HELM:LLM駆動型推薦システムのための人間中心の評価フレームワーク
大規模言語モデル(LLM)を搭載した推薦システムは、自然言語による対話や詳細な説明生成といった革新的な能力を持つが、従来の的中率やNDCGといった正確性重視の指標では、その人間中心の価値を十分に評価できないという課題がある。
TL;DR(結論)
大規模言語モデル(LLM)を搭載した推薦システムは、自然言語による対話や詳細な説明生成といった革新的な能力を持つが、従来の的中率やNDCGといった正確性重視の指標では、その人間中心の価値を十分に評価できないという課題がある。本研究では、意図の整合性、説明の質、対話の自然さ、信頼性と透明性、公平性と多様性の5つの次元でシステムを多角的に測定する包括的な評価フレームワーク「HELM」を提案し、専門家による厳密な検証を通じてその有効性を実証した。実験の結果、GPT-4などの高性能モデルは説明の質や対話能力で極めて高い評価を得た一方で、従来の協調フィルタリングよりも強い人気バイアスや事実誤認(ハルシネーション)を含むことが判明し、モデルの能力と社会的責任の間の重要なトレードオフが浮き彫りになった。
なぜこの問題か
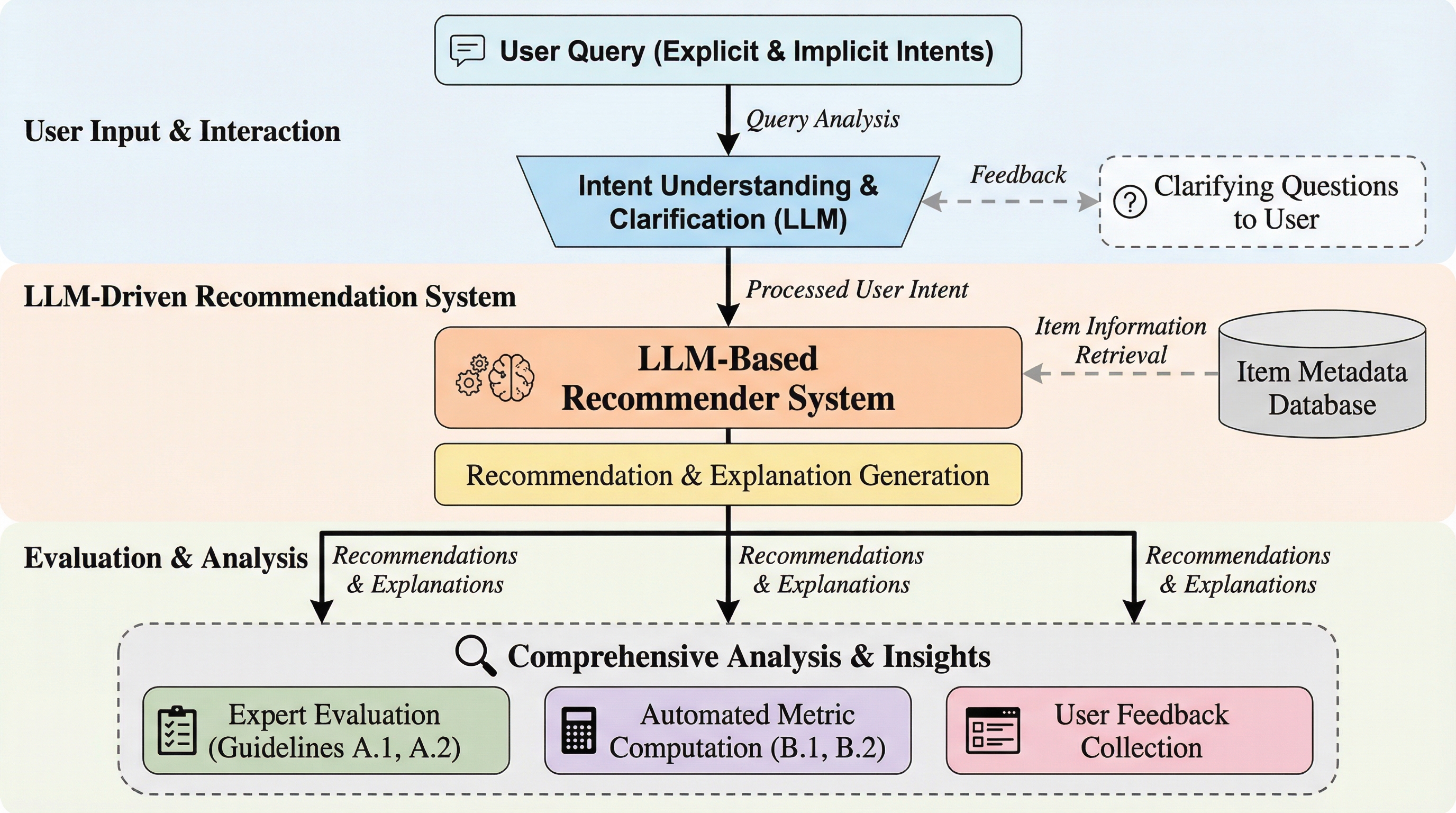
大規模言語モデル(LLM)の登場は、推薦システムの研究に劇的なパラダイムシフトをもたらした。LLMを搭載した推薦システムは、自然言語によるユーザーの好みの抽出、詳細な理由付けを伴う説明の生成、そして流暢な対話によるインタラクションなど、これまでのシステムにはない変革的な能力を備えている。P5やTALLRec、Chat-RECといったシステムは、単一のテキスト生成フレームワーク内で多様な推薦タスクを統合できることを示し、実用的なポテンシャルを証明してきた。しかし、これらのシステムの評価手法は、依然としてヒット率(Hit Rate)やNDCG、平均逆順位(MRR)といった正確性中心の指標に縛られたままである。 これらの伝統的な指標は、LLM駆動型推薦システムを特徴づける人間中心の品質を捉えることが根本的にできていない。例えば、映画の推薦シナリオを考えてみる。従来の協調フィルタリングシステムは、単に人気のある大作映画を勧めることで高いNDCGスコアを獲得するかもしれない。一方で、LLM駆動型システムは、ユーザーが伝えた気分や好みに合致する独立系映画を、なぜそれが最適なのかという思慮深い説明と共に提案することができる。…
核心:何を提案したのか
本研究は、LLM駆動型推薦システムを系統的に評価するための包括的なフレームワーク「HELM(Human-centered Evaluation for LLM-powered recoMmenders)」を提案した。HELMは、人間中心のAI研究と評価方法論に基づいた3つの設計原則に導かれている。第一の原則は「多次元性」であり、ユーザー体験が多面的であることを前提に、単一のスコアでトレードオフを隠さないことを重視している。第二の原則は「妥当性」で、人工的なベンチマークではなく、多様なユーザーの意図を含む自然な推薦対話シナリオを用いて評価を行う。第三の原則は「実行可能性」であり、評価結果がシステムの具体的な改善に繋がるような診断的な指標を提供することを目指している。…
続きはログイン/プランで閲覧できます。
続きを読む
ログインで全文を月 2 本まで無料で読めます
無料プランで全文は月 2 本まで読めます。
Related