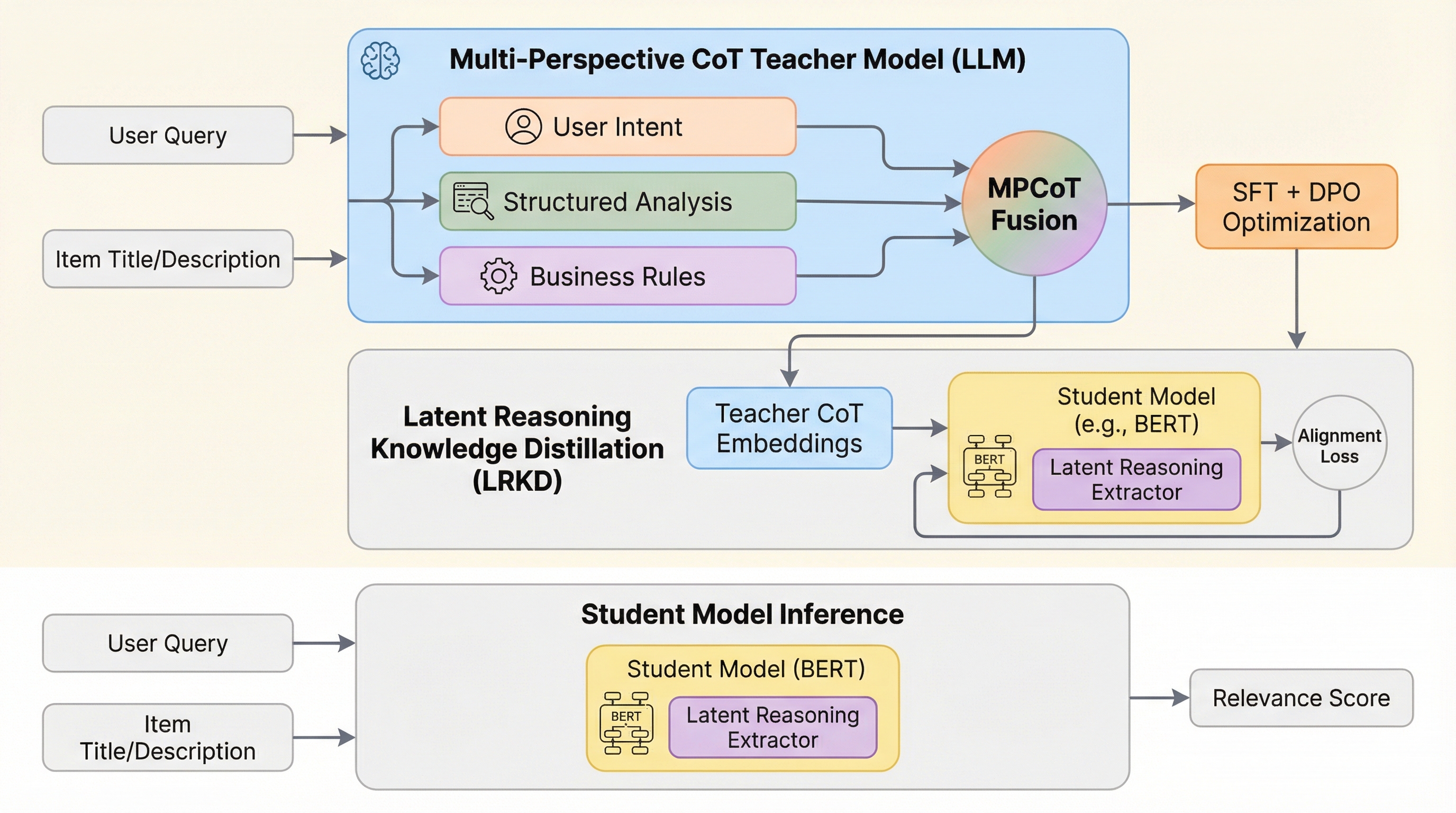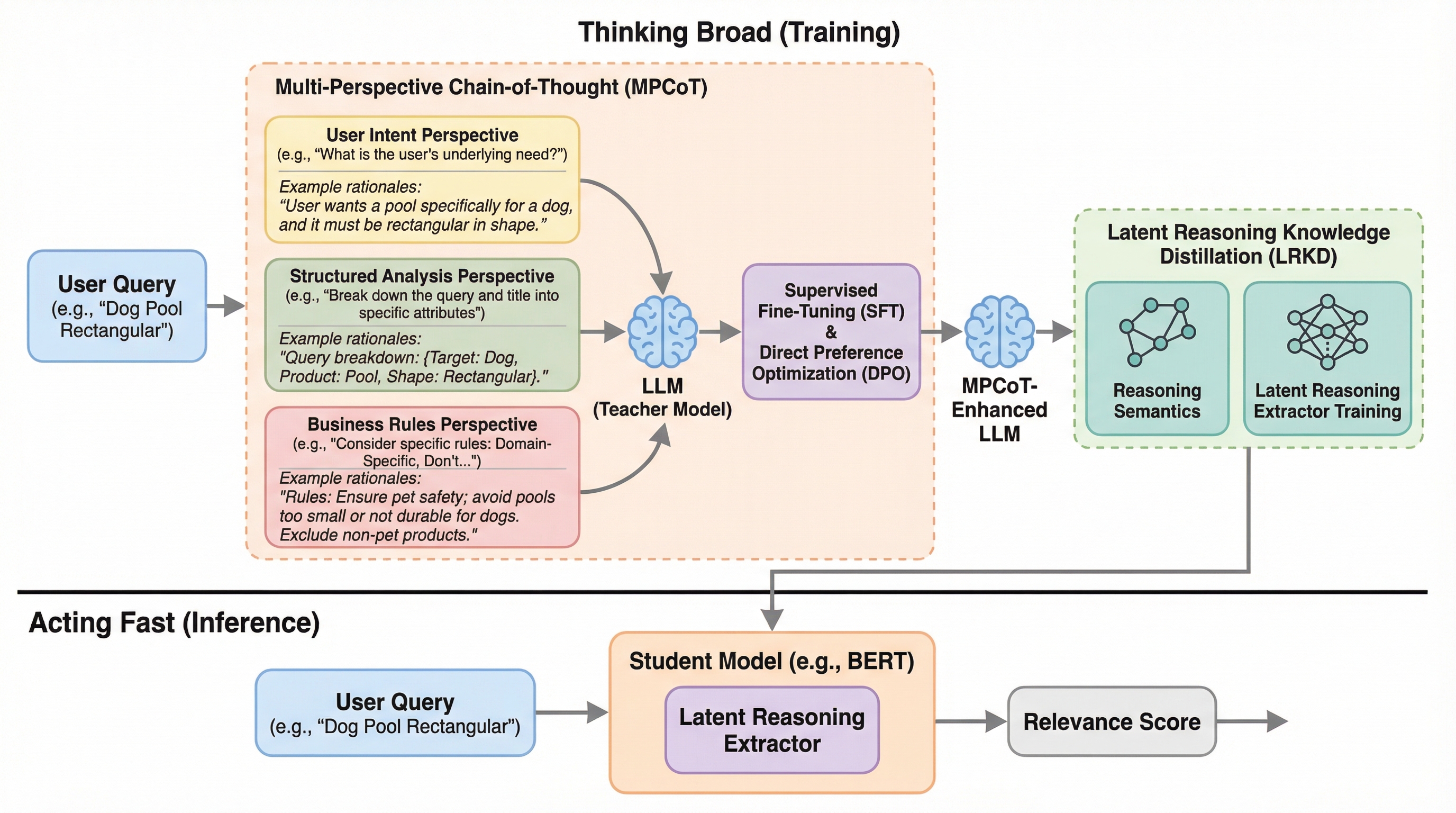
MURAD:大規模マルチドメイン統合アラビア語逆引き辞典データセット
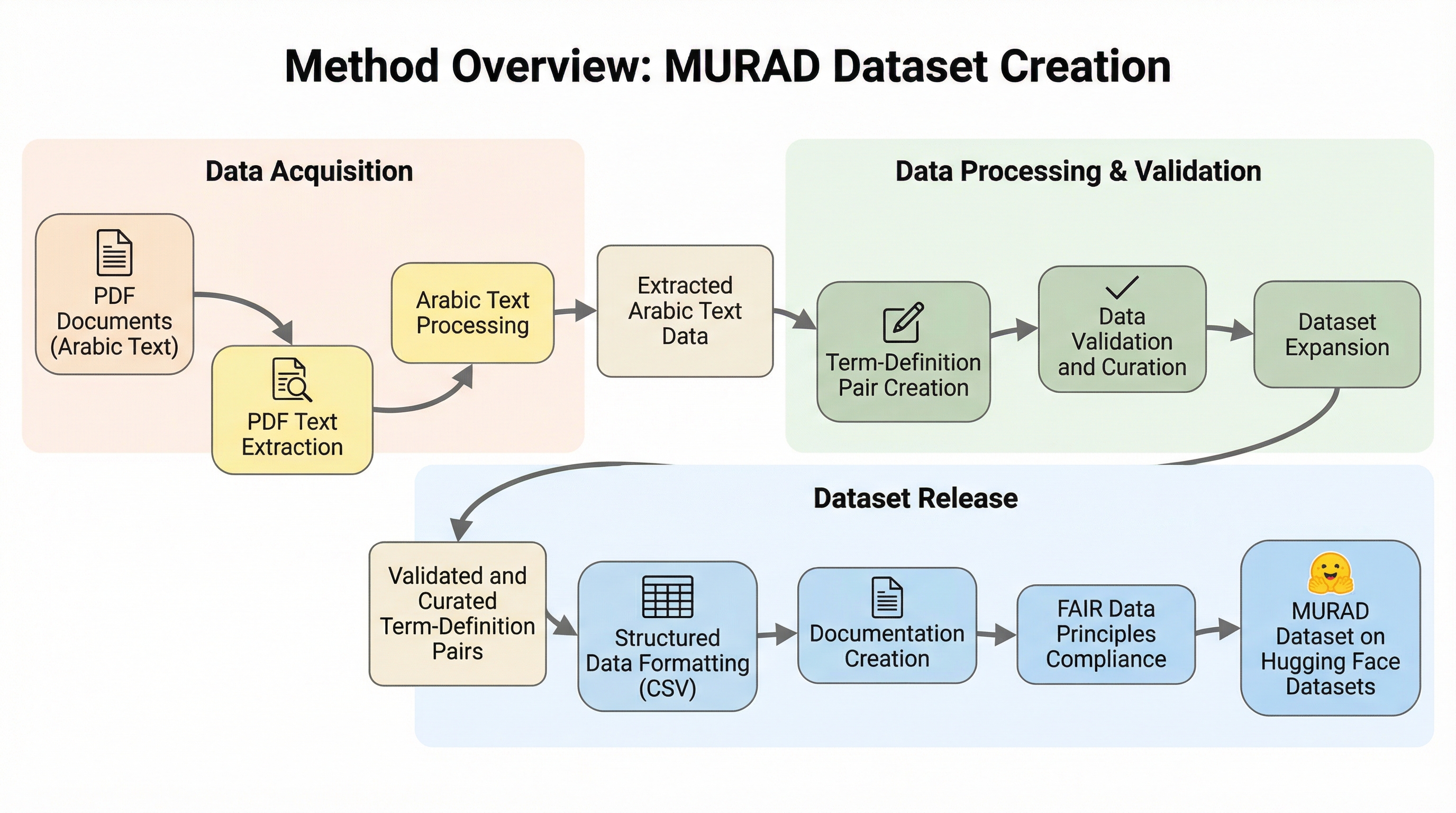
MURADは、アラビア語の語彙と定義を紐付けた96,243組のペアを収録する、大規模でオープンな多領域統合型逆引き辞典データセットです。17の信頼できる出典から構築され、イスラム学、言語学、数学、物理学、工学などの13の専門領域を網羅し、OCRやGPT-4oを活用したハイブリッドなパイプラインによって高い精度と一貫性を確保しています。言葉が思い出せない「舌先現象」の解消や、意味検索、定義生成、埋め込み評価といったアラビア語の自然言語処理研究を促進し、学術的・技術的なコミュニケーションにおける用語の一貫性を支援することを目的としています。